Backup timeout - hang or didn't work
-
job still runs for 4 days

Every time it can't write 1 vm backup to 1 of 2 storages. And every time it different vm.
Other jobs works fine with same storage. -
Weird problems continue.
Looks like endless backup fixed now, but it happens for a week after previous update.One VM say it failed about 15 times in row already, but i always have fresh snapshot available.
Same job, same VM every time. Others without errors.
what i supposed to do if XO don't say me what the problem?Tried to disable "Store backup as multiple data blocks instead of a whole VHD file." no difference.
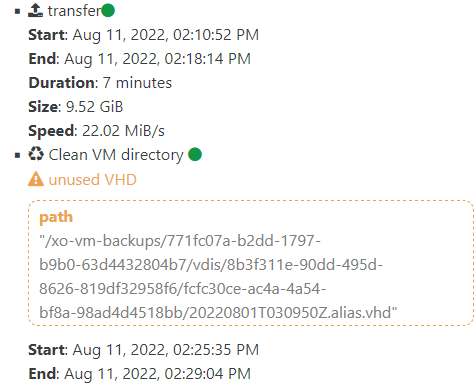
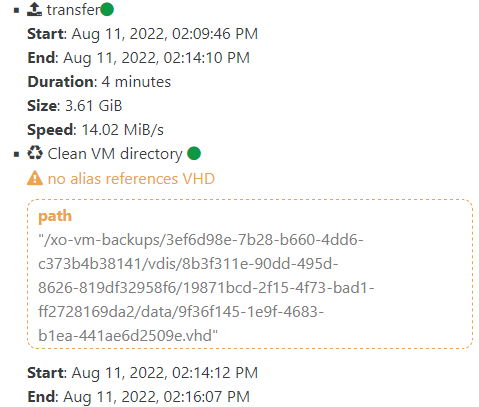
Also what to do with warnings "unused VHD" and others?xo-server 5.100.1
xo-web 5.101.1
commit c1846 -
-
@Tristis-Oris hi,
can you paste the full backup logs (click on the downlod logs button on the top of the popup)
regards
-
@florent
24 hours delta, usualy no problems with it. But 1 VM failed here. Today it still runnig with full. https://pastebin.com/99u0m2QT
4 hours delta, same VM failed for a few days already. https://pastebin.com/nS3HV9VE -
@Tristis-Oris the seond pastbin is private, I can read it
I will look into it this afternoon -
@florent sorry, fixed.
-
@florent any news about?
-
Different jobs stil fail only 1 VM from whole backup. Few times in row, then it happens with another job or VM.
-
After bunch of last commits it looks fixed,
9d09anow. Thanks.
Only 1 vm stuck at this state. I already tried remove backup chain to force the full one, move vdi to maybe fix some merging problem. But that don't help.Also this warnings still here. What to do and how to find them?
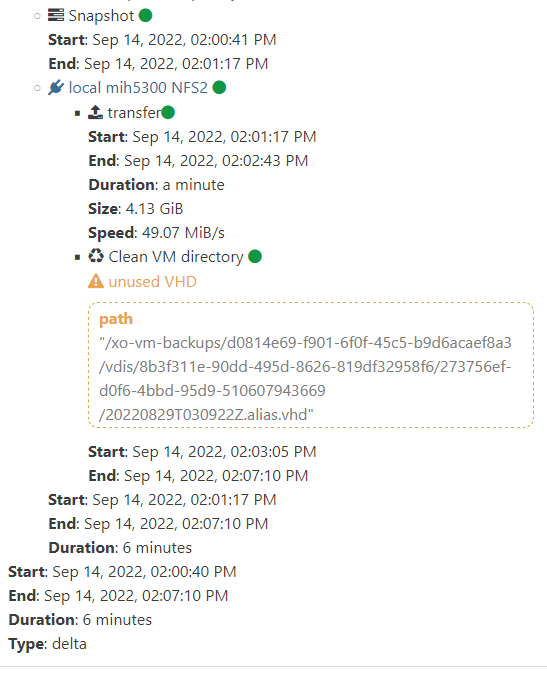
"result": { "errno": -2, "code": "ENOENT", "syscall": "open", "path": "/mnt/mih-5300-2/xo-vm-backups/5fc68102-9705-4918-317d-dff5e4e58237/vdis/90d0b5ca-9364-4011-adc4-b8c74a534da9/d8b005d2-ca6f-4ae5-a3b3-0cb4ef8a3016/data/1f95640b-b699-4dfd-98ea-9398ccc2b685.vhd/blocks/20/0", "syncStack": "Error\n at LocalHandler.addSyncStackTrace [as _addSyncStackTrace] (/opt/xo/xo-builds/xen-orchestra-202209121459/@xen-orchestra/fs/dist/local.js:28:26)\n at LocalHandler._readFile (/opt/xo/xo-builds/xen-orchestra-202209121459/@xen-orchestra/fs/dist/local.js:184:23)\n at LocalHandler.readFile (/opt/xo/xo-builds/xen-orchestra-202209121459/@xen-orchestra/fs/dist/abstract.js:326:29)\n at LocalHandler.readFile (/opt/xo/xo-builds/xen-orchestra-202209121459/node_modules/limit-concurrency-decorator/dist/index.js:107:24)\n at VhdDirectory._readChunk (/opt/xo/xo-builds/xen-orchestra-202209121459/packages/vhd-lib/Vhd/VhdDirectory.js:153:40)\n at VhdDirectory.readBlock (/opt/xo/xo-builds/xen-orchestra-202209121459/packages/vhd-lib/Vhd/VhdDirectory.js:211:35)\n at VhdDirectory.mergeBlock (/opt/xo/xo-builds/xen-orchestra-202209121459/packages/vhd-lib/Vhd/VhdDirectory.js:277:37)\n at async asyncEach.concurrency.concurrency (/opt/xo/xo-builds/xen-orchestra-202209121459/packages/vhd-lib/merge.js:181:38)", "chain": [ "xo-vm-backups/5fc68102-9705-4918-317d-dff5e4e58237/vdis/90d0b5ca-9364-4011-adc4-b8c74a534da9/d8b005d2-ca6f-4ae5-a3b3-0cb4ef8a3016/20220801T221142Z.alias.vhd", "xo-vm-backups/5fc68102-9705-4918-317d-dff5e4e58237/vdis/90d0b5ca-9364-4011-adc4-b8c74a534da9/d8b005d2-ca6f-4ae5-a3b3-0cb4ef8a3016/20220802T221205Z.alias.vhd" ], "message": "ENOENT: no such file or directory, open '/mnt/mih-5300-2/xo-vm-backups/5fc68102-9705-4918-317d-dff5e4e58237/vdis/90d0b5ca-9364-4011-adc4-b8c74a534da9/d8b005d2-ca6f-4ae5-a3b3-0cb4ef8a3016/data/1f95640b-b699-4dfd-98ea-9398ccc2b685.vhd/blocks/20/0'", "name": "Error", "stack": "Error: ENOENT: no such file or directory, open '/mnt/mih-5300-2/xo-vm-backups/5fc68102-9705-4918-317d-dff5e4e58237/vdis/90d0b5ca-9364-4011-adc4-b8c74a534da9/d8b005d2-ca6f-4ae5-a3b3-0cb4ef8a3016/data/1f95640b-b699-4dfd-98ea-9398ccc2b685.vhd/blocks/20/0'" } -
@Tristis-Oris The unused VHD warning are normal after failling snapshot, they happen when a previous backup failed and we are removing the "trash" files.
For the other error did you try to launch the job manually to see if you have the same error? -
@Darkbeldin got it, so it not a problem and no need to do anything.
just started it manually, still error. But shapshot always created, i dont understand why it say failed.
-
@Tristis-Oris @florent will have to take a look at it because i'm not sure.
-
@Tristis-Oris there is a missing block in the backup of 22:11 . Either a failed transfer or a failed merge that can't be resumed securily
Is it the same backups with the error message when you restart it manually ?
-
@florent yes, same error. But im already removed old backup and start new chain.
-
@olivierlambert More and more vms got this bug btw. i think a rotation can be a cause.
a backup log i see
"message": "merge" "message": "ENOENT: no such file or directory, rename "syscall": "rename", "message": "ENOENT: no such file or directory, renameand that still a successful backup, but with fail status. So it can't do something after backup?
After 30 days it should remove old snapshots. But i can't remove them for some vms. when try it - got same error.
ENOENT: no such file or directory, open '/mnt/mih-5300-2/xo-vm-backups/2cac5777-cc11-117a-f107-5027fdf10950/20220608T020201Z.json'Have ~300 old snapshots and can't remove, for a long. Is it the same problem or not?
commit
ce78d -
-
@Tristis-Oris hi tristis , can you show us the full stack trace got the error on rename ?
can you make a healthcheck on the suspicious backups and see if it can restore ?
-
@florent
backup, 4\4 VMs with fail status https://pastebin.com/JxqEp41Q
error on remove old snapshots https://pastebin.com/sukzKCe1
done healthchecks, all failed https://pastebin.com/AnXLJH64Now waiting for restore a copy of one vm.
-
@Tristis-Oris hi,I see two problem :
-
an older merge failed for all theses VM , and some block ae missing ( 2/49 for the fisrt one, 2/52 for the second one) . These backup are irrecuperable and should be deleted
-
there is a desynchro between the cached metadata and the file system, you can delete them by running
find /mnt/mih-5300-2/xo-vm-backups/ -name "cache.json.gz" -type f -delete
-
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login