error -104
-
Wow, that's far from any hint on the error log

Nice catch then.
-
@ptunstall What commands did you run to resolve this issue? I think I'm having the same issue. I "hid" 4 GPUs from dom0, and now I'm getting the -104 error in Xen Orchestra. I used
/opt/xensource/libexec/xen-cmdline –delete-dom0 xen-pciback.hideto try and un-hide the devices from dom0, and usingxl pci-assignable-listwhich still shows one of the GPUs as assignable. Even after removing the GPUs from the server, I'm getting the same result. -
Really hard to tell like this, do you have XAPI running?
-
@olivierlambert It should be, the server was functional prior to the config changes, and has been rebooted multiple times.
-
Check if it runs and take a look at the usual logs
")
-
@olivierlambert XAPI is running. The error in Xen Orchestra is connect ECONNREFUSED [ip address of server:port]. I've verified the ip and credentials to the server.
Restarting the toolstack from the console said it was done, but looking at daemon.log it looks like it's failing to start?
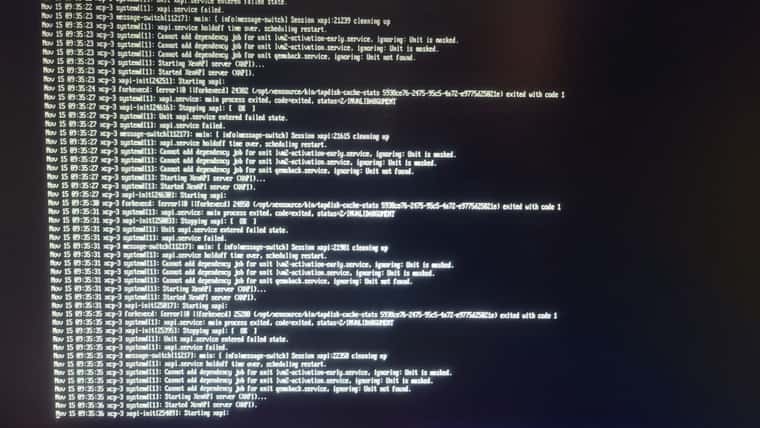
-
I suppose rebooting the host doesn't change anything, right?
-
@olivierlambert Correct. I tried to migrate the 2 VMs off that host to another remote host, but I'm getting the error "This VIF was not mapped to a destination Network in VM.migrate_send operation" or the connection to the server is lost, or "Error: Connection refused (calling connect )", even after restarting the toolstack.
-
While I was able to solve this issue the first time it popped up for us by returning the GPUs back to the DOM, this issue happened again 2 weeks ago for us and I was unable to get it to work again. We had to re-install the HOST entirely to get it to work. I'm sure this is a user error on our part by missing something. I'd very much like to know the proper workflow to solve this as XCP-ng is our backbone to our entire virtual VFX production suite.
We used this command to push the GPUs back to the DOM
/opt/xensource/libexec/xen-cmdline --delete-dom0 xen-pciback.hide -
@wyatt-made - The "INVALIDARGUMENT" is the same error that I've got here
-
@wyatt-made In case anyone in the future comes across this looking for answers: I was able to "resolve" the issue by doing an "upgrade" to the same XCP-ng version using the installation media. This way I was able to preserve any VMs sitting on the hypervisor. This did wipe any kernel settings that were changed as stated in the Compute documentation, but that's the point of the reinstall.
-
We just encountered this again.
I added 2 new GPUs to the node and removed 1 (unused) NIC. Nothing else was changed in the system. Just 3 PCIe changes. The already installed and assigned GPUs were not removed or changed at all, full error:
server.enable { "id": "565d1ea8-582c-4596-ae1f-d96f95ef2c37" } { "errno": -104, "code": "ECONNRESET", "syscall": "write", "url": "https://10.169.4.124/jsonrpc", "call": { "method": "session.login_with_password", "params": "* obfuscated *" }, "message": "write ECONNRESET", "name": "Error", "stack": "Error: write ECONNRESET at WriteWrap.onWriteComplete [as oncomplete] (node:internal/stream_base_commons:94:16) at WriteWrap.callbackTrampoline (node:internal/async_hooks:130:17)" }I can SSH into the node without issue.
I was looking over this: https://xcp-ng.org/docs/api.html
Tried this:
xe-toolstack-restartI get this error now:
server.enable { "id": "88698db1-9b95-4ca8-b690-98395145f282" } { "errno": -111, "code": "ECONNREFUSED", "syscall": "connect", "address": "10.169.4.124", "port": 443, "url": "https://10.169.4.124/jsonrpc", "call": { "method": "session.login_with_password", "params": "* obfuscated *" }, "message": "connect ECONNREFUSED 10.169.4.124:443", "name": "Error", "stack": "Error: connect ECONNREFUSED 10.169.4.124:443 at TCPConnectWrap.afterConnect [as oncomplete] (node:net:1300:16) at TCPConnectWrap.callbackTrampoline (node:internal/async_hooks:130:17)" }I will try this suggested same version upgrade and report back.
-
Additionally I noticed that when SSHed into the node and working with the CLI xe commands some of them don't go through:
[16:19 gpuhost05 ~]# xe vm-list uuid ( RO) : b8e7a3c8-e68e-ac45-2dec-b04b4fc5426b name-label ( RW): vast-ws14 power-state ( RO): halted uuid ( RO) : c6b78b22-1153-4622-a5a1-1a0880b2d68f name-label ( RW): Control domain on host: gpuhost05 power-state ( RO): running [16:19 gpuhost05 ~]# xe vm-list uuid ( RO) : b8e7a3c8-e68e-ac45-2dec-b04b4fc5426b name-label ( RW): vast-ws14 power-state ( RO): halted uuid ( RO) : c6b78b22-1153-4622-a5a1-1a0880b2d68f name-label ( RW): Control domain on host: gpuhost05 power-state ( RO): running [16:19 gpuhost05 ~]# xe vm-list uuid ( RO) : b8e7a3c8-e68e-ac45-2dec-b04b4fc5426b name-label ( RW): vast-ws14 power-state ( RO): halted uuid ( RO) : c6b78b22-1153-4622-a5a1-1a0880b2d68f name-label ( RW): Control domain on host: gpuhost05 power-state ( RO): running [16:19 gpuhost05 ~]# xe vm-list Error: Connection refused (calling connect ) [16:19 gpuhost05 ~]#I try to start a VM manually:
[16:11 gpuhost05 ~]# xe vm-start uuid=b8e7a3c8-e68e-ac45-2dec-b04b4fc5426b Lost connection to the server. [16:12 gpuhost05 ~]# xe vm-start uuid=b8e7a3c8-e68e-ac45-2dec-b04b4fc5426b Lost connection to the server. [16:12 gpuhost05 ~]# xe vm-start uuid=b8e7a3c8-e68e-ac45-2dec-b04b4fc5426b Lost connection to the server. [16:12 gpuhost05 ~]# xe vm-list uuid ( RO) : b8e7a3c8-e68e-ac45-2dec-b04b4fc5426b name-label ( RW): vast-ws14 power-state ( RO): halted uuid ( RO) : c6b78b22-1153-4622-a5a1-1a0880b2d68f name-label ( RW): Control domain on host: gpuhost05 power-state ( RO): running [16:12 gpuhost05 ~]# xe vm-start uuid=b8e7a3c8-e68e-ac45-2dec-b04b4fc5426b Lost connection to the server. -
@wyatt-made said in error -104:
GPU
Do you have the use memory above 4G decoding disabled in the BIOS settings?
-
@tjkreidl Yes, This node had 12GPUs in it running in a bare metal environment a year ago before being repurposed.
-
@tjkreidl I do have that option enabled. This is also passing the entire GPU through to a VM, and using an AMD GPU.
-
@ptunstall when the GPU was pushed back to dom0, did you also remove the PCI address from the VM config?
What's the output of:
xe vm-param-get uuid=<...> param-name=other-config?
-
@tuxen No GPUs were removed. only 2 were added. The only PCIE item removed was a NIC but I didn't remove it from dom0 or assign it to any VMs, it was just in the system.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login