@indyj said in Centos 8 is EOL in 2021, what will xcp-ng do?:
@jefftee I prefer Alpine Linux.

+1
Low resource footprint, no bloatware... They even have a pre-built Xen Hypervisor ISO flavor ")
@indyj said in Centos 8 is EOL in 2021, what will xcp-ng do?:
@jefftee I prefer Alpine Linux.
+1
Low resource footprint, no bloatware... They even have a pre-built Xen Hypervisor ISO flavor
@jshiells Did you also check /var/log/kern.log for hardware errors? I'm seeing qemu process crashing with bad RIP (Instruction pointer) value which screams for a hardware issue, IMO. Just a 1-bit flipping in memory is enough to cause unpleasant surprises. I hope the servers are using ECC memory. I'd run a memtest and some CPU stress test on that server.
Some years ago, I had a two-socket Dell server with one bad core (no errors reported at boot). When the Xen scheduler ran a task on that core... Boom. Host crash.
@steff22 Wow, great news! Kudos to the Xen & XCP-ng dev teams 
@cunrun @jorge-gbs any init errors in dom0 /var/log/kern.log re. GIM driver? Also, if you search some topics here covering this specific GPU, there were mixed results booting dom0 with pci=realloc,assign-busses. Maybe it worth a try.
I liked as well. Easy to find the topics and good layout 
@olivierlambert congrats to the team and also to this great community!
@sasha It's worth notice that the BIOS (from 2019) is relatively old/outdated. It's recommended to update the BIOS to a more recent version.
@fred974 Yep, see the docs about NUMA/core affinity (soft/hard pinning):
@Forza Take a look:
https://xcp-ng.org/forum/post/49400
At the time of this topic, I remember asking a coworker to boot a CentOS 7.9 with more than 64 vcpus on a 48C/96T Xeon server. The VM started normally, but it didn't recognizes the vcpus > 64.
I've not tested that VM param platform:acpi=0 as a possible solution and the trade-offs. In the past, some old RHEL 5.x VMs without acpi support would simply power off (like pulling the power cord) instead of a clean shutdown on a vm-shutdown command.
Regarding that CFD software, does it support a worker/farm design? vGPU offload? I'm not a HPC expert but considering the EPYC MCM architecture, instead of a big VM, spreading the workload across many workers pinned to each CCD (or each numa nodes on a NPS4 confg) may be interesting.
Before buying those monsters, I would ask AMD to deploy a PoC using the target server model. For such demands, it's very important to do some sort of certification/validation.
@EddieA Looking at the original crash report, it could be the MWAIT instruction bug that some Intel CPUs have. For troubleshooting purposes, apply this Xen boot option:
/opt/xensource/libexec/xen-cmdline --set-xen mwait-idle=false
After that, try some reboots/power cycles and let's see if you can reproduce the issue.
@sotero could you post the output of:
# Collect xen info
xl info
# Collect C-States info
xenpm start 3
?
/opt/xensource/libexec/xen-cmdline --set-dom0 "pcie_port_pm=off"
reboot
As an another option, you can also test the pcie_aspm=off that we did before for the Nvidia GPU (edit: added the command to remove the pcie_port_pm):
/opt/xensource/libexec/xen-cmdline --delete-dom0 "pcie_port_pm"
/opt/xensource/libexec/xen-cmdline --set-dom0 "pcie_aspm=off"
reboot
Tux
@steff22 I'm seeing that this new card has large BAR. Could you disable in the BIOS:
Tux
@steff22 said in Gpu passthrough on Asrock rack B650D4U3-2L2Q will not work:
03:00.0 VGA compatible controller: Advanced Micro Devices, Inc. [AMD/ATI] Navi 32 [Radeon RX 7700 XT / 7800 XT] (rev ff) (prog-if ff)
!!! Unknown header type 7f
Kernel driver in use: pciback03:00.1 Audio device: Advanced Micro Devices, Inc. [AMD/ATI] Navi 31 HDMI/DP Audio (rev ff) (prog-if ff)
!!! Unknown header type 7f
Kernel driver in use: pciback
Something went wrong with the card detection. Since it's a big file, instead of posting, could you upload (last button) /var/log/kern.log ?
Searching around some old forums with this error, it's said that if the system has the AMD iGPU + AMD dGPU combo, the iGPU takes precedence and power down the dGPU. Verify in the BIOS (under Advanced > AMD PBS > Graphics or something like that) if there's any configuration regarding this hybrid mode.
Those last messages you posted are normal (guest net and disk infos).
Tux
FYI, Xen has a registered OUI: 00:16:3E
edit: I didn't read @olivierlambert previous post mentioning the OUI ")
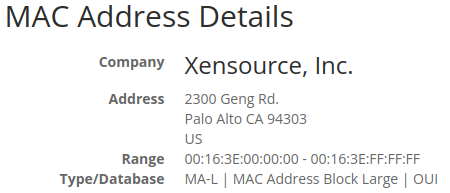
Source: https://www.macvendorlookup.com
@steff22 Any change via grub menu is non-persistent and will be reverted in the next (re)boot. It's useful for testing/troubleshooting purposes.
Regarding dom0 memory increasing, it was a simple boot test to verify possible lack of the resource. Given that IOMMU compat fix, I'd keep the default value for now.
For the new AMD dGPU failing, any PCI error in dom0 /var/log/kern.log? Post the output of lspci -k -v .
Tux
@steff22 Wow, great news! Kudos to the Xen & XCP-ng dev teams
@steff22 said in Gpu passthrough on Asrock rack B650D4U3-2L2Q will not work:
The bios disabled internal ipma when an Ext GPU card is connected even though int gpu is selected as primary gpu in the bios. So I only see xcp-ng startup on screen no xsconsole. Have tried without a screen connected extgpu same error then
I suggest to call the Asrock support and explain this behavior.
@steff22 said in Gpu passthrough on Asrock rack B650D4U3-2L2Q will not work:
no. 2 Have tried pressing Detect only to be told that there is no more screen. Have only tried reboot
Could you try the shutdown/start after the driver installation?
@steff22 said in Gpu passthrough on Asrock rack B650D4U3-2L2Q will not work:
At first I thought there was something wrong with the bios. But this works with Vmware esxi and proxmox.
Considering it worked with the same XCP-ng version, but on a different hardware, that's why I'm more inclined to a Xen incompatibility issue with the combo Nvidia + some AMD motherboards. If you search the forum, there's a mixed result about that.
@steff22 I have some questions:
[Detect] button at the display settings window?Nonetheless, if the same dGPU card works normally on another XCP-ng host, a possible Xen passthrough incompatibility with that AM5 board should be considered. For example:
Tux