Epyc VM to VM networking slow
-
@bleader I stumpled upon this thread and this issue kept me wondering so I did a quick test on our systems:
Running iperf3 on ou HP's with AMD EPYC 7543P cpu's, debian12 to debian12 vm I get
iperf3 -c 192.168.1.19 -P 10

iperf3 -c 192.168.1.19

Same on a HP with Intel Xeon E5-2667
iperf3 -c 192.168.1.113 -P 10

iperf3 -c 192.168.1.113

FREAKY!
Doesn't affect us because we don't have inter-VM traffic to speak off.
-
@manilx thanks for the additional results, and yes, it is a pretty big issue, but even with multiple people looking at it or trying to help out, we were not able to pinpoint the root cause yet

-
This is over 4 months old, and is affecting a LOT of my customers.
It is a BIG problem for my company.Is there anything that we can do to help resolve this?
-
@nicols Hello, you are not alone in this. We have delayed the deployment of our core ISP routing as virtual routers due to this.
We have an XOA premium and xcp-ng enterprise subscription and an open case on this.
I cannot go into detail about what is being said in there but i can say that the approach @olivierlambert and vates have is very good and they have my full confidence on this one.
@manilx i can say this affects all vm traffic as we have vm out to switch over to a second hardware host into a VM there and we see the limit there aswell just the roof is twice as high as inside the same HW box
Either way. Vates is VERY well aware of how serious this is and are taking good efforts to fix it.
-
@Seneram True. Just tested 2 debian12 sitting on 2 EPYC host:
10 parallel tests:

One:

Bummer! Worse than I thought. But Vates will certainly get to the bottom of this.
-
Just for additional insights, have tests been made with different BIOS/firmware settings? Especially EPYC firmware has a lot of settings affecting internal latency vs throughput for different workloads. I recently deployed an EPYC 2x48c/96t system for a simulation software. The changes in the firmware could make 20% difference in rendering time for this application. Not saying it is a root cause, but it could possibly improve the situation here. My guess is that much of the issue is due to bad latency and erroneous scheduling leading to additional latency.
-
@Forza We have tried all the settings avail to tweak on our hardware, We have a full big twin chassi we have dedicated to vates doing testing of this issue and the first roughly month was spent going over settings together with vates and making sure everything was tweaked properly.
AMD is involved themself and if anyone knows AMD firmware settings and tweaking it would be AMD.
In all seriousness it is a very good suggestion but it has been looked into and unfortunately do minimal or no difference.
-
@Seneram thanks, was guessing it was the case. I hope the issue is resolved soon.

-
Please note that we are actively investigating to it, and believe me it's costly (25k€ already invested to track this down). So as you can see, it's a priority and something we are actively working on. AMD is also aware of it.
-
@bleader Had some time to test this on an AMD system (HP T740 Thin Client). Hopefully it helps a bit, even it is not an Epyc CPU.
Host:
- CPU: AMD Ryzen Embedded V1756B
- Number of sockets: 1
- CPU pinning: no
- XCP-NG version: 8.3 beta 1 (updated with
yum updateas of today) - Output of xl info -n:
[22:05 hpt740 ~]# xl info -n host : hpt740 release : 4.19.0+1 version : #1 SMP Wed Jan 24 17:19:11 CET 2024 machine : x86_64 nr_cpus : 8 max_cpu_id : 15 nr_nodes : 1 cores_per_socket : 4 threads_per_core : 2 cpu_mhz : 3244.038 hw_caps : 178bf3ff:7ed8320b:2e500800:244033ff:0000000f:209c01a9:00000000:00000500 virt_caps : pv hvm hvm_directio pv_directio hap shadow total_memory : 30636 free_memory : 17610 sharing_freed_memory : 0 sharing_used_memory : 0 outstanding_claims : 0 free_cpus : 0 cpu_topology : cpu: core socket node 0: 0 0 0 1: 0 0 0 2: 1 0 0 3: 1 0 0 4: 2 0 0 5: 2 0 0 6: 3 0 0 7: 3 0 0 device topology : device node No device topology data available numa_info : node: memsize memfree distances 0: 34803 17610 10 xen_major : 4 xen_minor : 13 xen_extra : .5-10.58 xen_version : 4.13.5-10.58 xen_caps : xen-3.0-x86_64 hvm-3.0-x86_32 hvm-3.0-x86_32p hvm-3.0-x86_64 xen_scheduler : credit xen_pagesize : 4096 platform_params : virt_start=0xffff800000000000 xen_changeset : 708e83f0e7d1, pq 8e58b4872724 xen_commandline : watchdog ucode=scan dom0_max_vcpus=1-8 crashkernel=256M,below=4G console=vga vga=mode-0x0311 dom0_mem=4294967296B,max:4294967296B cc_compiler : gcc (GCC) 11.2.1 20210728 (Red Hat 11.2.1-1) cc_compile_by : mockbuild cc_compile_domain : [unknown] cc_compile_date : Thu Jan 25 10:20:16 CET 2024 build_id : ae0904d024e04d4daf2ecdfddc37ea146f48d7e1 xend_config_format : 4Server and client VMs are both Debian 12 (Linux 6.1.0-18-amd64) with 4 cores and 4G RAM.
xentopisclient/server/dom0V2V 1T 90/140/210 5.1 Gbits/sec V2V 4T 150/220/260 8.1 Gbits/sec H2V 1T 0/170/210 10.2 Gbits/sec* H2V 4T 0/310/340 11.9 Gbits/sec* *: with some spread of cpu utilization and throughputMinimum of three runs per test scenario.
-
We made tests on Ryzen CPUs and we couldn't really reproduce the problem: it seems to be EPYC specific.
-
@olivierlambert We did talk in DM before, I told him any data is always welcome, especially as I didn't even know this range of CPUs
")
-
@gskger It does seem quite lower than the 5950x and the 7600 we tested, but:
- it is a zen1 if I'm not mistaken
- in the 4 threads case, with 8 threads on the physical CPU, the VMs and dom0 are actually sharing ressources
- for single thread I guess the generation and memory speed could explain the difference.
I would say that this confirms these ryzen cpus are not really impacted either.
Thanks for sharing, I'll update the table tomorrow.
-
@bleader you are correct, the V1756B is a low power (45W TDP) desktop CPU of the AMD Ryzen embedded v1000 series based on the ZEN microarchitecture with 4 cores and 8 threads. It operates at a base freqeuncy of 3.25 GHz and a boost frequency of 3.6 GHz max. The HP T740 thin client is a capable low power, low noise computer for running XCP-ng in a homelab, but it's not a real match for serious AMD desktop or server CPUs.
-
@gskger Returning to this:
Our backups on our business deployment, 2 HPE, (,ProLiant DL325 Gen10 Plus v2,) with AMD EPYC 7543P 32-Core Processor connected via redundant 10G nic's and switched to 10G NAS (QNAP, Synology) for storage and backups we get backup speeds of 80-90MiB/s tops with NBP.
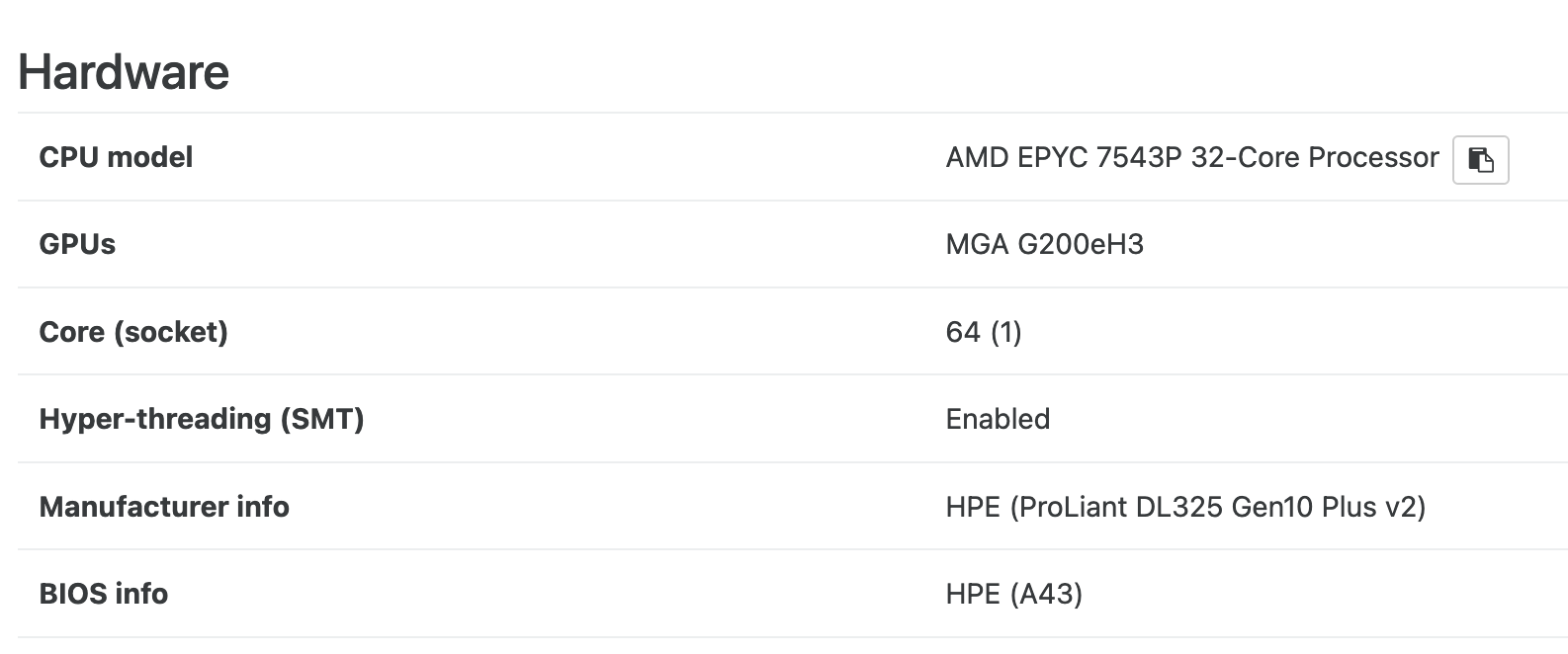

On my Homelab with Protectli Mini PC connected via 10G also to 10G QNAP I get 250-300 MiB/s !!!!!!


This really is a problem for us now since we started with XCPNG 1 yr ago. Slow backup/restore speeds are a hindrance in our backup strategy.
Now that I switched my Homelab from Proxmox (using it for 3yrs) to XCPNG I stumbled upn this speed difference and it is incredible.
I wonder if it is not also related to this issue with EPYC networking.
P.S: I have opened a ticket BUT I wanted ti share this here also.
-
@manilx hi, I am working on the backup side, that is a very interesting finding. I have some question to rule out some hypothesis :
What storage do you use on both side ? iscsi / nfs ?
Is XO running on the master ? -
@bleader do you remember if we also had slower network speed between a VM and the Dom0 or only between 2 regular guests?
-
-
Not necessarily. XOA is a VM, but it's communicating with the Dom0, which is a VM indeed, but not a regular one. Could have been interesting to check if XOA VM is not sitting on the same host it's doing a backup, to see the result.
-
@olivierlambert vm to host is impacted too, althrough less, reaching over 10Gbps on a zen2 epyc.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login