Updated XOA with kernel >5.3 to support nconnect nfs option
-
Hi,
Are there any plans to release a new XOA based on kernel >=5.3 so that we can use thenconnectnfs mount option. The nconnect option increases NFS performance by utilising multiple connections to the same remote.https://medium.com/@emilypotyraj/use-nconnect-to-effortlessly-increase-nfs-performance-4ceb46c64089
-
XOA is based on Debian 12. I'm not against doing a custom kernel if it's really a big bonus in terms of performance
")
-
@olivierlambert said in Updated XOA with kernel >5.3 to support nconnect nfs option:
XOA is based on Debian 12. I'm not against doing a custom kernel if it's really a big bonus in terms of performance
Debian 12 should use kernel 6.1, so that would be ok. Maybe I am having an old XOA as my kernel is 4.19. This is what shows when I login:
login as: xoa xoa@<redacted>'s password: Linux <redacted> 4.19.0-13-amd64 #1 SMP Debian 4.19.160-2 (2020-11-28) x86_64 __ __ ____ _ _ \ \ / / / __ \ | | | | \ V / ___ _ __ | | | |_ __ ___| |__ ___ ___| |_ _ __ __ _ > < / _ \ '_ \ | | | | '__/ __| '_ \ / _ \/ __| __| '__/ _` | / . \ __/ | | | | |__| | | | (__| | | | __/\__ \ |_| | | (_| | /_/ \_\___|_| |_| \____/|_| \___|_| |_|\___||___/\__|_| \__,_| Welcome to XOA Unified Edition, with Pro Support. * Restart XO: sudo systemctl restart xo-server.service * Display status: sudo systemctl status xo-server.service * Display logs: sudo journalctl -u xo-server.service * Register your XOA: sudo xoa-updater --register * Update your XOA: sudo xoa-updater --upgrade OFFICIAL XOA DOCUMENTATION HERE: https://xen-orchestra.com/docs/xoa.html Support available at https://xen-orchestra.com/#!/member/support In case of issues, use `xoa check` for a quick health check. Build number: 21.01.02 Based on Debian GNU/Linux 10 (Stable) 64bits in PVHVM mode -
Your XOA is old, you can deploy a new one and do a compare by mounting the backup repo with and without the option.
-
I will do.
It would be nice to have an notice that a new XOA is available, in addition to the normal updates. Perhaps something on the https://xoa/#/xoa/support page?
-
We notified that when it happened in our release blog post, which we advertise every month via our XO newsletter. See https://xen-orchestra.com/blog/xen-orchestra-5-92/#🪐-new-xoa for more details
-
I usually read the blog posts, but I must have missed it that time.
As for performance it is a little difficult to test i a structured manner, but the initial incremental backup seems to run very well. Normally I have about 60-90MB/s as max before, but also often around 20-30MB/s. This time the backup took 6 minutes, and normal is around 15 minutes. This is over a 1 Gbit/s network.
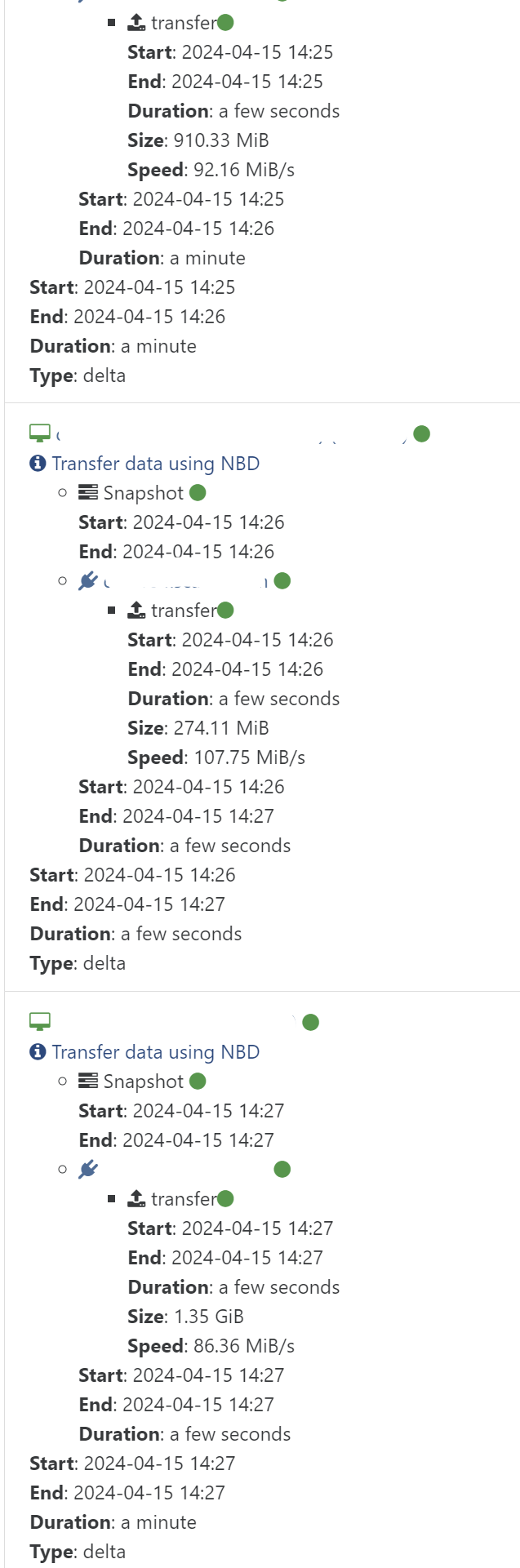
-
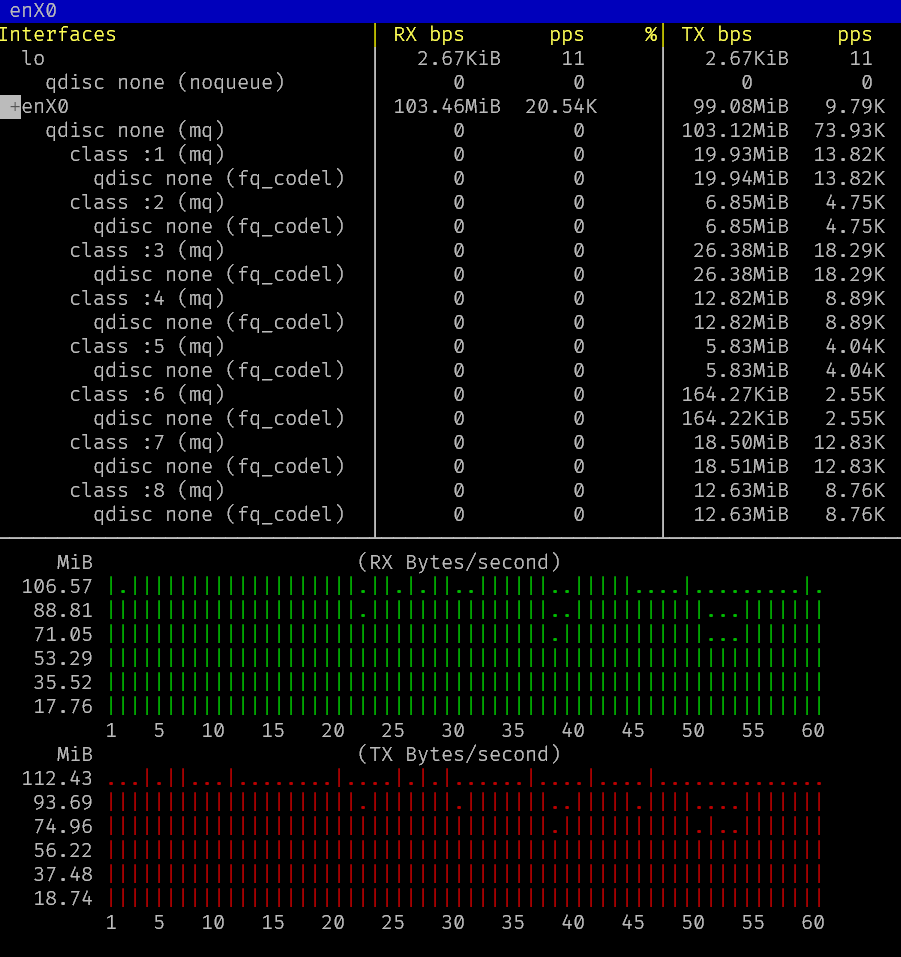
Testing full backups. Seems at least XOA is saturating the link for larger VMs. It does have quite a bit of delay outside of the transfer itself, so the overall BW that is logged in the web interface is lower.
This is
bmonrunning inside XOA.
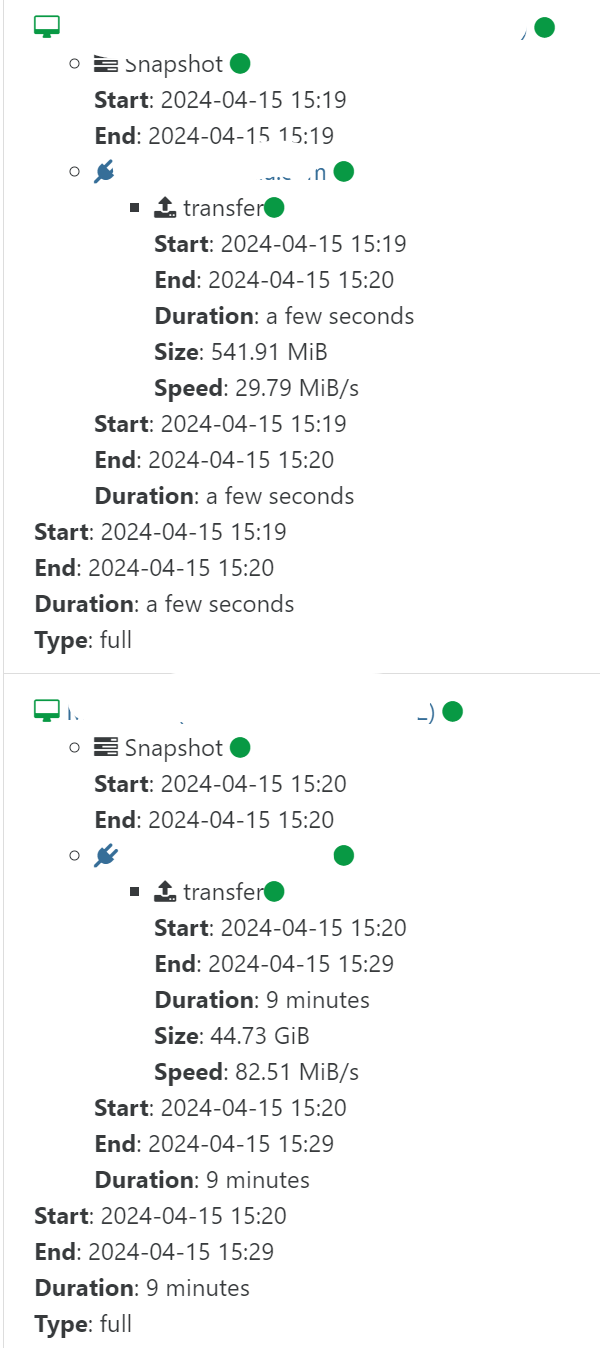
-
That's interesting
Are you checking the speed via in XO graphs on the XOA VM? -
@olivierlambert
Yes, I am checking on the XOA VM itself.Here is a view over the XOA VM. You can see that the full backup was started around 3:10 pm:
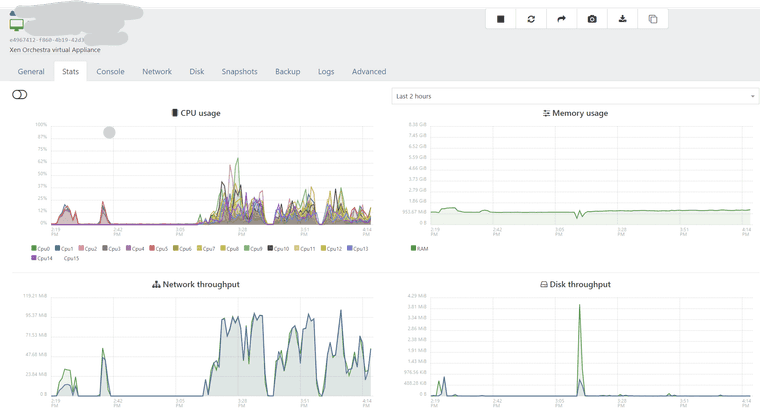
This is the NFS stats from the backup server (Remote) for the same period:
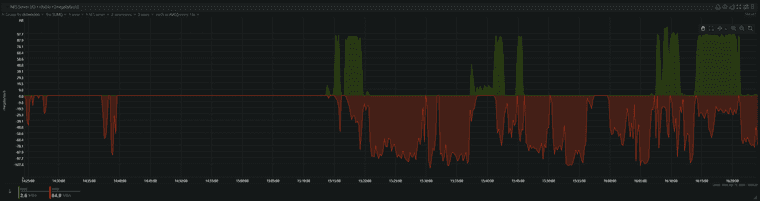
Why is the server doing reads? Maybe coalesce? But is there coalesce on full backups?
-
Thanks for the stats
About the read, yes, it's all the workers coalescing the chain on the BR -
That would explain why the transfer rate is uneven, as some bandwidth and IO is used by the coalescing processes.
Overall the transfer is somewhat faster. about 1.5 hours for 253GiB on 1Gbit/s connection. Before it was maybe 2ish hours.
I lost the backup logs in XOA since I switched to the new version, but looking back in the Netdata stats from the backup server we can see the following pattern for the previous run of the same backup job. Just looking at the timestamps it looks pretty similar, while the bandwidth used looks less. Maybe some rounding errors in Netdata graphs?

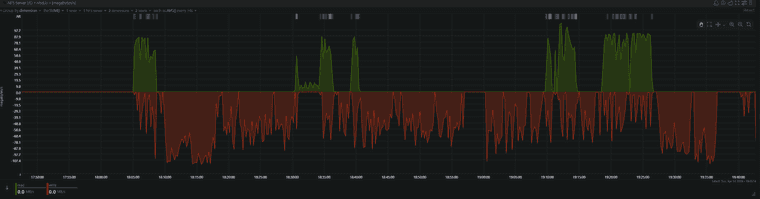
-
It would be lovely to have the stats view on your NFS server with the BR mounted before and after adding
nconnect, ideally with different number of parallel TCP connections In case you have some time to do it, that would be great!
In case you have some time to do it, that would be great! -
Changing nconnect requires restart of XOA (seems remount doesn't take a new value for nconnect), and I am heading home now, so I will try some additional benchmarks later in the week.
Btw, does xcp-ng 8.3 support nconnect? 8.2 that I am using does not.
-
Nope, it will be just for the traffic between XO and the Backup Repo (BR)
-
Ah, that's a shame, but reasonable for a point release. Maybe next major release?
This was an interesting read regarding nconnect on Azure https://learn.microsoft.com/en-us/azure/storage/files/nfs-performance
-
Yes, XCP-ng 9.x will likely able to use it
-
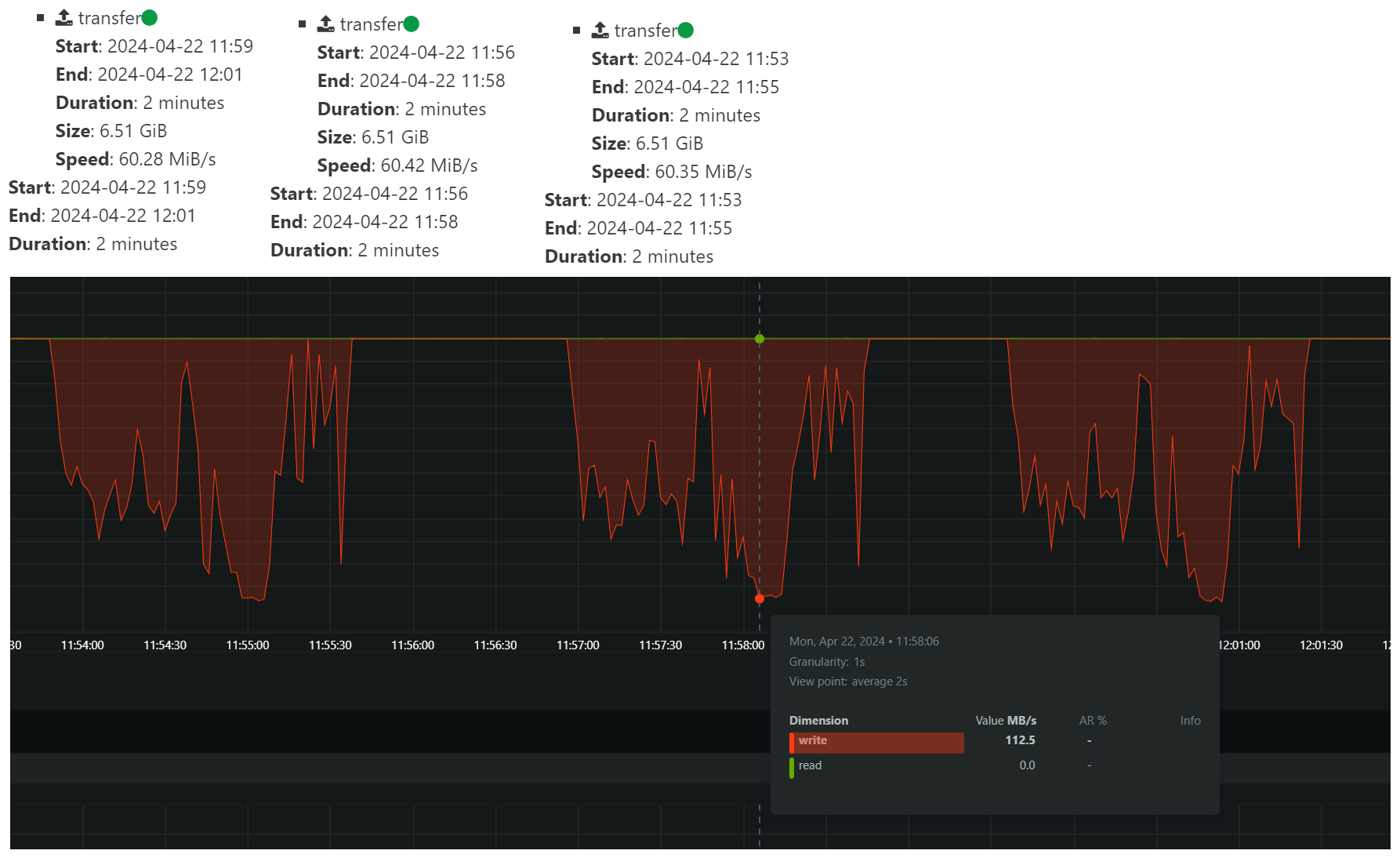
I did a 3 x backup of a single VM hosted on an SSD drive on the same host as XOA is running, which is also pool master.
This is with
nconnect=1:
This is with
nconnect=16:
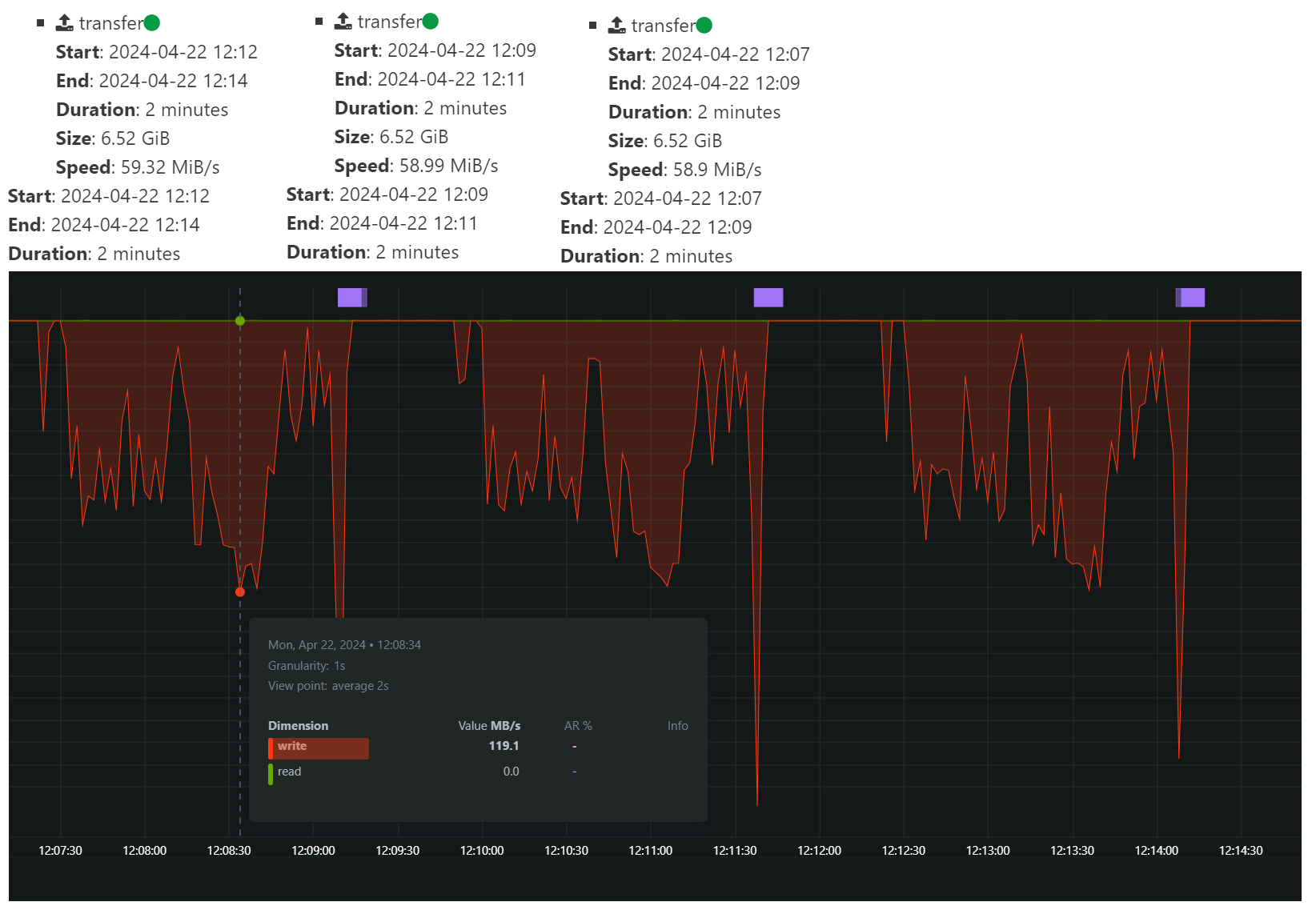
The transfer speed according to XOA is slightly less, but looking at the bandwidth graph, it looks like the LACP bonded network on the storage server is reaching a higher max throughput.
I will test some more with incremental backups and see if there's a difference with them.
If we ignore the
nconnectfor a second, and just look at the graphs, it seems we have a lot of possibilities to improve the backup performance if we could make the transfer more even. What is causing this type of pattern? I do not believe any coalesce was happening during this test. -
That's a question for @florent
-
On the read side :
- the legacy mode : xapi build an expor from the vhd chain
- NBD : we read individual block on the storage repository
On the write Side :
- the default file mode : we write 1 big file per disk
- block mode : we write a compressed block per 2MB data
We don't have a lot of room on the legacy mode. The NBD + block gives us more freedom, and , instinctively , should gain more from nconnect, since we will read and write multiple small blocks in parallel
What mode are you using ?
@Forza said in Updated XOA with kernel >5.3 to support nconnect nfs option:
I did a 3 x backup of a single VM hosted on an SSD drive on the same host as XOA is running, which is also pool master.
This is with
nconnect=1:
This is with
nconnect=16:
The transfer speed according to XOA is slightly less, but looking at the bandwidth graph, it looks like the LACP bonded network on the storage server is reaching a higher max throughput.
I will test some more with incremental backups and see if there's a difference with them.
If we ignore the
nconnectfor a second, and just look at the graphs, it seems we have a lot of possibilities to improve the backup performance if we could make the transfer more even. What is causing this type of pattern? I do not believe any coalesce was happening during this test.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login