-
With the latest XO build (commit 253aa) after a few goods backups I'm again getting:
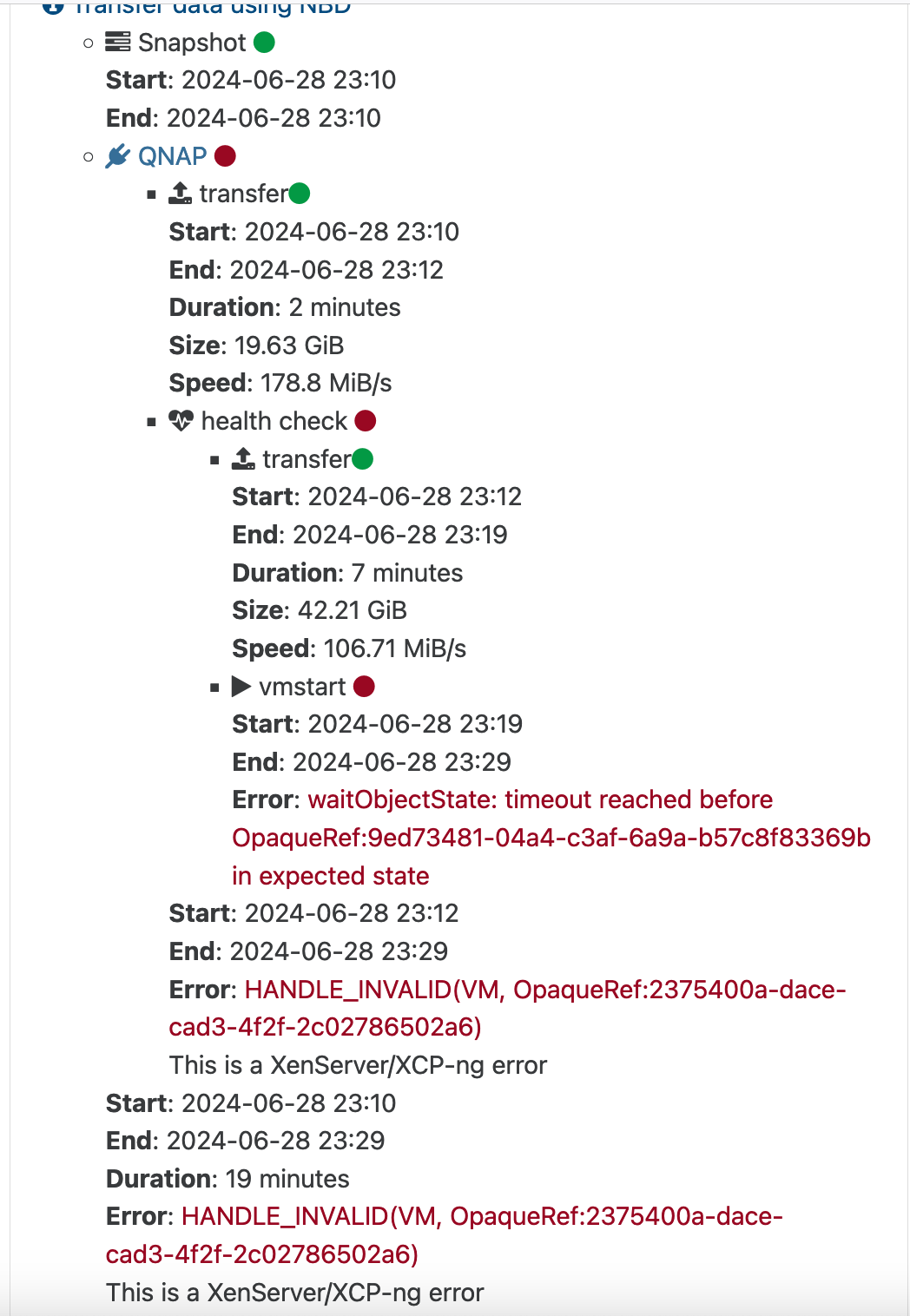
Dashboard/Health is OK.
What I see is that I have doubled snapshots (corresponding to the backup job).
-
 O olivierlambert moved this topic from Xen Orchestra on
O olivierlambert moved this topic from Xen Orchestra on
-
@manilx Deleting all the snapshots and then backing up again works once but then fails again (on some VM's) with the same error and duplicated snapshots.
reverting to old build again.
-
@manilx Also have a hung coalesce suddenly with:
Jun 29 10:33:58 vp6670 SM: [63555] ['/usr/sbin/cbt-util', 'coalesce', '-p', '/var/run/sr-mount/ea3c92b7-0e82-5726-502b-482b40a8b097/90eebfcf-4272-4462-8b9f-eedcc482478d.cbtlog', '-c', '/var/run/sr-mount/ea3c92b7-0e82-5726-502b-482b40a8b097/3369e854-0f1e-40e8-afc0-7e84a134d4e1.cbtlog'] Jun 29 10:34:10 vp6670 SM: [63844] ['/usr/sbin/cbt-util', 'coalesce', '-p', '/var/run/sr-mount/ea3c92b7-0e82-5726-502b-482b40a8b097/3eea0dc8-22b8-44a4-a9db-784e5553e580.cbtlog', '-c', '/var/run/sr-mount/ea3c92b7-0e82-5726-502b-482b40a8b097/3369e854-0f1e-40e8-afc0-7e84a134d4e1.cbtlog']Looks that there is some leftovervs from thre "CBT code" which cause havoc.
-
M manilx referenced this topic on
-
M manilx referenced this topic on
-
@manilx Reverting back to Xen Orchestra, commit be5a5 Master, commit 253aa and all is perfectly working.
I don't know if a build after this one is also OK (don't know when the CBT stuff got introduced but this is a build I have backed up that I know has been working fine). -
@manilx What type of backup job? Are you using NBD? FWIW, I'm on the same commit and my non-NBD backups aren't exhibiting this behavior.
-
@Danp Delta using NBD.
Non-NBD where also OK on "CBT" builds.
-
I think I may have a bit of a similar problem here. About a week ago, I did an update to the broken version of XO and it threw the same error as is in the subject line here. I reverted and everything was OK, but then I started to get unhealthy VDI warnings on my backups.
I tried to rescan the SR and I would see in the SMLog that it believed another GC was running, so it would abort. Rebooting the host was the only way to force the coalesce to complete; however as soon as the next inc-backup ran, it would go into the same problem (the GC thinking another is running and would no do any work).
I then did a full power off of the host, reboot and let all the VM's sit in a "powered off" state, rescanned the SR and let it coalesce. Once everything was idle, I then deleted all snapshots and waited for the coalesce to finish. Only then did I restart the VM's. Now a few VM's immediately have come up as 'unhealthy' and once again the GC will not run, thinking there is another GC working..
I'm kind of running out of idea's 8-) Does anyone know what might be stuck or what I need to look for to find out?
-
Just a side note here. I noticed that all the VM's that I am having problems with have CBT enabled.
I have a VM that is a snapshot only VM and even when the coalesces is stuck, I can delete snapshots off this non-cbt VM and the coalesces process runs (then gives an exception when it gets to the VM's that have CBT enabled)
Is there a way to disable CBT?
-
Please report any CBT issues in the dedicated thread: https://xcp-ng.org/forum/topic/9268/cbt-the-thread-to-centralize-your-feedback
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login