Backups started to fail again (overall status: failure, but both snapshot and transfer returns success)
-
Got these backup failures again. Usually only the "Docker" VM, but now all backups gives the status as mentioned in the topic. Below is one of the examples.
I have not updated XenOrchestra in a "long" time, I'm on c8f9d81 which was current at 3rd of July.
My hosts are fully updated, as well as the VM running XO.
The first non-Docker-VM failure appeared before I updated the hosts.
Anything you want to investigate, or should I just update XO and hope for these errors to stop ?{ "data": { "mode": "delta", "reportWhen": "failure" }, "id": "1753140173983", "jobId": "38f0068f-c124-4876-85d3-83f1003db60c", "jobName": "HomeAssistant", "message": "backup", "scheduleId": "dcb1c759-76b8-441b-9dc0-595914e60608", "start": 1753140173983, "status": "failure", "infos": [ { "data": { "vms": [ "ed4758f3-de34-7a7e-a46b-dc007d52f5c3" ] }, "message": "vms" } ], "tasks": [ { "data": { "type": "VM", "id": "ed4758f3-de34-7a7e-a46b-dc007d52f5c3", "name_label": "HomeAssistant" }, "id": "1753140251984", "message": "backup VM", "start": 1753140251984, "status": "failure", "tasks": [ { "id": "1753140251993", "message": "clean-vm", "start": 1753140251993, "status": "success", "end": 1753140258038, "result": { "merge": false } }, { "id": "1753140354122", "message": "snapshot", "start": 1753140354122, "status": "success", "end": 1753140356461, "result": "fc6d5d87-a2b5-cae9-8c2a-377ffff5febc" }, { "data": { "id": "2b919467-704c-4e35-bac9-2d6a43118bda", "isFull": false, "type": "remote" }, "id": "1753140356462", "message": "export", "start": 1753140356462, "status": "failure", "tasks": [ { "id": "1753140359386", "message": "transfer", "start": 1753140359386, "status": "success", "end": 1753140753378, "result": { "size": 5630853120 } }, { "id": "1753140761602", "message": "clean-vm", "start": 1753140761602, "status": "failure", "end": 1753140775782, "result": { "name": "InternalError", "$fault": "client", "$metadata": { "httpStatusCode": 500, "requestId": "D98294C01B729C95", "extendedRequestId": "RDk4Mjk0QzAxQjcyOUM5NUQ5ODI5NEMwMUI3MjlDOTVEOTgyOTRDMDFCNzI5Qzk1RDk4Mjk0QzAxQjcyOUM5NQ==", "attempts": 3, "totalRetryDelay": 112 }, "Code": "InternalError", "message": "Internal Error", "stack": "InternalError: Internal Error\n at throwDefaultError (/opt/xo/xo-builds/xen-orchestra-202507041243/node_modules/@smithy/smithy-client/dist-cjs/index.js:867:20)\n at /opt/xo/xo-builds/xen-orchestra-202507041243/node_modules/@smithy/smithy-client/dist-cjs/index.js:876:5\n at de_CommandError (/opt/xo/xo-builds/xen-orchestra-202507041243/node_modules/@aws-sdk/client-s3/dist-cjs/index.js:4952:14)\n at process.processTicksAndRejections (node:internal/process/task_queues:105:5)\n at async /opt/xo/xo-builds/xen-orchestra-202507041243/node_modules/@smithy/middleware-serde/dist-cjs/index.js:35:20\n at async /opt/xo/xo-builds/xen-orchestra-202507041243/node_modules/@aws-sdk/middleware-sdk-s3/dist-cjs/index.js:484:18\n at async /opt/xo/xo-builds/xen-orchestra-202507041243/node_modules/@smithy/middleware-retry/dist-cjs/index.js:320:38\n at async /opt/xo/xo-builds/xen-orchestra-202507041243/node_modules/@aws-sdk/middleware-sdk-s3/dist-cjs/index.js:110:22\n at async /opt/xo/xo-builds/xen-orchestra-202507041243/node_modules/@aws-sdk/middleware-sdk-s3/dist-cjs/index.js:137:14\n at async /opt/xo/xo-builds/xen-orchestra-202507041243/node_modules/@aws-sdk/middleware-logger/dist-cjs/index.js:33:22" } } ], "end": 1753140775783 } ], "end": 1753140775783 } ], "end": 1753140775784 } -
Hi,
We can't help on outdated XO commits, it's impossible to do so, see https://docs.xen-orchestra.com/community#report-a-bug. Please update to the latest one and report if you still have the issue, thanks!
edit: note that the error is likely not an XO side here, we got a HTTP 500.
-
@olivierlambert Thanks, will update every machine and XO involved in the backup process, and possibly even the individual machines that fails. First failure on vm-cleanup was 15 July, that's a few days before I patched the hosts (as a part of troubleshooting and preventing further failures). Still these backups will (probably) be fully restorable (as I have tested out with the always-failing Docker vm)
-
@peo said in Backups started to fail again (overall status: failure, but both snapshot and transfer returns success):
@olivierlambert Thanks, will update every machine and XO involved in the backup process, and possibly even the individual machines that fails. First failure on vm-cleanup was 15 July, that's a few days before I patched the hosts (as a part of troubleshooting and preventing further failures). Still these backups will (probably) be fully restorable (as I have tested out with the always-failing Docker vm)
So you patch your host, but not the administrative tools for the hosts?
Seems a little cart before the horse there, no?
-
@DustinB said in Backups started to fail again (overall status: failure, but both snapshot and transfer returns success):
@peo said in Backups started to fail again (overall status: failure, but both snapshot and transfer returns success):
@olivierlambert Thanks, will update every machine and XO involved in the backup process, and possibly even the individual machines that fails. First failure on vm-cleanup was 15 July, that's a few days before I patched the hosts (as a part of troubleshooting and preventing further failures). Still these backups will (probably) be fully restorable (as I have tested out with the always-failing Docker vm)
So you patch your host, but not the administrative tools for the hosts?
Seems a little cart before the horse there, no?
That's a fault-finding procedure: do not patch everything at once (but now I did, after finding out that patching the hosts did not solve the problem)
-
Since I updated 'everything' involved yesterday, the problems remain (this night's backups failed with the similar problem). As I'm again 6 commits behind the current version, I cannot create a useful bug report, so I'll just update and wait for the next scheduled backups to run (nothing the night towards Thursday, the next sequence will run at the night towards Friday)
-
Since yesterday, even the replication jobs started to fail (I'm again 12 commits behind the current version, but other scheduled jobs continued to fail when I was up to date with XO)
The replication is set to run from one host and store on the SSD on another. I had a power failure yesterday, but both hosts needed for this job (xcp-ng-1 and xcp-ng-2) was back up and running at the time the job was started.
{ "data": { "mode": "delta", "reportWhen": "failure" }, "id": "1753705802804", "jobId": "0bb53ced-4d52-40a9-8b14-7cd1fa2b30fe", "jobName": "Admin Ubuntu 24", "message": "backup", "scheduleId": "69a05a67-c43b-4d23-b1e8-ada77c70ccc4", "start": 1753705802804, "status": "failure", "infos": [ { "data": { "vms": [ "1728e876-5644-2169-6c62-c764bd8b6bdf" ] }, "message": "vms" } ], "tasks": [ { "data": { "type": "VM", "id": "1728e876-5644-2169-6c62-c764bd8b6bdf", "name_label": "Admin Ubuntu 24" }, "id": "1753705804503", "message": "backup VM", "start": 1753705804503, "status": "failure", "tasks": [ { "id": "1753705804984", "message": "snapshot", "start": 1753705804984, "status": "success", "end": 1753712867640, "result": "4afbdcd9-818f-9e3d-555a-ad0943081c3f" }, { "data": { "id": "46f9b5ee-c937-ff71-29b1-520ba0546675", "isFull": false, "name_label": "Local h2 SSD", "type": "SR" }, "id": "1753712867640:0", "message": "export", "start": 1753712867640, "status": "interrupted" } ], "infos": [ { "message": "will delete snapshot data" }, { "data": { "vdiRef": "OpaqueRef:c2504c79-d422-3f0a-d292-169d431e5aee" }, "message": "Snapshot data has been deleted" } ], "end": 1753717484618, "result": { "name": "BodyTimeoutError", "code": "UND_ERR_BODY_TIMEOUT", "message": "Body Timeout Error", "stack": "BodyTimeoutError: Body Timeout Error\n at FastTimer.onParserTimeout [as _onTimeout] (/opt/xo/xo-builds/xen-orchestra-202507262229/node_modules/undici/lib/dispatcher/client-h1.js:646:28)\n at Timeout.onTick [as _onTimeout] (/opt/xo/xo-builds/xen-orchestra-202507262229/node_modules/undici/lib/util/timers.js:162:13)\n at listOnTimeout (node:internal/timers:588:17)\n at process.processTimers (node:internal/timers:523:7)" } } ], "end": 1753717484619 }Also, the replication job for my Debian XO machine fails with the same 'timeout' problem.
-
Should the timeout being raised @florent ?
-
@olivierlambert I found a "solution" to the problem, by just rebooting the two involved hosts, but this might still be an issue somewhere (XO or even xcp-ng):
At the time I started up the hosts after the power failure, the dependencies had already been started a long time before (mainly my internet connectivity and the NAS which holds one of the SRs). All three hosts have their local 2TB SSD as well for different purposes (faster disk access, temporary storage and replication from other hosts).
I actually forgot to connect the network cable (unplugged because I reorganized the cables to the switch at the same time) to the third host (not involved in these recent problems) and found out that it seemed like it didn't start up properly (or at least, I did not get any video output from it when I was going to check its status after connecting the network cable), so I gave that one a hard reboot and got it up and running.
Machines with their disks on the local SSDs of the two other hosts have worked fine since I powered them up, so what follows (and the replication issue) was not expected at all:
Lock up on 'df' and 'ls /run/sr-mount/':
[11:21 xcp-ng-1 ~]# df -h ^C [11:21 xcp-ng-1 ~]# ^C[11:21 xcp-ng-1 ~]# ls /run/sr-mount/ ^C [11:22 xcp-ng-1 ~]# ls /run/('ls /run/' worked fine)
According to XO the disks were accessible and their content showed up as usual.
-
Smells a blocked SR, do you have any NFS or SMB SR that's not responsive?
-
@olivierlambert no, and all VMs were working at the time before I rebooted the two hosts (not the third one, since that didn't have problem accessing /run/sr-mount/)
I understand that 'df' will lock up if a NFS or SMB share does not respond, but ls the /run/sr-mount/ (without trying to access a subfolder) should have no reason to lock up (unless /run/sr-mount is not a ordinary folder, which it seems to be)
-
Check
dmesg, there's something blocking the mount listing. An old ISO SR maybe? -
Did anyone ever find a true resolution to this? I'm seeing a similar situation where a remote works just fine until I initiate a backup job.
Mounted a remote via NFS (v4), generated 260G of random data (using a simple dd command just to prove I can write something to the share) but when I initiate a backup job it hangs up after <10G of backup data is transferred. Sometimes it will pause for several minutes then allow a little bit more through, but it will also sometime just hang there for hours.
Latest XO commit (70d59) on a fully updated but mostly vanilla Debian 12, XCP-ng 8.3 with latest patches as of today (Aug 17, 2025). Remote target is a Synology DS1520+ with latest patches applied. Only a 1G connection, but the network is not busy by any means.
Moments before the backup 'df' and 'ls' of the respective directory worked fine. After the backup is initiated and appears to pause with <10G transferred, both commands lock up. Job in XCP-ng also seems to not want to let go.
root@xo:~# date ; df -h Sun Aug 17 10:20:45 PM EDT 2025 Filesystem Size Used Avail Use% Mounted on udev 3.9G 0 3.9G 0% /dev tmpfs 794M 572K 793M 1% /run /dev/mapper/xo--vg-root 28G 5.3G 22G 20% / tmpfs 3.9G 0 3.9G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock /dev/xvda2 456M 119M 313M 28% /boot /dev/mapper/xo--vg-var 15G 403M 14G 3% /var /dev/xvda1 511M 5.9M 506M 2% /boot/efi tmpfs 794M 0 794M 0% /run/user/1000 192.168.32.10:/volume12/XCPBackups/VMBackups 492G 17M 492G 1% /run/xo-server/mounts/1f33cf95-36d6-4c5b-b99f-71bb47008dd7 root@xo:~# date ; ls -lha /run/xo-server/mounts/1f33cf95-36d6-4c5b-b99f-71bb47008dd7/ Sun Aug 17 10:21:23 PM EDT 2025 total 0 drwxrwxrwx 1 1027 users 56 Aug 17 22:20 . drwxr-xr-x 3 root root 60 Aug 17 22:20 .. -rwxrwxrwx 1 1024 users 0 Aug 17 22:20 .nfs000000000000016400000001 root@xo:~# date ; df -h Sun Aug 17 10:22:28 PM EDT 2025 ^C root@xo:~#[22:19 xcp05 ~]# date ; xe task-list Sun Aug 17 22:20:00 EDT 2025 [22:20 xcp05 ~]# date ; xe task-list Sun Aug 17 22:22:49 EDT 2025 uuid ( RO) : 8c7cd101-9b5e-3769-0383-60beea86a272 name-label ( RO): Exporting content of VDI shifter through NBD name-description ( RO): status ( RO): pending progress ( RO): 0.101 [22:22 xcp05 ~]# date ; xe task-cancel uuid=8c7cd101-9b5e-3769-0383-60beea86a272 Sun Aug 17 22:23:13 EDT 2025 [22:23 xcp05 ~]# date ; xe task-list Sun Aug 17 22:23:28 EDT 2025 uuid ( RO) : 8c7cd101-9b5e-3769-0383-60beea86a272 name-label ( RO): Exporting content of VDI shifter through NBD name-description ( RO): status ( RO): pending progress ( RO): 0.101I'm only able to clear this task by restarting the toolstack (or host), but the issue returns as soon as I try to initiate another backup.
Host where VM resides network throughput:
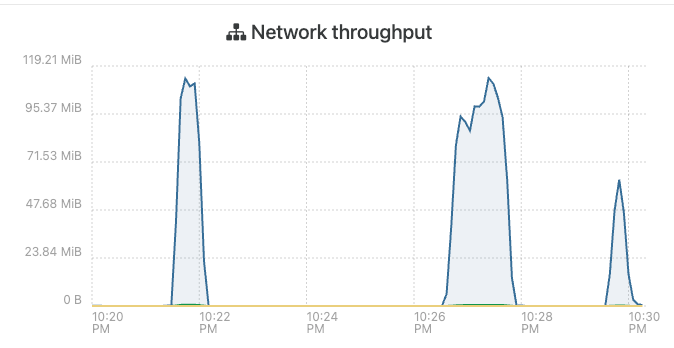
Nothing in dmesg and journalctl on XO just shows the backup starting:
Aug 17 22:21:56 xo xo-server[724]: 2025-08-18T02:21:56.031Z xo:backups:worker INFO starting backupLast bit of the VM host SMlog:
Aug 17 22:22:02 xcp05 SM: [10246] lock: released /var/lock/sm/3a1ad8c0-7f3a-4c16-9ec1-e8c315ac0c31/vdi Aug 17 22:22:02 xcp05 SM: [10246] lock: closed /var/lock/sm/b6ee0b6d-5093-b462-594f-ba2a3c3bd14c/sr Aug 17 22:22:02 xcp05 SM: [10246] lock: closed /var/lock/sm/3a1ad8c0-7f3a-4c16-9ec1-e8c315ac0c31/vdi Aug 17 22:22:02 xcp05 SM: [10246] lock: closed /var/lock/sm/lvm-b6ee0b6d-5093-b462-594f-ba2a3c3bd14c/3a1ad8c0-7f3a-4c16-9ec1-e8c315ac0c31 Aug 17 22:22:02 xcp05 SM: [10246] lock: closed /var/lock/sm/lvm-b6ee0b6d-5093-b462-594f-ba2a3c3bd14c/1fb38e78-4700-450e-800d-2d8c94158046 Aug 17 22:22:02 xcp05 SM: [10246] lock: closed /var/lock/sm/lvm-b6ee0b6d-5093-b462-594f-ba2a3c3bd14c/2ef8ae60-8beb-47fc-9cc2-b13e91192b14 Aug 17 22:22:02 xcp05 SM: [10246] lock: closed /var/lock/sm/lvm-b6ee0b6d-5093-b462-594f-ba2a3c3bd14c/lvchange-p Aug 17 22:22:36 xcp05 SM: [10559] lock: opening lock file /var/lock/sm/b6ee0b6d-5093-b462-594f-ba2a3c3bd14c/sr Aug 17 22:22:36 xcp05 SM: [10559] LVMCache created for VG_XenStorage-b6ee0b6d-5093-b462-594f-ba2a3c3bd14c Aug 17 22:22:36 xcp05 fairlock[3358]: /run/fairlock/devicemapper acquired Aug 17 22:22:36 xcp05 fairlock[3358]: /run/fairlock/devicemapper sent '10559 - 625.897991605' Aug 17 22:22:36 xcp05 SM: [10559] ['/sbin/vgs', '--readonly', 'VG_XenStorage-b6ee0b6d-5093-b462-594f-ba2a3c3bd14c'] Aug 17 22:22:36 xcp05 SM: [10559] pread SUCCESS Aug 17 22:22:36 xcp05 fairlock[3358]: /run/fairlock/devicemapper released Aug 17 22:22:36 xcp05 SM: [10559] Entering _checkMetadataVolume Aug 17 22:22:36 xcp05 SM: [10559] LVMCache: will initialize now Aug 17 22:22:36 xcp05 SM: [10559] LVMCache: refreshing Aug 17 22:22:36 xcp05 fairlock[3358]: /run/fairlock/devicemapper acquired Aug 17 22:22:36 xcp05 fairlock[3358]: /run/fairlock/devicemapper sent '10559 - 625.93107908' Aug 17 22:22:36 xcp05 SM: [10559] ['/sbin/lvs', '--noheadings', '--units', 'b', '-o', '+lv_tags', '/dev/VG_XenStorage-b6ee0b6d-5093-b462-594f-ba2a3c3bd14c'] Aug 17 22:22:37 xcp05 SM: [10559] pread SUCCESS Aug 17 22:22:37 xcp05 fairlock[3358]: /run/fairlock/devicemapper released Aug 17 22:22:37 xcp05 SM: [10559] lock: closed /var/lock/sm/b6ee0b6d-5093-b462-594f-ba2a3c3bd14c/sr Aug 17 22:32:51 xcp05 SM: [14729] lock: opening lock file /var/lock/sm/b6ee0b6d-5093-b462-594f-ba2a3c3bd14c/sr Aug 17 22:32:51 xcp05 SM: [14729] LVMCache created for VG_XenStorage-b6ee0b6d-5093-b462-594f-ba2a3c3bd14c Aug 17 22:32:51 xcp05 fairlock[3358]: /run/fairlock/devicemapper acquired Aug 17 22:32:51 xcp05 SM: [14729] ['/sbin/vgs', '--readonly', 'VG_XenStorage-b6ee0b6d-5093-b462-594f-ba2a3c3bd14c'] Aug 17 22:32:51 xcp05 fairlock[3358]: /run/fairlock/devicemapper sent '14729 - 1240.916404088' Aug 17 22:32:51 xcp05 SM: [14729] pread SUCCESS Aug 17 22:32:51 xcp05 fairlock[3358]: /run/fairlock/devicemapper released Aug 17 22:32:51 xcp05 SM: [14729] Entering _checkMetadataVolume Aug 17 22:32:51 xcp05 SM: [14729] LVMCache: will initialize now Aug 17 22:32:51 xcp05 SM: [14729] LVMCache: refreshing Aug 17 22:32:51 xcp05 fairlock[3358]: /run/fairlock/devicemapper acquired Aug 17 22:32:51 xcp05 fairlock[3358]: /run/fairlock/devicemapper sent '14729 - 1240.953398589' Aug 17 22:32:51 xcp05 SM: [14729] ['/sbin/lvs', '--noheadings', '--units', 'b', '-o', '+lv_tags', '/dev/VG_XenStorage-b6ee0b6d-5093-b462-594f-ba2a3c3bd14c'] Aug 17 22:32:52 xcp05 SM: [14729] pread SUCCESS Aug 17 22:32:52 xcp05 fairlock[3358]: /run/fairlock/devicemapper released Aug 17 22:32:52 xcp05 SM: [14729] lock: closed /var/lock/sm/b6ee0b6d-5093-b462-594f-ba2a3c3bd14c/srLooking for other ideas.
-
@jimmymiller said in Backups started to fail again (overall status: failure, but both snapshot and transfer returns success):
After the backup is initiated and appears to pause with <10G transferred, both commands lock up. Job in XCP-ng also seems to not want to let go.
You mean it's stuck in XOA?
-
@olivierlambert This particular instance is a compiled version of XO, but yes, it's XO that locks up. I'd be all over submitting a ticket if this was in XOA.
Mind you I can trigger the lock up immediately after I had sent 250G of dummy data (using dd if=/dev/random) to the exact same directory using the exact same XO. I simply deleted that dummy data, kicked off the backup job, and boom, ls & df lock up after just a few minutes.
Separately on the host, the xe export task will just sit there. Sometimes some progress will happen, other times it will sit there for days w/o any progress.
I've tried rebuilding XO from scratch (without importing an older XO config) and it happens the exact same way on the newer XO. Tried creating a separate empty volume on the Synology and a different NFS export / remote--same problem. I'm at the point of trying to rebuild the XCP-ng hosts, but I'm not really sure if that's the problem because the hosts seem happy up until I kick off the backup job. VMs can migrate; there are only local SRs, so we aren't dealing with any type of storage connection problem apart from the NFS for backups and these are two different hosts (Dell PowerEdge R450s). The only common thing I can find is that the hosts are in the same pool, the backup target hardware has remained unchanged, and they reside on the same physical network (Ubiquiti-based switches) I might try rebuilding these hosts and carving out a dummy virtual TrueNAS instance just to see if I can get a different result but I'm out of ideas on things to try after that.
-
All of that smells an NFS problem (or network problem) unrelated to XO itself (or XCP-ng), or on the NFS server

-
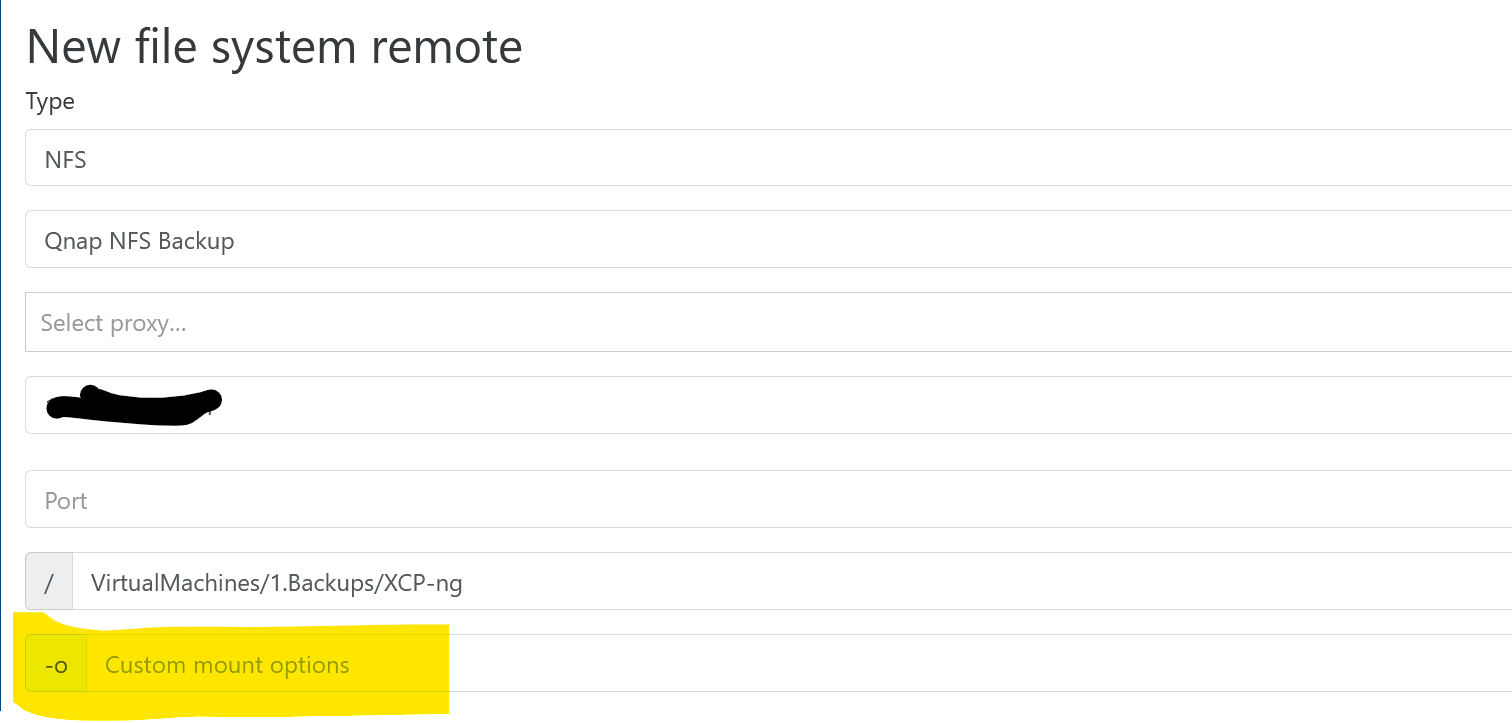
try downgrading your nfs to use version 3. I think version 4.x has performance issues.
in you settings-->remote, you can edit the nfs mount for backups and add in the -o options section.I dont know the exact command but you can try using nfsvers=3 and see if that helps.
-
Excellent suggestion
")
-
@olivierlambert & @marcoi The option is 'vers=3' w/o quotes.
I tried this recommendation and made some progress in that 'ls' and 'df' don't lock up, but the export still seems to hang.
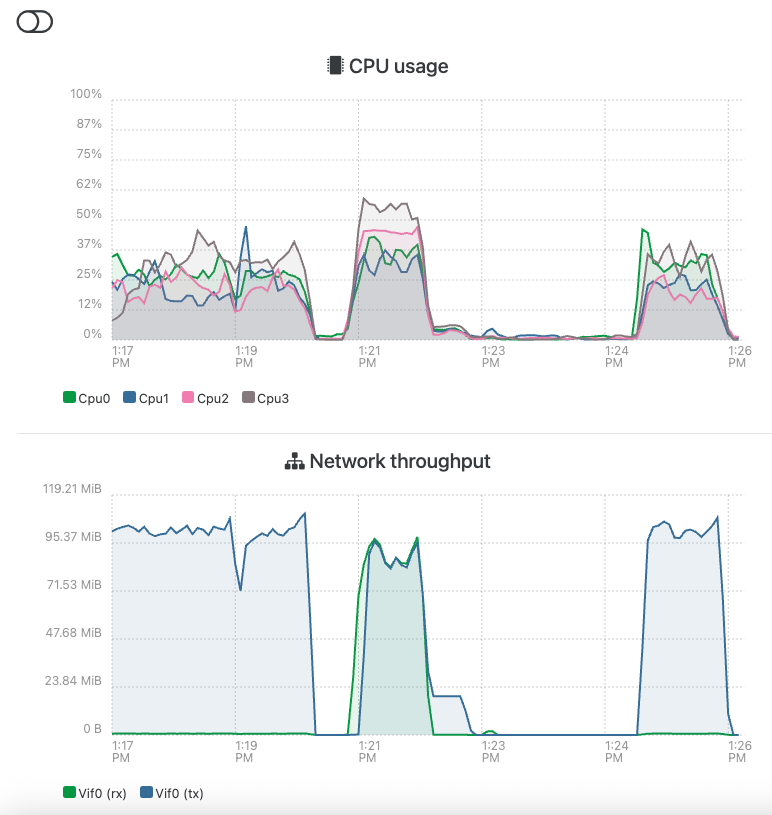
Below is a screenshot of network throughput on the XO. The plateau on the left is a 'dd if=dev/random' to a 'dummyData.txt' before the backup is kicked off. I then stop the dd and kick off the backup job (middle). After about a minute, the job hangs. I can still 'ls' and 'df' at this point, which is good, but the export job just seems stuck at 22% ('xe task-list' below). For the heck of it I tried another 'dd if=/dev/random' this time to a dummyData2.txt, which is what that plateau is on the right. While this dd is underway the backup is still supposed to be ongoing. So the directory is still writeable, but the job is just hanging up?
The number where the job hangs seems to vary too -- sometimes it will go ~30%, other times it stops at 10%. I left a job of this exact VM running last night and it actually finished, but it took 5 hrs to move 25G according to the backup report. I took <6 minutes to move 40G with the simple inefficient 'dd' command. Granted XO might be pulling (from the host) and pushing (to the NFS remote) simultaneously, but 5 hours doesn't seem right.
XO output before and while backup is ongoing:
root@xo:/run/xo-server/mounts/1f33cf95-36d6-4c5b-b99f-71bb47008dd7# ls -lha total 0 drwxrwxrwx 1 1027 users 56 Aug 18 13:12 . drwxr-xr-x 3 root root 60 Aug 18 13:11 .. -rwxrwxrwx 1 1024 users 0 Aug 18 13:11 .nfs000000000000017400000001 root@xo:/run/xo-server/mounts/1f33cf95-36d6-4c5b-b99f-71bb47008dd7# dd if=/dev/random of=/run/xo-server/mounts/1f33cf95-36d6-4c5b-b99f-71bb47008dd7/dummyData.txt bs=1M ^C36868+0 records in 36868+0 records out 38658899968 bytes (39 GB, 36 GiB) copied, 368.652 s, 105 MB/s root@xo:/run/xo-server/mounts/1f33cf95-36d6-4c5b-b99f-71bb47008dd7# df -h Filesystem Size Used Avail Use% Mounted on udev 3.9G 0 3.9G 0% /dev tmpfs 794M 584K 793M 1% /run /dev/mapper/xo--vg-root 28G 5.3G 22G 20% / tmpfs 3.9G 0 3.9G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock /dev/xvda2 456M 119M 313M 28% /boot /dev/mapper/xo--vg-var 15G 403M 14G 3% /var /dev/xvda1 511M 5.9M 506M 2% /boot/efi tmpfs 794M 0 794M 0% /run/user/1000 192.168.32.10:/volume12/XCPBackups/VMBackups 492G 42G 451G 9% /run/xo-server/mounts/1f33cf95-36d6-4c5b-b99f-71bb47008dd7 root@xo:/run/xo-server/mounts/1f33cf95-36d6-4c5b-b99f-71bb47008dd7# ls -lha total 37G drwxrwxrwx 1 1027 users 164 Aug 18 13:20 . drwxr-xr-x 3 root root 60 Aug 18 13:11 .. -rwxrwxrwx 1 1024 users 37G Aug 18 13:20 dummyData.txt -rwxrwxrwx 1 1024 users 0 Aug 18 13:11 .nfs000000000000017400000001 -rwxrwxrwx 1 1024 users 0 Aug 18 13:20 .nfs000000000000017700000002 drwxrwxrwx 1 1024 users 154 Aug 18 13:20 xo-vm-backups root@xo:/run/xo-server/mounts/1f33cf95-36d6-4c5b-b99f-71bb47008dd7# cd root@xo:~# df -h Filesystem Size Used Avail Use% Mounted on udev 3.9G 0 3.9G 0% /dev tmpfs 794M 584K 793M 1% /run /dev/mapper/xo--vg-root 28G 5.3G 22G 20% / tmpfs 3.9G 0 3.9G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock /dev/xvda2 456M 119M 313M 28% /boot /dev/mapper/xo--vg-var 15G 404M 14G 3% /var /dev/xvda1 511M 5.9M 506M 2% /boot/efi tmpfs 794M 0 794M 0% /run/user/1000 192.168.32.10:/volume12/XCPBackups/VMBackups 492G 42G 450G 9% /run/xo-server/mounts/1f33cf95-36d6-4c5b-b99f-71bb47008dd7 root@xo:~# ls -lha /run/xo-server/mounts/1f33cf95-36d6-4c5b-b99f-71bb47008dd7 total 37G drwxrwxrwx 1 1027 users 164 Aug 18 13:20 . drwxr-xr-x 3 root root 60 Aug 18 13:11 .. -rwxrwxrwx 1 1024 users 37G Aug 18 13:20 dummyData.txt -rwxrwxrwx 1 1024 users 0 Aug 18 13:11 .nfs000000000000017400000001 -rwxrwxrwx 1 1024 users 0 Aug 18 13:20 .nfs000000000000017700000002 drwxrwxrwx 1 1024 users 154 Aug 18 13:20 xo-vm-backups root@xo:~# dd if=/dev/random of=/run/xo-server/mounts/1f33cf95-36d6-4c5b-b99f-71bb47008dd7/dummyData2.txt bs=1M ^C7722+0 records in 7722+0 records out 8097103872 bytes (8.1 GB, 7.5 GiB) copied, 78.9522 s, 103 MB/s root@conductor:~# ls /run/xo-server/mounts/1f33cf95-36d6-4c5b-b99f-71bb47008dd7 dummyData2.txt dummyData.txt xo-vm-backups[13:32 xcp05 ~]# xe task-list uuid ( RO) : ba902e8a-7f08-9de9-8ade-e879ffb35e11 name-label ( RO): Exporting content of VDI shifter through NBD name-description ( RO): status ( RO): pending progress ( RO): 0.222Any other ideas before I go down the route of trying to carve out a virtual NAS instance?
Thanks again for your input.
-
@jimmymiller
step 1 - reboot xo, xcp host and nas. Try just the backup again.
if step 1 fails then step 2- Clone the vm so you have a test to play with. setup a new remote to another path on nas using ver=3 command. Then setup a new backup job just for that one vm and test backup without any other testing like using dd.you need to first confirm your setup works using the separate testing above.
its possible your backups got messed up somehow (permissions/files) and once you confirm your setup is working or not we can figured out possible next steps.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login