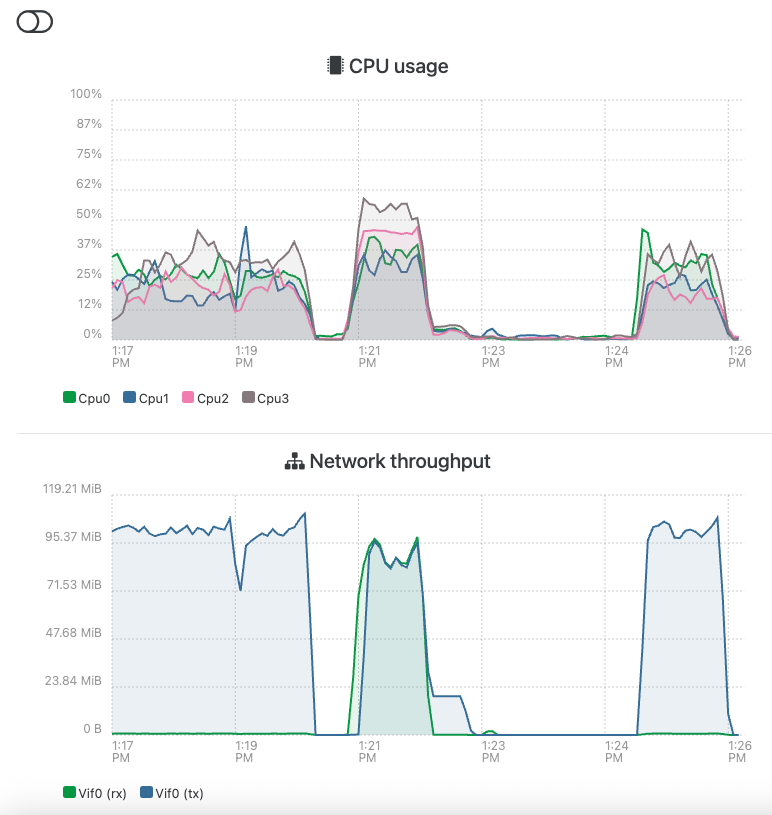
Did anyone ever find a true resolution to this? I'm seeing a similar situation where a remote works just fine until I initiate a backup job.
Mounted a remote via NFS (v4), generated 260G of random data (using a simple dd command just to prove I can write something to the share) but when I initiate a backup job it hangs up after <10G of backup data is transferred. Sometimes it will pause for several minutes then allow a little bit more through, but it will also sometime just hang there for hours.
Latest XO commit (70d59) on a fully updated but mostly vanilla Debian 12, XCP-ng 8.3 with latest patches as of today (Aug 17, 2025). Remote target is a Synology DS1520+ with latest patches applied. Only a 1G connection, but the network is not busy by any means.
Moments before the backup 'df' and 'ls' of the respective directory worked fine. After the backup is initiated and appears to pause with <10G transferred, both commands lock up. Job in XCP-ng also seems to not want to let go.
root@xo:~# date ; df -h
Sun Aug 17 10:20:45 PM EDT 2025
Filesystem Size Used Avail Use% Mounted on
udev 3.9G 0 3.9G 0% /dev
tmpfs 794M 572K 793M 1% /run
/dev/mapper/xo--vg-root 28G 5.3G 22G 20% /
tmpfs 3.9G 0 3.9G 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/xvda2 456M 119M 313M 28% /boot
/dev/mapper/xo--vg-var 15G 403M 14G 3% /var
/dev/xvda1 511M 5.9M 506M 2% /boot/efi
tmpfs 794M 0 794M 0% /run/user/1000
192.168.32.10:/volume12/XCPBackups/VMBackups 492G 17M 492G 1% /run/xo-server/mounts/1f33cf95-36d6-4c5b-b99f-71bb47008dd7
root@xo:~# date ; ls -lha /run/xo-server/mounts/1f33cf95-36d6-4c5b-b99f-71bb47008dd7/
Sun Aug 17 10:21:23 PM EDT 2025
total 0
drwxrwxrwx 1 1027 users 56 Aug 17 22:20 .
drwxr-xr-x 3 root root 60 Aug 17 22:20 ..
-rwxrwxrwx 1 1024 users 0 Aug 17 22:20 .nfs000000000000016400000001
root@xo:~# date ; df -h
Sun Aug 17 10:22:28 PM EDT 2025
^C
root@xo:~#
[22:19 xcp05 ~]# date ; xe task-list
Sun Aug 17 22:20:00 EDT 2025
[22:20 xcp05 ~]# date ; xe task-list
Sun Aug 17 22:22:49 EDT 2025
uuid ( RO) : 8c7cd101-9b5e-3769-0383-60beea86a272
name-label ( RO): Exporting content of VDI shifter through NBD
name-description ( RO):
status ( RO): pending
progress ( RO): 0.101
[22:22 xcp05 ~]# date ; xe task-cancel uuid=8c7cd101-9b5e-3769-0383-60beea86a272
Sun Aug 17 22:23:13 EDT 2025
[22:23 xcp05 ~]# date ; xe task-list
Sun Aug 17 22:23:28 EDT 2025
uuid ( RO) : 8c7cd101-9b5e-3769-0383-60beea86a272
name-label ( RO): Exporting content of VDI shifter through NBD
name-description ( RO):
status ( RO): pending
progress ( RO): 0.101
I'm only able to clear this task by restarting the toolstack (or host), but the issue returns as soon as I try to initiate another backup.
Host where VM resides network throughput:
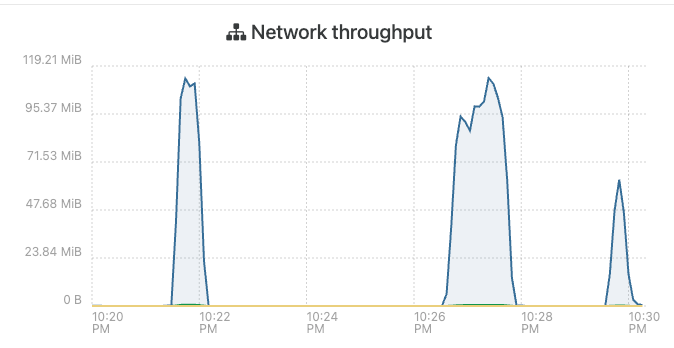
Nothing in dmesg and journalctl on XO just shows the backup starting:
Aug 17 22:21:56 xo xo-server[724]: 2025-08-18T02:21:56.031Z xo:backups:worker INFO starting backup
Last bit of the VM host SMlog:
Aug 17 22:22:02 xcp05 SM: [10246] lock: released /var/lock/sm/3a1ad8c0-7f3a-4c16-9ec1-e8c315ac0c31/vdi
Aug 17 22:22:02 xcp05 SM: [10246] lock: closed /var/lock/sm/b6ee0b6d-5093-b462-594f-ba2a3c3bd14c/sr
Aug 17 22:22:02 xcp05 SM: [10246] lock: closed /var/lock/sm/3a1ad8c0-7f3a-4c16-9ec1-e8c315ac0c31/vdi
Aug 17 22:22:02 xcp05 SM: [10246] lock: closed /var/lock/sm/lvm-b6ee0b6d-5093-b462-594f-ba2a3c3bd14c/3a1ad8c0-7f3a-4c16-9ec1-e8c315ac0c31
Aug 17 22:22:02 xcp05 SM: [10246] lock: closed /var/lock/sm/lvm-b6ee0b6d-5093-b462-594f-ba2a3c3bd14c/1fb38e78-4700-450e-800d-2d8c94158046
Aug 17 22:22:02 xcp05 SM: [10246] lock: closed /var/lock/sm/lvm-b6ee0b6d-5093-b462-594f-ba2a3c3bd14c/2ef8ae60-8beb-47fc-9cc2-b13e91192b14
Aug 17 22:22:02 xcp05 SM: [10246] lock: closed /var/lock/sm/lvm-b6ee0b6d-5093-b462-594f-ba2a3c3bd14c/lvchange-p
Aug 17 22:22:36 xcp05 SM: [10559] lock: opening lock file /var/lock/sm/b6ee0b6d-5093-b462-594f-ba2a3c3bd14c/sr
Aug 17 22:22:36 xcp05 SM: [10559] LVMCache created for VG_XenStorage-b6ee0b6d-5093-b462-594f-ba2a3c3bd14c
Aug 17 22:22:36 xcp05 fairlock[3358]: /run/fairlock/devicemapper acquired
Aug 17 22:22:36 xcp05 fairlock[3358]: /run/fairlock/devicemapper sent '10559 - 625.897991605'
Aug 17 22:22:36 xcp05 SM: [10559] ['/sbin/vgs', '--readonly', 'VG_XenStorage-b6ee0b6d-5093-b462-594f-ba2a3c3bd14c']
Aug 17 22:22:36 xcp05 SM: [10559] pread SUCCESS
Aug 17 22:22:36 xcp05 fairlock[3358]: /run/fairlock/devicemapper released
Aug 17 22:22:36 xcp05 SM: [10559] Entering _checkMetadataVolume
Aug 17 22:22:36 xcp05 SM: [10559] LVMCache: will initialize now
Aug 17 22:22:36 xcp05 SM: [10559] LVMCache: refreshing
Aug 17 22:22:36 xcp05 fairlock[3358]: /run/fairlock/devicemapper acquired
Aug 17 22:22:36 xcp05 fairlock[3358]: /run/fairlock/devicemapper sent '10559 - 625.93107908'
Aug 17 22:22:36 xcp05 SM: [10559] ['/sbin/lvs', '--noheadings', '--units', 'b', '-o', '+lv_tags', '/dev/VG_XenStorage-b6ee0b6d-5093-b462-594f-ba2a3c3bd14c']
Aug 17 22:22:37 xcp05 SM: [10559] pread SUCCESS
Aug 17 22:22:37 xcp05 fairlock[3358]: /run/fairlock/devicemapper released
Aug 17 22:22:37 xcp05 SM: [10559] lock: closed /var/lock/sm/b6ee0b6d-5093-b462-594f-ba2a3c3bd14c/sr
Aug 17 22:32:51 xcp05 SM: [14729] lock: opening lock file /var/lock/sm/b6ee0b6d-5093-b462-594f-ba2a3c3bd14c/sr
Aug 17 22:32:51 xcp05 SM: [14729] LVMCache created for VG_XenStorage-b6ee0b6d-5093-b462-594f-ba2a3c3bd14c
Aug 17 22:32:51 xcp05 fairlock[3358]: /run/fairlock/devicemapper acquired
Aug 17 22:32:51 xcp05 SM: [14729] ['/sbin/vgs', '--readonly', 'VG_XenStorage-b6ee0b6d-5093-b462-594f-ba2a3c3bd14c']
Aug 17 22:32:51 xcp05 fairlock[3358]: /run/fairlock/devicemapper sent '14729 - 1240.916404088'
Aug 17 22:32:51 xcp05 SM: [14729] pread SUCCESS
Aug 17 22:32:51 xcp05 fairlock[3358]: /run/fairlock/devicemapper released
Aug 17 22:32:51 xcp05 SM: [14729] Entering _checkMetadataVolume
Aug 17 22:32:51 xcp05 SM: [14729] LVMCache: will initialize now
Aug 17 22:32:51 xcp05 SM: [14729] LVMCache: refreshing
Aug 17 22:32:51 xcp05 fairlock[3358]: /run/fairlock/devicemapper acquired
Aug 17 22:32:51 xcp05 fairlock[3358]: /run/fairlock/devicemapper sent '14729 - 1240.953398589'
Aug 17 22:32:51 xcp05 SM: [14729] ['/sbin/lvs', '--noheadings', '--units', 'b', '-o', '+lv_tags', '/dev/VG_XenStorage-b6ee0b6d-5093-b462-594f-ba2a3c3bd14c']
Aug 17 22:32:52 xcp05 SM: [14729] pread SUCCESS
Aug 17 22:32:52 xcp05 fairlock[3358]: /run/fairlock/devicemapper released
Aug 17 22:32:52 xcp05 SM: [14729] lock: closed /var/lock/sm/b6ee0b6d-5093-b462-594f-ba2a3c3bd14c/sr
Looking for other ideas.