Large incremental backups
-
I have a Windows RDS server that has an hourly delta backup. I expect these backups to only be 1.5GB or so however they are now over 150GB.
Is the delta backup only looking for file changes and if so 150GB should be easy enough to identify whwn comparing tow deltas.
Is there a recommended way to diagnose large delta backups?
-
Backups are made by doing a VHD diff. A VHD block is 2MiB, if you modify just one bit inside a 2MiB block the entire block is needed to be exported.
MS OS are known to write a bit everywhere, so I'm not entirely surprised.
-
Thanks for the clarification.
So this means it is not directly rated to files being updated rather disk changes which may or may not be a result of files being updated. So me searching for the large files that have been changed since the last delta is a waste of time?
I guess something like a defrag would result in a large delta too.
-
Yes, anything moving blocks around will generate more data to backup. So it might not be some specific files, just logs rotation or anything doing random write at many places
-
The server had high memory usage so I expect lots of paging, which could explain the block writes. I've increased the mem and want to see what difference that makes.
-
The question that is begging to be answered then is would Change Block Tracking (CBT) address this issue?
Presumably it would, but as the post is still actively getting updates, https://xcp-ng.org/forum/topic/9268/cbt-the-thread-to-centralize-your-feedback
-
I do not know how CBT works but will take a look.
-
The results are good!
Before increasing the VM memory to reduce paging:
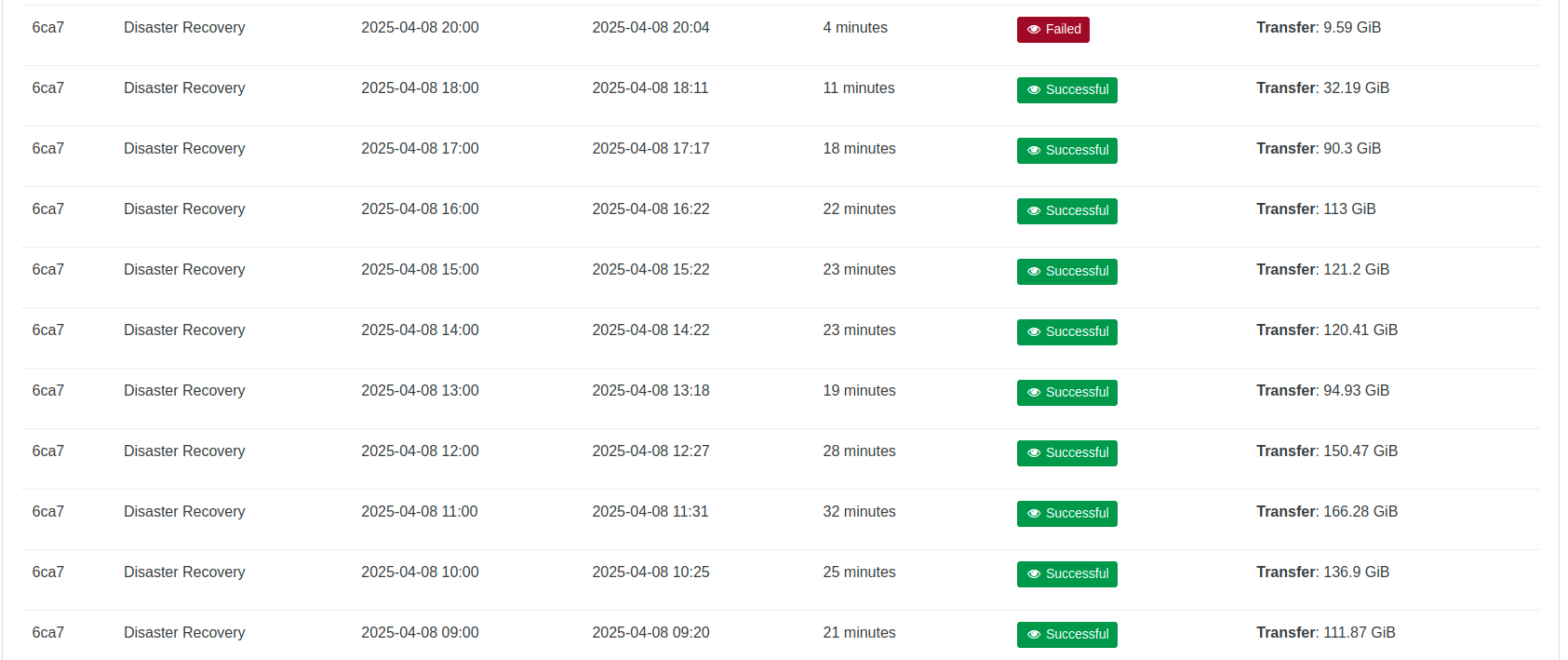
After increasing the VM memory to reduce paging:
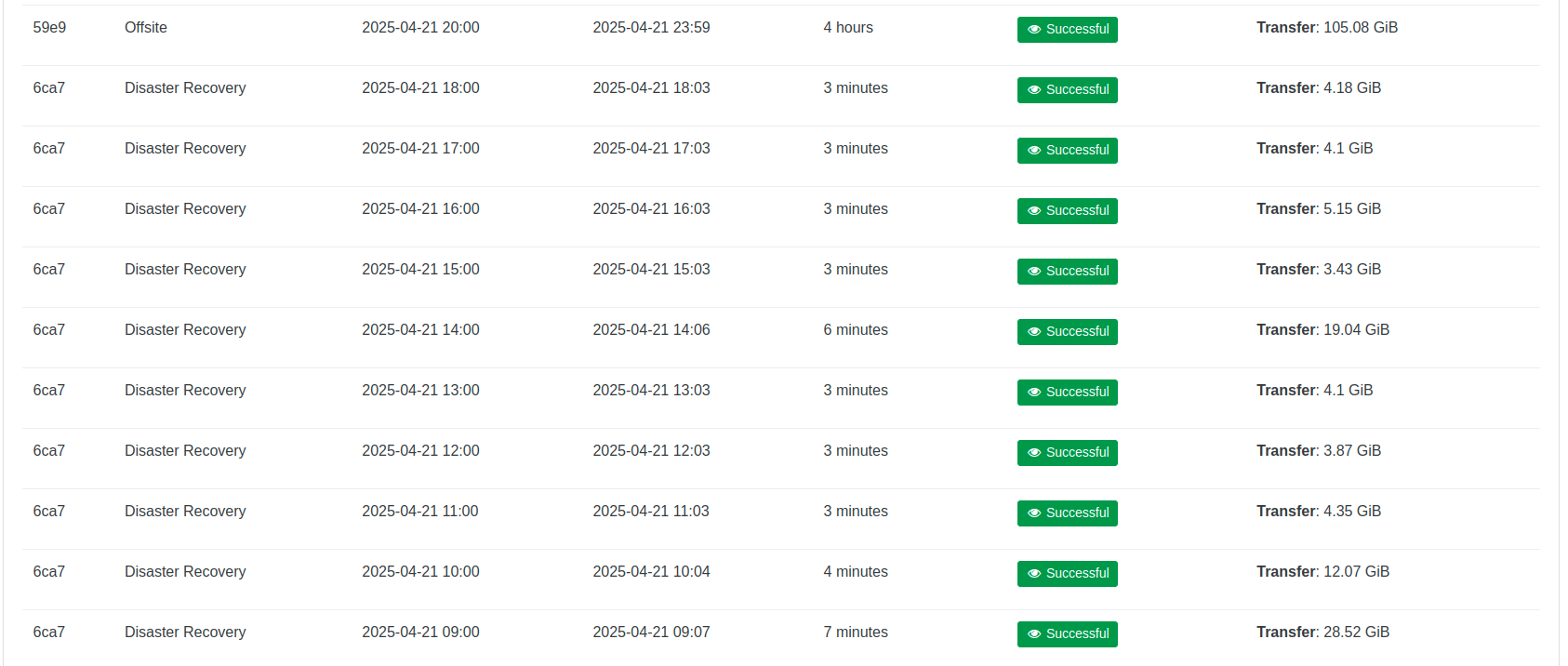
@olivierlambert
One problem we now have is the new VM memory exceeds the DR host's memory so the health check fails "no hosts available". It would be good if a health check could be started using a lesser mem value as it only needs the network to activate to pass. -
@McHenry said in Large incremental backups:
One problem we now have is the new VM memory exceeds the DR host's memory so the health check fails "no hosts available". It would be good if a health check could be started using a lesser mem value as it only needs the network to activate to pass.
Is this possible on any other hypervisor? If so It would definitely be worth looking into . . .
-
@McHenry Am wondering if defragmenting the drives might help, at least some, if nothing else perhaps slightly better I/O performance?
-
Other hypervisors I have used do not perform the healthcheck as an auto restore on a different host so I cannot say. It would be good if the healthcheck could start the VM with the minimum memory value configured.
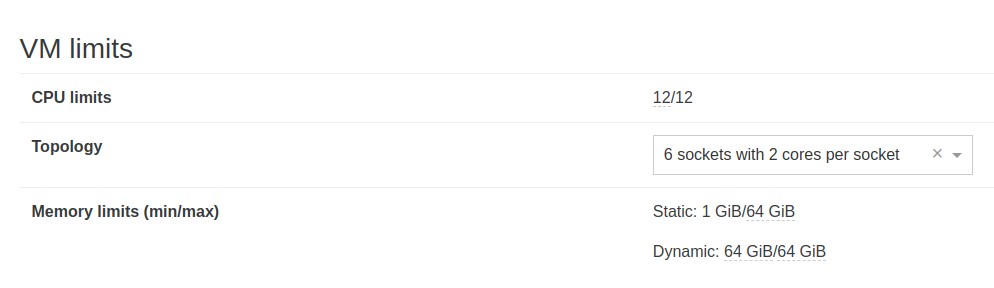
-
@McHenry Can you put the paging file on a separate disk, and then tag that disk not to be backed up?
-
@McHenry said in Large incremental backups:
Other hypervisors I have used do not perform the healthcheck as an auto restore on a different host so I cannot say. It would be good if the healthcheck could start the VM with the minimum memory value configured.
Those minimums aren't really "minimums" in the sense that you're thinking. They are the template minimums and changing those configurations on the fly would actually impact the guest as a whole from its startup.
Changing the dynamic memory to use something less than the guest's configured Memory causes other issues with backups, I'm not certain as to why, but I've found other administrators who have changed that setting to 32Gb/64Gb and then suddenly the VM can't be backed up or has other issues. Someone else would have to elaborate as to why this is the case though.
Setting the same to 64Gb/64Gb fixes said issues.
-
@McHenry That's a very interesting result
") (adding @florent to see it and @thomas-dkmt to maybe document this).
(adding @florent to see it and @thomas-dkmt to maybe document this).Regarding health feature, how we could guess down which memory we could go to test if the test recovery VM boots?
-
Hyper-V has the concept of Dynamic memory as documented below. This allows a startup mem value to be specified and something similar could be used for health checks as this is only needed for the network to connect then them VM gets killed.

Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login