Xen Orchestra Container Storage Interface (CSI) for Kubernetes
-
@Cyrille My concern is that you are closing the door for people that do not need (or do not want) XO in their stack. Maybe they are using other ways to manage the stack, possibly custom developed, and XO would just be one more point of failure, another security concern etc.
From what I can gather, XO effectively acts as an API proxy here, plus as a list of pools. That's a rather insignificant (and forced?) role, from a technical point of view, considering XO has much much more functionality outside of what XCP-ng and XAPI offer themselves. All of that unused and not required for this integration.
-
Actually, it's not a closed door; it's more a door that is opening for people who are already using both Xen Orchestra and Kubernetes.

From a technical point of view, it makes more sense for us to use XO, because its API is easier to use, especially with the new REST API. For the application side itself, it does many thing that we don't have to deal with. For VDIs, perhaps it's not so much. But for other things such as backups, live migrations, templates and VM creation... it's easier. Moreover, using a unique SDK to develop tools makes sense for our small DevOps team in terms of development speed, stability and security.
-
Again, XCP-ng and Xen Orchestra are really meant to work together: that’s by design. Our goal is to offer a unified stack with one consistent REST API to manage everything, across any number of pools.
XO already handles a ton of things: auth (with oidc, SAML etc.), multi-pool aggregation, RBAC/ACLs, task tracking, templates, backups, live migrations, etc. By building on top of XO, we can focus on adding real value instead of re-implementing all that logic again in any 3rd party program we maintain in full open source and for free.
And honestly, I don’t see any issue relying on XO: everything is fully open source, and all features are available for free from the sources, just like it’s always been. Nobody’s forcing you to use one or the other: if you’d rather build directly on XAPI, you absolutely can.
-
Great stuff, looking forward and will try the CSI in the next couple of weeks
")
@bvitnik There is an old CSI for xcp-ng (5 years old) which directly talks to the Xen-API, but I'd rather have a middleware which as @olivierlambert already stated has ACL's and security build-in.
Eventually you will end up in a broken xen cluster because you have a k8s node with cluster wide privileges to the XenAPI.@olivierlambert Is there any loose roadmap for the CSI?
Cheers,
Jan -
The roadmap depends a lot on the feedback we have on it
") More demand/popular, faster we'll implement stuff
More demand/popular, faster we'll implement stuff -
My validation of this was not successful; I used the Quick Start PoC.
Pods eventually went intoCrashLoopBackOffafterErrImagePullandImagePullBackOff.
I created a GitHub token with these permissions:public_repo, read:packages. I also used a token with more permissions (although that was futile) however, I figured at least it required the aforementioned ones.I have since uninstalled via the script but captured the following events from the controller and one of the node pods:
kgp -nkube-system | grep csi* csi-xenorchestra-controller-748db9b45b-z26h6 1/3 CrashLoopBackOff 31 (2m31s ago) 77m csi-xenorchestra-node-4jw9z 1/3 CrashLoopBackOff 18 (42s ago) 77m csi-xenorchestra-node-7wcld 1/3 CrashLoopBackOff 18 (58s ago) 77m csi-xenorchestra-node-8jrlq 1/3 CrashLoopBackOff 18 (34s ago) 77m csi-xenorchestra-node-hqwjj 1/3 CrashLoopBackOff 18 (50s ago) 77mPod events:
csi-xenorchestra-controller-748db9b45b-z26h6Normal BackOff 3m48s (x391 over 78m) kubelet Back-off pulling image "ghcr.io/vatesfr/xenorchestra-csi-driver:edge"csi-xenorchestra-node-4jw9z
Normal BackOff 14m (x314 over 79m) kubelet Back-off pulling image "ghcr.io/vatesfr/xenorchestra-csi-driver:edge" Warning BackOff 4m21s (x309 over 78m) kubelet Back-off restarting failed container node-driver-registrar in pod csi-xenorchestra-node-4jw9z_kube-system(b533c28b-1f28-488a-a31e-862117461964)I can deploy again and capture more information if needed.
-
@ThasianXi Hello, thanks for the report. It looks like the pull image step fails. Can you test that the token generated from Github is working and allows to pull the image.
Maybe a simple test on a docker install could ease the verification:
docker login ghcr.io -u USERNAME -p TOKEN docker pull ghcr.io/vatesfr/xenorchestra-csi:v0.0.1Also note that only "Classic" persona access token are supported.
-
@nathanael-h
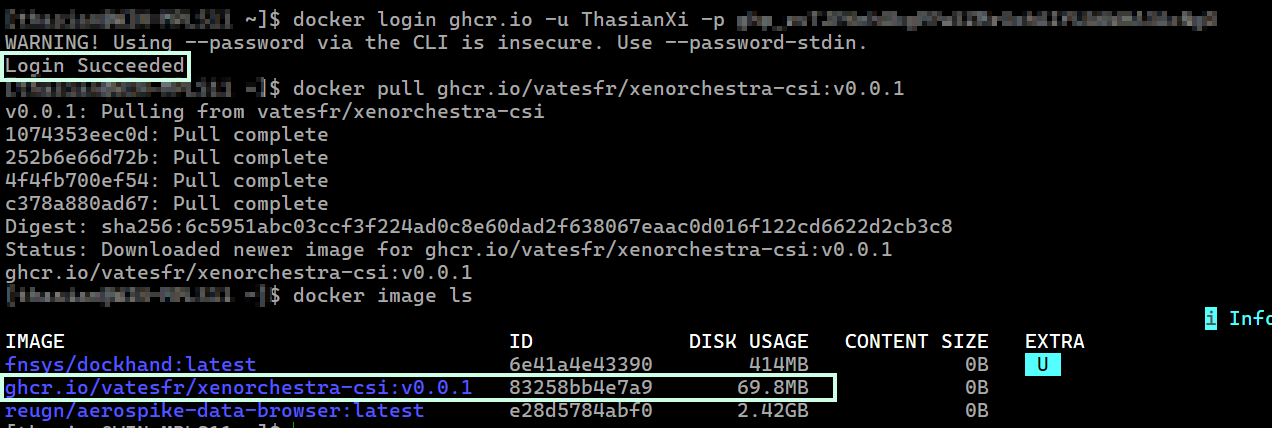
 The image pull was successful to my local computer using the same classic personal access token I generated and set as the
The image pull was successful to my local computer using the same classic personal access token I generated and set as the regcredsecret.

Looking at the documentation again and since I am not using MicroK8s, I tried something different but the result was the same. (the pods never transitioned to a running state).This time, prior to executing the install script, I updated the
kubelet-registration-pathand the volume path in thecsi-xenorchestra-node-single.yamlandcsi-xenorchestra-node.yamlfiles.
(I believe this would be an opportunity to update the README for clarity on what to update based on the Kubernetes platform i.e. MicroK8s vs non-MicroK8s -- I can submit a PR for this, if you like)
excerpts:- --kubelet-registration-path=/var/lib/kubelet/plugins/csi.xenorchestra.vates.tech/csi.sock #- --kubelet-registration-path=/var/snap/microk8s/common/var/lib/kubelet/plugins/csi.xenorchestra.vates.tech/csi.sock ------------------------- volumes: - hostPath: path: /var/lib/kubelet/plugins/csi.xenorchestra.vates.tech type: DirectoryOrCreate name: socket-dirOn the
control-plane:[root@xxxx kubelet]# pwd /var/lib/kubelet [root@xxxx kubelet]# tree plugins plugins └── csi.xenorchestra.vates.techkgp -nkube-system | grep csi csi-xenorchestra-controller-748db9b45b-w4zk4 2/3 ImagePullBackOff 19 (12s ago) 41m csi-xenorchestra-node-6zzv8 1/3 CrashLoopBackOff 11 (3m51s ago) 41m csi-xenorchestra-node-8r4ml 1/3 CrashLoopBackOff 11 (3m59s ago) 41m csi-xenorchestra-node-btrsb 1/3 CrashLoopBackOff 11 (4m11s ago) 41m csi-xenorchestra-node-w69pc 1/3 CrashLoopBackOff 11 (4m3s ago) 41mExcerpt from
/var/log/messages:Feb 18 22:21:44 xxx kubelet[50541]: I0218 22:21:44.474317 50541 scope.go:117] "RemoveContainer" containerID="26d29856a551fe7dfd873a3f8124584d400d1a88d77cdb4c1797a9726fa85408" Feb 18 22:21:44 xxx crio[734]: time="2026-02-18 22:21:44.475900036-05:00" level=info msg="Checking image status: ghcr.io/vatesfr/xenorchestra-csi-driver:edge" id=308f8922-453b-481f-804d-3d85b489b933 name=/runtime.v1.ImageService/ImageStatus Feb 18 22:21:44 xxx crio[734]: time="2026-02-18 22:21:44.476149865-05:00" level=info msg="Image ghcr.io/vatesfr/xenorchestra-csi-driver:edge not found" id=308f8922-453b-481f-804d-3d85b489b933 name=/runtime.v1.ImageService/ImageStatus Feb 18 22:21:44 xxx crio[734]: time="2026-02-18 22:21:44.476188202-05:00" level=info msg="Image ghcr.io/vatesfr/xenorchestra-csi-driver:edge not found" id=308f8922-453b-481f-804d-3d85b489b933 name=/runtime.v1.ImageService/ImageStatus Feb 18 22:21:44 xxx kubelet[50541]: E0218 22:21:44.476862 50541 pod_workers.go:1298] "Error syncing pod, skipping" err="[failed to \"StartContainer\" for \"node-driver-registrar\" with CrashLoopBackOff: \"back-off 5m0s restarting failed container=node-driver-registrar pod=csi-xenorchestra-node-btrsb_kube-system(433e69c9-2da9-4e23-b92b-90918bd36248)\", failed to \"StartContainer\" for \"xenorchestra-csi-driver\" with ImagePullBackOff: \"Back-off pulling image \\\"ghcr.io/vatesfr/xenorchestra-csi-driver:edge\\\"\"]" pod="kube-system/csi-xenorchestra-node-btrsb" podUID="433e69c9-2da9-4e23-b92b-90918bd36248"Any other suggestions in the meantime or if I can collect more information, let me know.
-
@nathanael-h There should be no need to use an access token, because:
a) the personal account does not have access to the vates repo and can therefor not grant any privileges
b) isxenorchestra-csi-drivera public repo and all assets are public availableThe only valid point can be rate limits but as this test setup usually does not invoke a massive load of docker pulls it should be neglectable.
@thasianxi
It looks like a mixup, the Repo / Deployment refers to the github repository name as docker image which is usually the case. Unfortunatly the packages (which are created have a different name) can you replaceghcr.io/vatesfr/xenorchestra-csi-driver:edgewithghcr.io/vatesfr/xenorchestra-csi:edgein the manifest and retry?Cheers
Jan M. -
@jmara Thank you for the input. All pods are running with caveats.

Prior to executing the installation, I updated the image name to
ghcr.io/vatesfr/xenorchestra-csi:edgein the manifests.
After executing the install, I had to manually edit the image name in the DaemonSet, fromghcr.io/vatesfr/xenorchestra-csi-driver:edgetoghcr.io/vatesfr/xenorchestra-csi:edge.
After editing the DaemonSet, the node pods restarted and transitioned to running.However, the controller pod was still attempting to pull this image:
ghcr.io/vatesfr/xenorchestra-csi-driver:edgeand never transitioned to running.
To correct that, I edited the image name in the Deployment, fromghcr.io/vatesfr/xenorchestra-csi-driver:edgetoghcr.io/vatesfr/xenorchestra-csi:edge.Thus after editing the DaemonSet and Deployment, the pods transitioned to running.

kgp -nkube-system | grep csi* csi-xenorchestra-controller-b5b695fb-ts4b9 3/3 Running 0 4m8s csi-xenorchestra-node-27qzg 3/3 Running 0 6m21s csi-xenorchestra-node-4bflf 3/3 Running 0 6m20s csi-xenorchestra-node-8tb5m 3/3 Running 0 6m20s csi-xenorchestra-node-t9m78 3/3 Running 0 6m20s -
Just a follow-up that the PVandPVCcreation was successful.
All pods stable since previous post.
k get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE dtw-6m 2Gi RWO Retain Bound kube-system/xo-csi-test csi-xenorchestra-sc <unset> 10hk get pvc -nkube-system NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE xo-csi-test Bound dtw-6m 2Gi RWO csi-xenorchestra-sc <unset> 9hkgp -nkube-system | grep csi* csi-xenorchestra-controller-b5b695fb-ts4b9 3/3 Running 0 43h csi-xenorchestra-node-27qzg 3/3 Running 0 43h csi-xenorchestra-node-4bflf 3/3 Running 0 43h csi-xenorchestra-node-8tb5m 3/3 Running 0 43h csi-xenorchestra-node-t9m78 3/3 Running 0 43h -
Hi,
Thank you for the feedback
There was an error in the Makefile used to build the Docker image for the CSI. The name was incorrect... The fix that we pushed a month ago didn't trigger the CI

I manually ran the CI to rebuild the edge image with the correct name, which is now available at
ghcr.io/vatesfr/xenorchestra-csi-driver:edgeI delete the wrong one (
ghcr.io/vatesfr/xenorchestra-csi:edge). -

Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login