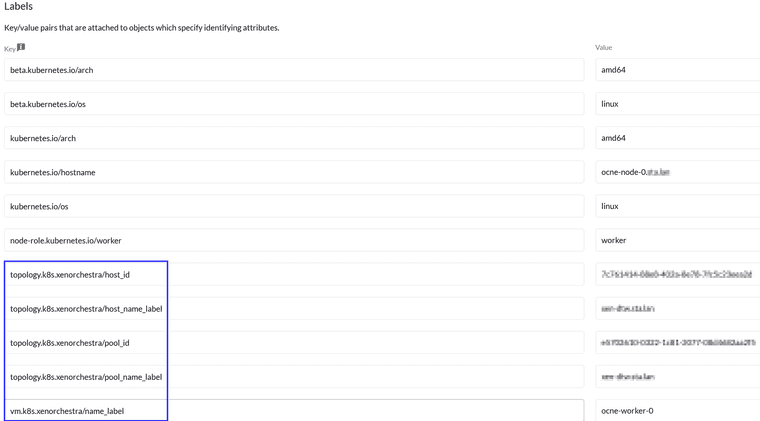
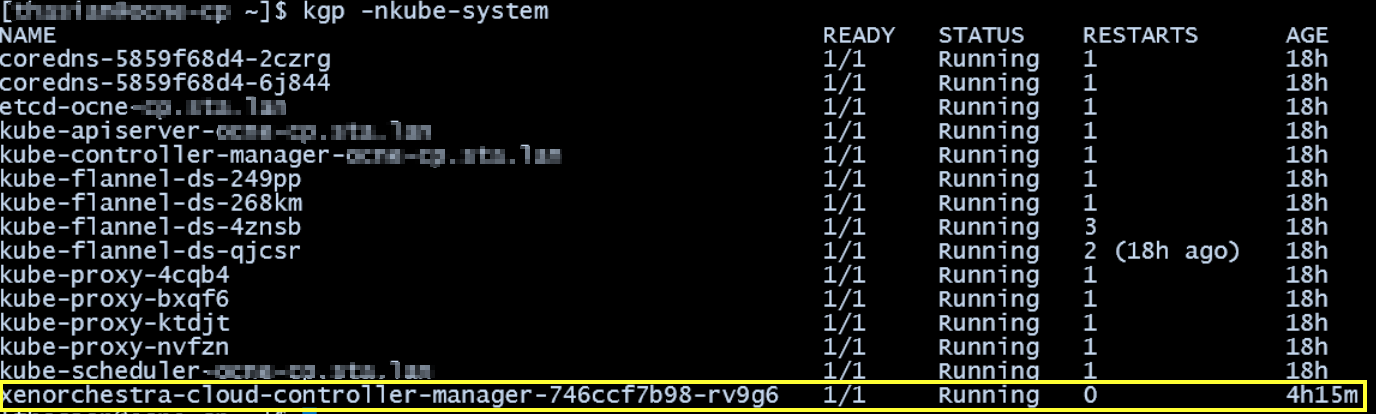
@nathanael-h
 The image pull was successful to my local computer using the same classic personal access token I generated and set as the
The image pull was successful to my local computer using the same classic personal access token I generated and set as the regcred secret.
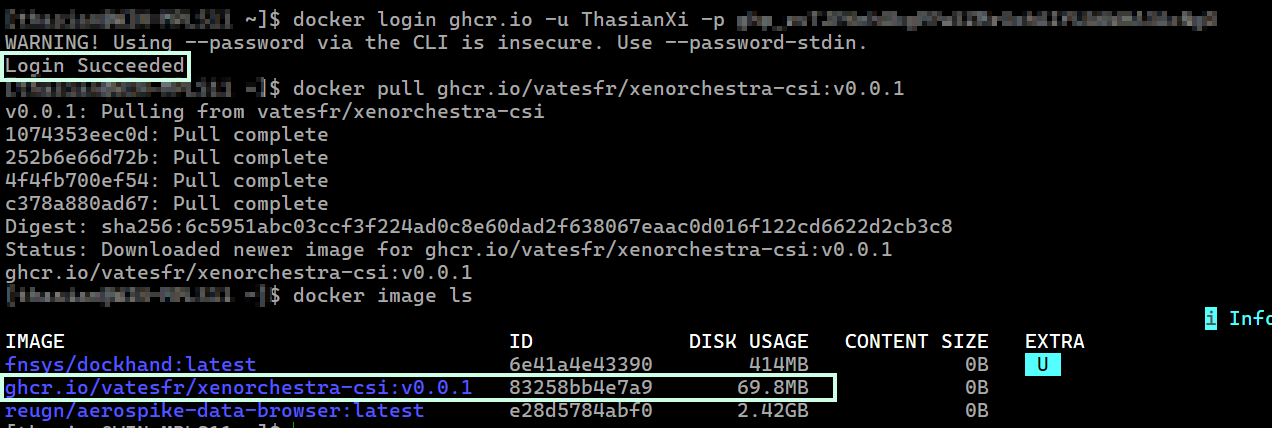

Looking at the documentation again and since I am not using MicroK8s, I tried something different but the result was the same. (the pods never transitioned to a running state).
This time, prior to executing the install script, I updated the kubelet-registration-path and the volume path in the csi-xenorchestra-node-single.yaml and csi-xenorchestra-node.yaml files.
(I believe this would be an opportunity to update the README for clarity on what to update based on the Kubernetes platform i.e. MicroK8s vs non-MicroK8s -- I can submit a PR for this, if you like)
excerpts:
- --kubelet-registration-path=/var/lib/kubelet/plugins/csi.xenorchestra.vates.tech/csi.sock
#- --kubelet-registration-path=/var/snap/microk8s/common/var/lib/kubelet/plugins/csi.xenorchestra.vates.tech/csi.sock
-------------------------
volumes:
- hostPath:
path: /var/lib/kubelet/plugins/csi.xenorchestra.vates.tech
type: DirectoryOrCreate
name: socket-dir
On the control-plane:
[root@xxxx kubelet]# pwd
/var/lib/kubelet
[root@xxxx kubelet]# tree plugins
plugins
└── csi.xenorchestra.vates.tech
kgp -nkube-system | grep csi
csi-xenorchestra-controller-748db9b45b-w4zk4 2/3 ImagePullBackOff 19 (12s ago) 41m
csi-xenorchestra-node-6zzv8 1/3 CrashLoopBackOff 11 (3m51s ago) 41m
csi-xenorchestra-node-8r4ml 1/3 CrashLoopBackOff 11 (3m59s ago) 41m
csi-xenorchestra-node-btrsb 1/3 CrashLoopBackOff 11 (4m11s ago) 41m
csi-xenorchestra-node-w69pc 1/3 CrashLoopBackOff 11 (4m3s ago) 41m
Excerpt from /var/log/messages:
Feb 18 22:21:44 xxx kubelet[50541]: I0218 22:21:44.474317 50541 scope.go:117] "RemoveContainer" containerID="26d29856a551fe7dfd873a3f8124584d400d1a88d77cdb4c1797a9726fa85408"
Feb 18 22:21:44 xxx crio[734]: time="2026-02-18 22:21:44.475900036-05:00" level=info msg="Checking image status: ghcr.io/vatesfr/xenorchestra-csi-driver:edge" id=308f8922-453b-481f-804d-3d85b489b933 name=/runtime.v1.ImageService/ImageStatus
Feb 18 22:21:44 xxx crio[734]: time="2026-02-18 22:21:44.476149865-05:00" level=info msg="Image ghcr.io/vatesfr/xenorchestra-csi-driver:edge not found" id=308f8922-453b-481f-804d-3d85b489b933 name=/runtime.v1.ImageService/ImageStatus
Feb 18 22:21:44 xxx crio[734]: time="2026-02-18 22:21:44.476188202-05:00" level=info msg="Image ghcr.io/vatesfr/xenorchestra-csi-driver:edge not found" id=308f8922-453b-481f-804d-3d85b489b933 name=/runtime.v1.ImageService/ImageStatus
Feb 18 22:21:44 xxx kubelet[50541]: E0218 22:21:44.476862 50541 pod_workers.go:1298] "Error syncing pod, skipping" err="[failed to \"StartContainer\" for \"node-driver-registrar\" with CrashLoopBackOff: \"back-off 5m0s restarting failed container=node-driver-registrar pod=csi-xenorchestra-node-btrsb_kube-system(433e69c9-2da9-4e23-b92b-90918bd36248)\", failed to \"StartContainer\" for \"xenorchestra-csi-driver\" with ImagePullBackOff: \"Back-off pulling image \\\"ghcr.io/vatesfr/xenorchestra-csi-driver:edge\\\"\"]" pod="kube-system/csi-xenorchestra-node-btrsb" podUID="433e69c9-2da9-4e23-b92b-90918bd36248"
Any other suggestions in the meantime or if I can collect more information, let me know.


 From my setup to set the
From my setup to set the