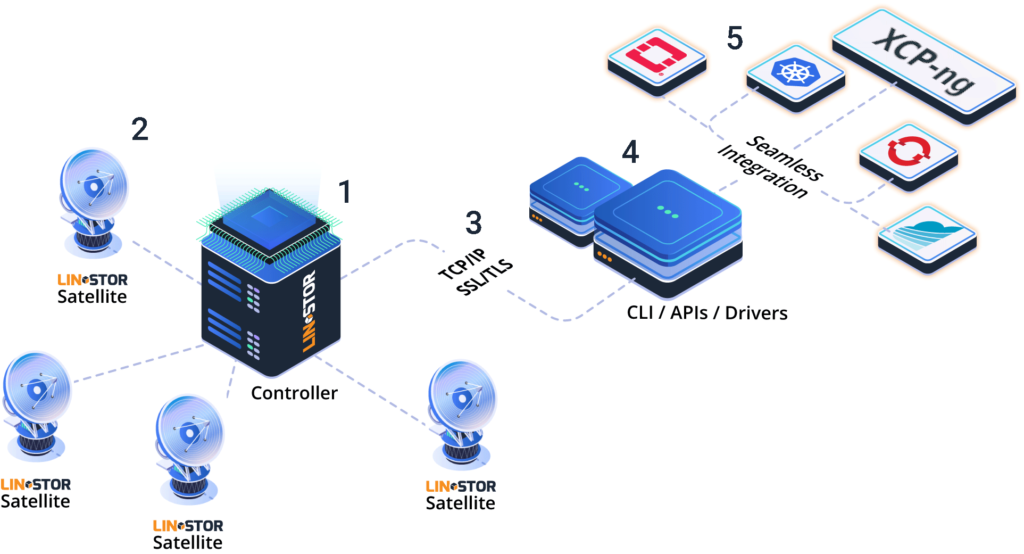
-
@olivierlambert will XOSTOR support deduplication?
-
Not yet, but I think I've read LINSTOR supports VDO, so it's possible in a future addition
")
-
@ronan-a did you test some linstor vars like:
DrbdOptions/auto-diskful': Makes a resource diskful if it was continuously diskless primary for X minutes
'DrbdOptions/auto-diskful-allow-cleanup': Allows this resource to be cleaned up after toggle-disk + resync is finishedThx for your feedback!
-
@Swen I suppose that can work with our driver. Unfortunately I haven't tested it.
It can be useful to use it, however we would have to see what impact it has on the DRBD network: for example in a bad case where we would have a chain of diskless VHDs suddenly activated on a host -
@olivierlambert
Hi,- is it possible to create more then one linstor SR in pool?
I have this error:
Error code: SR_BACKEND_FAILURE_5006
Error parameters: , LINSTOR SR creation error [opterr=LINSTOR SR must be unique in a pool],- Also, is it possible to have hybrid volume ssd+hdd (cache/autotiring) ?
-
@furyflash777 You can only use one LINSTOR SR per pool due to a limitation to share the DRBD volume database (and to start the LINSTOR controller). Why do you want many SRs?
-
hosts previous was used with VMware VSAN,
I have nvme and HDD disks in the same hosts.I am new in LINSTOR/DRBD/XOSTOR.
What will be better, use LVM on top of mdm software raid or not?
If a disk fails on one of the servers, will there be an automatic failover to the remaining replica?
Will there be a break in this case?
Will it start writing a new replica to the remaining host? -
@furyflash777 I don't recommend mixing HDDs and SSDs with our driver.
Because the replication is managed by LINSTOR, try to not use RAID. A LINSTOR replication of 3 is robust, so if you have many disks on each machine, you can aggregate them into a linear volume.
If a disk fails on one of the servers, will there be an automatic failover to the remaining replica?
As long as there is no split brain, or data corruption, you can automatically use a copy of a VDI.
")
Will it start writing a new replica to the remaining host?
It depends on the used policy but yes it is possible.
-
@ronan-a - I've been lurking on this Forum Subject for too long, and I've finally implemented the scripts across three of my hosts, and also added the "Storage" network modifications explained by @Swen and it is working beautifully. Failover is handled by XCP-ng bonded networking if a switch fails, hosts can reboot without any loss in speed or data.
You may recall several years ago I was interested in seeing CEPH implemented natively, but your LINSTOR implementation is so much simpler to manage. Thanks and keep up the good work.
-
I've also been looking at this thread for a while, I noticed there was an impending launch of an RC version of this. I am actively looking for a hyperconverged solution for the corp I am engaged with. I am looking to get off a SPOF san into a multi-node cluster. Our corp is looking to implement this change very soon (couple months) regardless of what use - but after much research this seems highly anticipated and exactly what im looking for... thank you!!
-
@Swen said in XOSTOR hyperconvergence preview:
@andersonalipio said in XOSTOR hyperconvergence preview:
Hello all,
I got it working just fine so far on all lab tests, but one thing a couldn't find in here or other post related to using a dedicated storage network other then managemente network. Can it be modified? In this lab, we have 2 hosts with 2 network cards each, one for mgmt and vm external traffic, and the second should be exclusive for storage, since is way faster.
We are using a separate network in our lab. What we do is this:
- get the node list from the running controller via
linstor node list- take a look at the node interface list via
linstor node interface list <node name>- modify each nodes interface via
linstor node interface modify <node name> default --ip <ip>- check addresses via this
linstor node listHope that helps!
Another option:
- Create additional interface
linstor node interface create <node name> storage_nic <ip>- Set preferred interface for each node
linstor node set-property <node name> PrefNic storage_nic -
@olivierlambert any update on this? thank you
-
We started to work on the initial UI
The CLI works pretty well now, so almost there We can make you a demo install inside your infrastructure if you want. -
@olivierlambert Thank you, I have many questions - is there a call/demo you could do?
-
Go there and ask for a preview access on your hardware: https://vates.tech/contact/
-
@olivierlambert Thank you for pointing that direction! I went ahead and made a request.
-
I am working for years with XenServer/Citrix Hypervisor and Citrix products like Virtual Apps.
Meanwhile I also have XCP-NG running on an test server for a while.
Well, I decided now to build a new small cluster with XCP-NG. One reason is also the XOSTOR option.This new pool is planned with 3 nodes and multiple SSD disks (not yet NVMe) in each host.
I am wondering how XOSTOR creates the LV on a VG with let's say 4 physical drives:
Will it be a linear LV? Is there any option for striping or other raid levels available/planned?Looking forward to your reply.
Thanks a lot for all the good work in a challenging environment. -
We don't need/want to have RAID levels or things like this, since it's already replicated to other hosts, this will make it too redundant. So it will be like a linear LV, yes
-
@olivierlambert thank you for the quick answer.
To be on the real safe side this means then a replication count not lower than 3 would be useful (from my perspective).What would happen if a node of a 3 node cluster with replication count 3 (so all nodes have a copy) fails?
Would everything stop because replication count is higher than available nodes?
(I refer to post https://xcp-ng.org/forum/post/54086) -
@JensH No. You can continue to use your pool. New resources can still be created and LINSTOR can sync volumes when the connection to the lost node is recreated.
As long as there is no split brain, and you have 3 hosts online, it's ok, that's why we recommend using 4 machines.
With a pool of 3 machines, and if you lose a node, you increase the risk of split brain on a resource but you can continue to create and use them.