XCP-ng 8.3 betas and RCs feedback 🚀
-
also with two 8.3 pools, i have tons of logs everywhere.
that for last 1 hour.
-
@Tristis-Oris
Pool_role.This_host_is_brokenis a bit scary, and more logs will be needed to understand how it got there. I'm trying to follow the same procedure as you to request the right lines - how exactly did you perform the master change? -
@yann pool>advanced>master.
Fresh xen installation, wait some time after joining last host, then changed master. Balancer disabled, no updates, few VMs runing on all hosts.only one thing, master change don't work at 1st attempt - just nothing happens. Looks like task been canceled , so i repeat it again after some time.
i don't think it totaly broken, maybe something happens at same time. but never got that issue before.
-
@Tristis-Oris said in XCP-ng 8.3 betas and RCs feedback
 :
:then changed master
Could you please detail that part a bit more? I understand you used XO, but which screen and which action?
-
-
@Greg_E I forgot to mention a potentially important step just before the reimage from BIOS -> UEFI.
After you've drained the host disconnect it from the pool.
so:
reimage all hosts in whatever mode they're in
migrate all VMs from the target to be changed to UEFI
disconnect said target from the pool
reimage target with UEFI boot
reconnect target to the poolnomad
-
@Tristis-Oris thanks!
I realize one thing is not clear to me: is the "unreachable master" in your situation the one you switched to, or the original master? And how many hosts in total are in this pool when you launch this operation?
The logs we'll need to analyze will be the xensource.log from the first occurrence of
designate_new_masteron both old and new master, until the time of that exception. -
@yann new one.
new part1 https://pastebin.com/ij0B7KHy
new part2 https://pastebin.com/0tQyvesY
old https://pastebin.com/dvAkEEbY -
on 8.3 pool more and more VMs became attached to Control Domain. Backups fail due VDI_IN_USE.
can't unplug vdi:
xe vbd-list vm-uuid=***
xe vbd-unplug uuid=***
The server failed to handle your request, due to an internal error. The given message may give details useful for debugging the problem.
message: Expected 0 or 1 VDI with datapath, had 5can't migrate to 8.2 pool due incompatible versions.
and already got coalesce on VM without backup.
upd
removed all stuck vdi, but sr coalesce won't move. -
@Tristis-Oris after i fixed all dom0 stuck VDIs, backup succeed once and now stuck again.
-
@Tristis-Oris very strange, your log seems to show that 2
designate_new_masterrequests were handled one after the other (at 12:11:33 and 12:12:45), both to switch to the same host - and we see in the logs that while the 1st one got all phases executed (1, 2.1, 2.2), the second one starts to have issues during "Phase 2.1: telling everyone but me to commit". Sending a second request should indeed not trigger the whole thing again, so something apparently went quite wrong, but what is indeed not obvious. -
@yann so, i don't get indication about running master change and was able to run it again.
-
@Tristis-Oris Oh OK. Had a try to run it several times myself (though on a 2-host pool), and I was able to see the operation performed twice, though apparently the second op did finish.
Running from the shell, if launch a secondxe pool-designate-new-masterwhile the first has not returned yet, it gets aDESIGNATE_NEW_MASTER_IN_PROGRESSerror, but once it has returned there seem to be a window to do strange things. -
@Tristis-Oris and with a 3-host pool I can reproduce you issue on 2nd attempt: new master loses its
xapiprocessWhen the master is changed, the
xapiservice is stopped and then restarted but something seems to get wrong this time.Among issues I realize that my former-master shows this at the time of the failing switch:
Oct 14 15:20:50 xcpng83-bzkcpvhy xsh: [ warn||0 ||xsh] TLS verification is disabled on this host: /var/xapi/verify-certificates is absent(while both other hosts do have that file)
daemon.logon new-master shows systemd desperately trying to restartxapi:Oct 14 15:20:59 xcp-ng-hqerhcgv xapi-init[1244028]: Stopping xapi: [ OK ] Oct 14 15:20:59 xcp-ng-hqerhcgv systemd[1]: Unit xapi.service entered failed state. Oct 14 15:20:59 xcp-ng-hqerhcgv systemd[1]: xapi.service failed. Oct 14 15:20:59 xcp-ng-hqerhcgv systemd[1]: xapi.service holdoff time over, scheduling restart. Oct 14 15:20:59 xcp-ng-hqerhcgv systemd[1]: Cannot add dependency job for unit lvm2-activation.service, ignoring: Unit is masked. Oct 14 15:20:59 xcp-ng-hqerhcgv systemd[1]: Cannot add dependency job for unit lvm2-activation-early.service, ignoring: Unit is masked. Oct 14 15:20:59 xcp-ng-hqerhcgv systemd[1]: Starting XenAPI server (XAPI)... Oct 14 15:20:59 xcp-ng-hqerhcgv systemd[1]: Started XenAPI server (XAPI). Oct 14 15:20:59 xcp-ng-hqerhcgv xapi-init[1244047]: Starting xapi: Oct 14 15:21:00 xcp-ng-hqerhcgv systemd[1]: xapi.service: main process exited, code=exited, status=2/INVALIDARGUMENT Oct 14 15:21:00 xcp-ng-hqerhcgv xapi-init[1244078]: Stopping xapi: [ OK ]and
xensource.logis very similar to yours. Congrats, that's a nice bug")
-
@yann yay!
")
-
Just a note to say thanks to all involved! Excellent job!
I yesterday upgraded our 8.3 release pool to 8.3 production. 2x Intel NUC11TNKi5. Running very nicely! The upgrade from release candidate with the ISO written to USB media went smoothly. Also the yum updates after the upgrade.
Now looking forward to see XO Lite be completed!
Keep up the great work! -
@Tristis-Oris I also reproduced the issue on 8.2.1, and record the issue. As for your pool left in a tricky state, would it be reasonable for you to reinstall the impacted hosts?
-
@yann yep, already reinstall it.
-
Installed in my Homelab. Install went smoothly.
Small bugs I have noticed :
1.
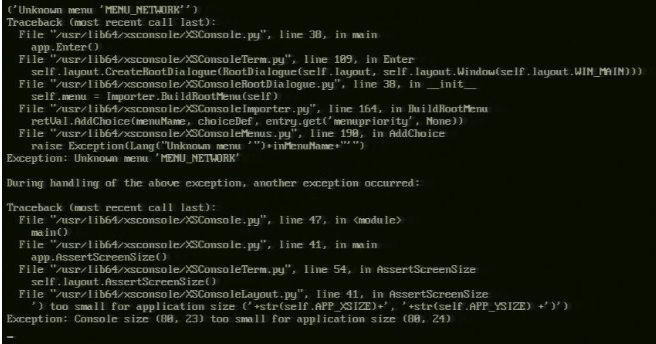
This ONLY happens when using KVM and 'scaling' the display to fit window.
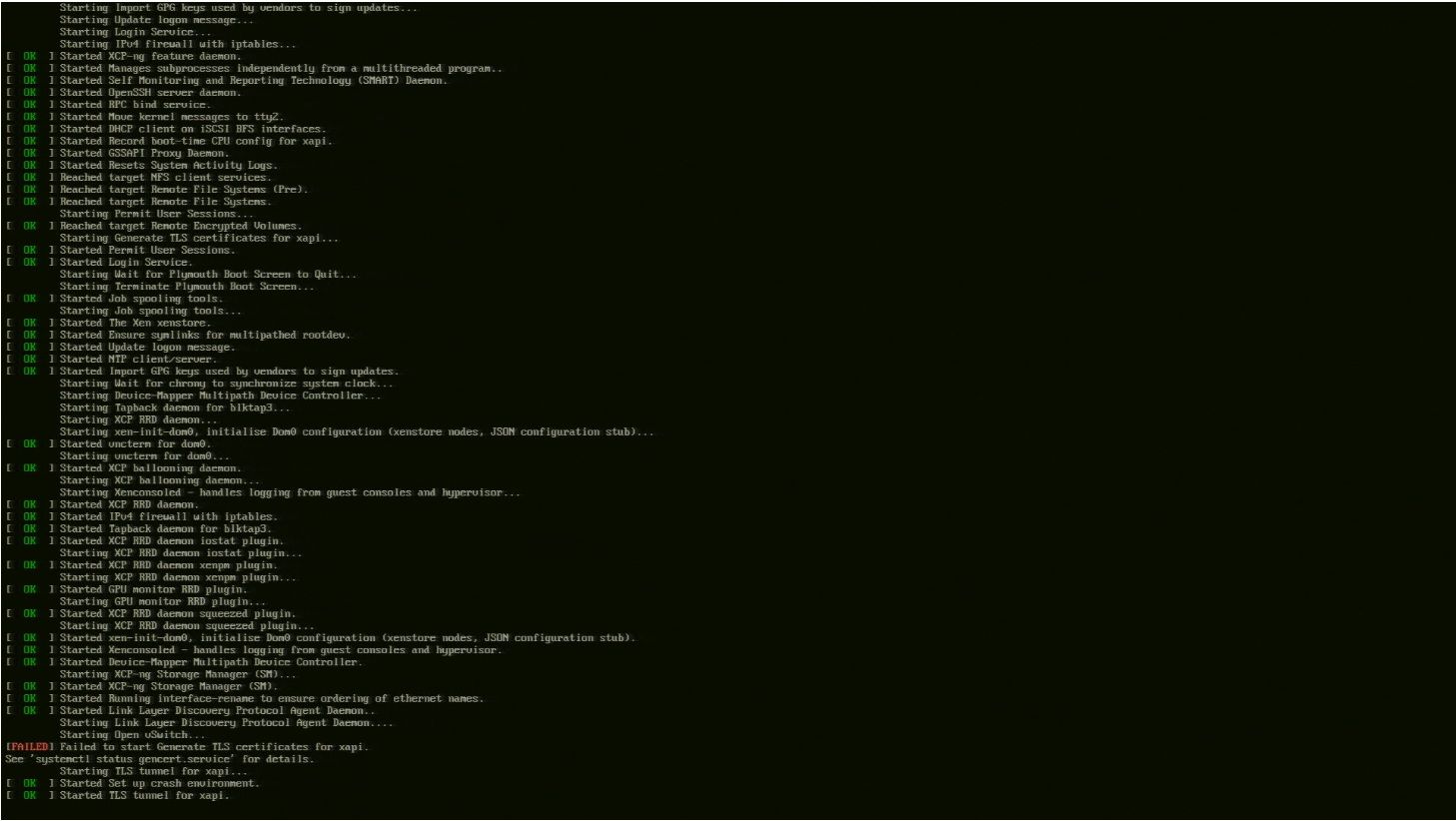
This happens ONLY on the first boot after applying patch ( 6 programs ) once release iso is installed.
This goes away from the second boot.
Everything seems to be working smoothly for now. Kudos to the Vates Team !
-
This post is deleted!