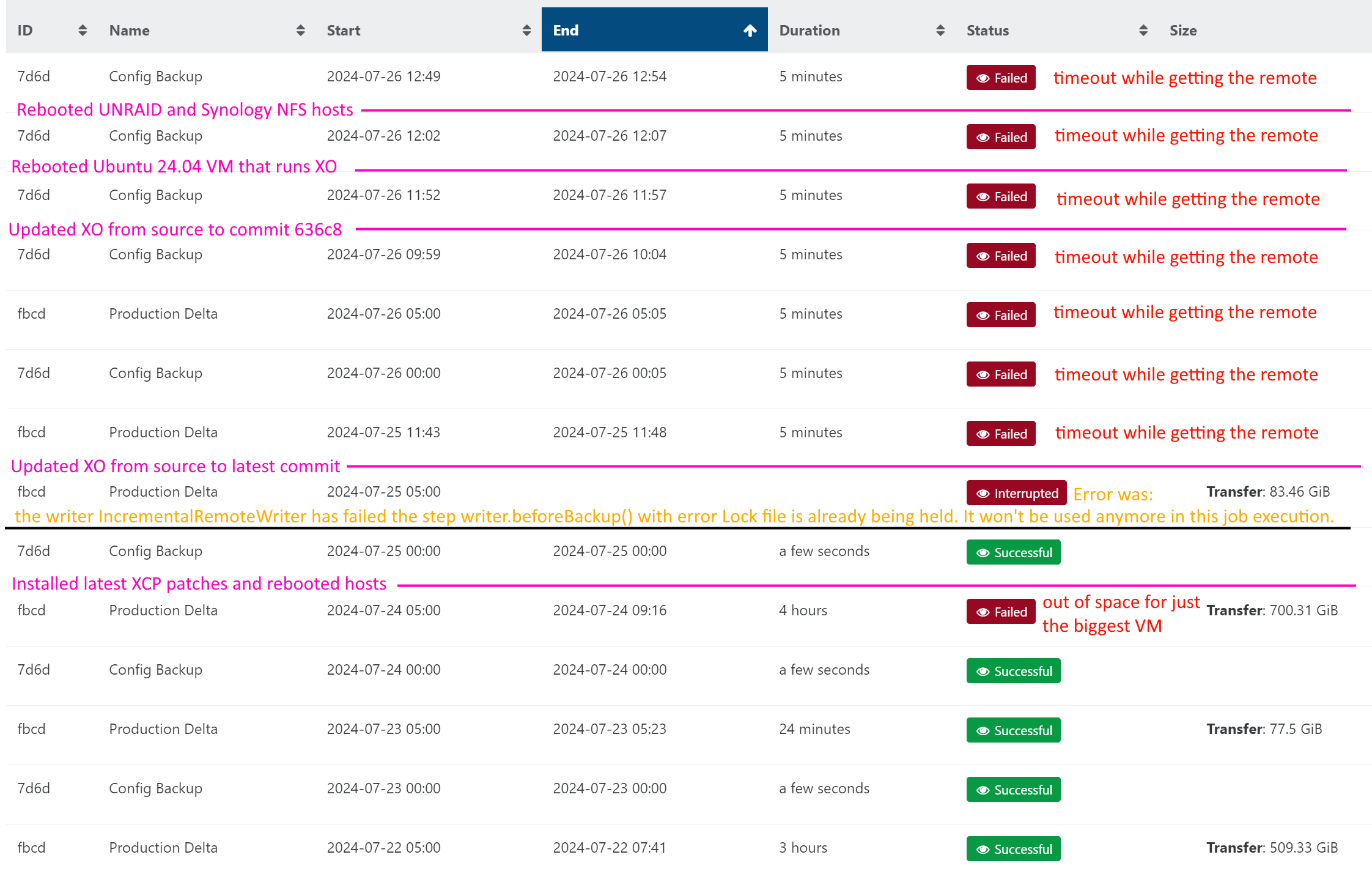
All NFS remotes started to timeout during backup but worked fine a few days ago
-
@Danp UNRAID is not so full that it can't handle some data. The array has 2.19TB free.
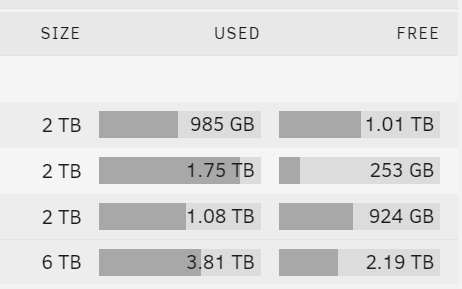
The reason I got the out of space warning is because that second drive is the target for my largest VM and despite me setting it to delete first, it still sometimes runs out of space. I wish I could set the number of retained versions on a per-remote basis. That server doesn't support drives larger than 2 TB so I'm stuck with what I have. It's set to not split folders between drives so that if I lose the array, the remaining drives would still be useful for what data they have.The Synology array is using 5.8TB of its 8.9TB so it's got plenty of space too.
I am able to mount the NFS share on both the UNRAID and the Synology from a different system. Not saying that means it has to be XO, just makes it seem that it's not necessarily the NFS share. Confused as to why one ubuntu system can mount the shares but another one that happens to be running XO times out.
Fortunately, that's not my only backup remote so I'm not unprotected right now.
-
@CodeMercenary Just a guess, but is there any NFS lock perhaps involved because of the CPU getting pegged and there being a timeout of sorts? Check the lockd daemon state, perhaps.
-
@tjkreidl I'm not sure how to determine if there is an NFS lock but the issue persisted through a reboot of both NFS hosts so I don't think it's a lock. I definitely suspected something like that with the one CPU core pegged. Just so weird that the failure started at the same time to NFS shares on two different hosts. Also, that I can mount those same shares from a different Ubuntu based system makes it seem like it's not a locked process on the hosts. The fact that I can't mount it from the SSH terminal on the XO VM makes it seem it's not specifically an XO related problem. I'm rather stumped at this point. I hate to "solve" the problem by just not using NFS from XO.
-
With some more research and experimentation today, I tried adding the NFS version to the command to mount the share from the console. For the Synology share it didn't work with version 4 but did with version 3. The UNRAID share worked with version 4. According to rpcinfo the Synolog should support version 4 but I got a
Protocol not supportedwhen I tried that. I also got aProtocol not supportedwhen I tried it without any version option.Note, last week I was not getting
Protocol not supported, it was just locking up usually without actually timing out on the client side.I adjusted the options in the remote to use the appropriate version and now they both connect and I can backup to them again.
Not sure why it always worked without the version before but suddenly needed the version option. Very strange but I'm glad it's working now. Thanks to all you who tried to help. I wish I had an idea of what when wrong so I could prevent it in the future.
-
@CodeMercenary How odd, unless the default NFS version somehow changed since it last worked and you had to specify V3 to get it to work again.
I'd contact Synology to find out if perhaps the storage unit needs a firmware upgrade to support V4? Perhaps they've had similar feedback from
other customers. -
@tjkreidl I declared victory too soon. Both backups that use NFS remotes are currently stuck in
Startingstatus. One started at over ten hours ago, and should have taken about a minute or less because it's just the config backup. Oh my, the other one started 20 hours ago. That's the manual backup I started after getting the Settings->Remotes UI to successfully test the connection with the version option.Seems the version was not the only problem. Bummer.
-
@CodeMercenary Ouch. Make sure all your servers are properly time synchronized. Can you do a showmount from your server to the NFS storage device to see if the host has access permissions?
-
@tjkreidl Interesting point about time sync. I'll look into how the UNRAID and Synology do time sync to make sure they are the same as the Ubuntu VM running XO and XCP-ng.
-
@tjkreidl I made sure UNRAID and Synology are using the same NTP server as XCP-ng. Hopefully that will help some. UNRAID was already using the same one but the Syno was using a different one.
showmount on Synology shows that XO is connected to it. UNRAID shows nothing is connected.
Both of the backup jobs still show Started status. Not sure how to fix that. I guess I'll try rebooting the XO VM.
I tried disabling NFS on the Synology then reenabled it, thinking that might break the connection XO has and get it to fail the backup job instead of it being stuck. That didn't work.
-
@CodeMercenary You could try restarting the NFS daemon. https://docs.redhat.com/en/documentation/red_hat_enterprise_linux/7/html/storage_administration_guide/s1-nfs-start#s1-nfs-start
-
@tjkreidl That would have been a good idea. However, before I left the office yesterday, I updated XO to the latest commit and decided to reboot the VM.
After the XO update the two backup jobs that had been stuck in
Startedstatus changed toInterruptedandFailed.It got hung up during the reboot. I decided to leave it alone to see if it would free up since I wanted to avoid a hard reboot. This morning it was still hung up at the same point.

Last night it had hung up on the systemd lines for probably 10 minutes or so then showed the NFS line. This morning it had not changed.
-
Since that was an NFSv4 error it means it was an issue with the UNRAID NFS server connection. I just switched that remote to v3 to see if that helps, just in case it is a specific problem with v4 on either end.
However, after the switch I clicked the button to test the remote and it's just spinning, no success or failure message after several minutes, so I have low confidence that it's going to work. I'll likely have to reboot the UNRAID server and the XO system... again.
Also trying adding these options to the remotes:
soft,timeo=15,retrans=4
Becausesoftwill make it fail rather than getting locked up andtimeoof 15 will shorten the default timeout of 30 tenths of a second a bit. Theretransdefaults to 4 but I wanted it to be clear in the options how many times it will retry (with 2x timeout for each retry).Hopefully this means it will tend to fail if the connection is unreliable instead of locking up the process.
Using
nfsstat -rcI can see that it is making a call every second with anauthrefreshfor every call. I wonder if that means it's failing authentication or if it's just doing that because the NFS is jacked up since I haven't rebooted yet. I'm guessing those calls are because of asking it to test the remote and enable the remote. I'll reboot both ends and do more testing.I might be forced to give up on using NFS for backups.
 Maybe I'll convert those same endpoints over to SMB to see how it fairs. I'll feel dirty but if it's more reliable I can probably get past that.
Maybe I'll convert those same endpoints over to SMB to see how it fairs. I'll feel dirty but if it's more reliable I can probably get past that. -
@CodeMercenary THis is unfortunate news. We ran backups over NFS successfully for years, but with Dell PowerVault units NFS-mounted on Dell Linux boxes and with XenServer hosted on Dell PowerEdge servers, so everything was Dell which probably made things more compatible.
You don't have some weird firewall or other authentication issue? And is your backup network on a separate physical network or at least a private VLAN?I will also note that some problems we had now and then were due to bad Ethernet cables! Are your network connections to the storage devices bonded or using multipath?
-
@tjkreidl I do not have the backups currently running on their own separate physical LAN or VLAN but that's in my plans. My current setup is way better than what it was with ESXi before I switched to XCP-ng but it still has a ways to go. Due to personal tragedies this summer, that work has been slowed down but I'm getting ready to separate them into VLANs now. They are all on the same side of the firewall so I don't think that would be the problem.
All my host servers are Dell PowerEdges but I don't have a SAN or any shared storage, everything is local on the servers.
Good point about the cables, maybe it's a physical problem like that. If it is then SMB likely would not help, I would assume.
No bonding so far. My servers each have two 10GB ethernet so it seems like it would be better to separate one of them for management/backups and leave the other one for VMs to use rather than bonding them. The servers also each have four 1GB ethernet that don't get used right now.
I rebooted everything and I'm currently running a backup over NFS to see if it will work. So far it seems to be proceeding. I'm hoping the new NFS options I added will help with this issue.
-
@CodeMercenary Sorry first off to hear about your personal issues. They need to take precedence.
If there is network contention, it's important that things not be impacted on backups because they utilize a lot of resources: network, memory, and CPU load.
That's why we always ran them over isolated network connections and at times of the day when in general VM ctivity was at a minimum. Make sure you have adequate CPU and memory on your hosts (run top or xtop) and also, iostat (I suggest adding the -x flag) can be very helpful is seeing if other resources are getting maxed out. -
Since the nfs shares can be mounted on other hosts, I'd guess a fsid/clientid mismatch.
In the share, always specify fsid export option. If you do not use it, the nfs server tries to determine a suitable id from the underlying mounts. It may not always be reliable, for example after an upgrade or other changes. Now, if you combine this with a client that uses
hardmount option and the fsid changes, it will not be possible to recover the mount as the client keeps asking for the old id.Nfs3 uses rpcbind and nfs4 doesn't, though this shouldn't matter if your nfs server supports both protocols. With nfs4 you should not export the same directory twice. That is do not export the root directory /mnt/datavol if /mnt/datavol/dir1 and /mnt/datavol/dir2 are exported.
So to fix this, you can adjust your exports (fsid, nesting) and the nfs mount option (to soft) , reboot the nfs server and client and see if it works.
-
@Forza That all is good advice. Again, the showmount command is a good utility that cam show you right away if you can see/mount the storage device from your host.
-
@Forza Thank you. I'll go learn about fsid and implement that. I'm very new to NFS so I appreciate the input.
I do not export it more than once, no nested exports.
I was out of the office yesterday but since making those changes the other day, the backups to UNRAID are working but the backups to the Synology array are failing with
EIO: error closeandEIO: i/o error, unlink '/run/xo-server/mounts/<guid>/xo-vm-backups/<guid>/vdis/<guid>/<guid>/.20240802T110016Z.vhd'Going to investigate that today too. That's a brand-new side quest in this adventure.
I also have a couple VMs that are failing with
VDI must be free or attached to exactly one VMbut I suspect that's due to me having to reboot the server to get the prior backup unstuck. -
@tjkreidl said in All NFS remotes started to timeout during backup but worked fine a few days ago:
@Forza That all is good advice. Again, the showmount command is a good utility that cam show you right away if you can see/mount the storage device from your host.
I do not think showmount lists nfs4 only clients. At least not on my system. For nfs4 I can see connected clients via
/proc/fs/nfsd/clients/Debug logging on a Linux nfs server can be controlled with
rpcdebug. To enable all debug output for the nfsd you can userpcdebug -m nfsd all. Though on the Unraid/Synology it might be different.In dmesg it would look like this:
[465664.478823] __find_in_sessionid_hashtbl: 1722337149:795964100:1:0 [465664.478829] nfsd4_sequence: slotid 0 [465664.478831] check_slot_seqid enter. seqid 4745 slot_seqid 4744 [465664.478928] found domain 10.5.1.1 [465664.478937] found fsidtype 7 [465664.478941] found fsid length 24 [465664.478944] Path seems to be </mnt/6TB/volume/haiku> [465664.478946] Found the path /mnt/6TB/volume/haiku [465664.478994] --> nfsd4_store_cache_entry slot 00000000e3c4c7e5 -
I used
exportfs -von UNRAID to look at the share options, without changing anything first, and they were set to:
(async,wdelay,hide,no_subtree_check,fsid=101,sec=sys,rw,secure,root_squash,no_all_squash)So,
fsidwas already being used.The UNRAID remote has worked the last couple days, since I set
soft,timeo=15,retrans=4. I'm curious to see how it does over the weekend.I'm having trouble getting the VDIs detached from dom0.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login