XCP-ng 8.3 updates announcements and testing
-
@flakpyro
I'm good now! -
Updated around 43 hosts without issue.
-
I'm doing the latest production level updates announced yesterday... My pool has never migrated VMs as fast as it is now.
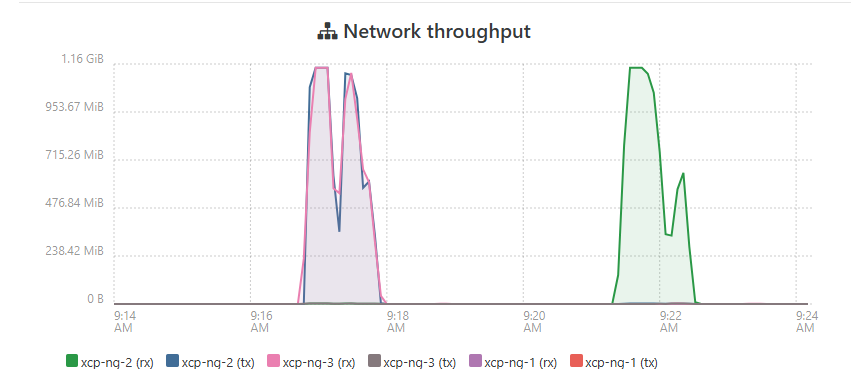
That was migrating several at a time, moving VMs back to "balanced" at the end is moving them at about half that speed one at a time. This is more than double what I was able to do with the same hardware on 8.2.1. It looks like it is actually capping at the maximum 10gbps speeds that the x710 cards and my switch can handle, that's never happened, not even on my lab which has been on v8.3 for over a year.
(note to self, might be time to upgrade those x520 cards in the lab to x710)
Next month's Windows updates might be interesting, hope this increase holds for that process too.
-
This post is deleted! -
said in XCP-ng 8.3 updates announcements and testing:
@gduperrey I wonder why now I have to run those commands on my hosts each time for the updates to show:
yum clean all rm -rf /var/cache/yumNot fun
@gduperrey Can you explain why this is happening and how to get updates showing automatically again?
-
@manilx said in XCP-ng 8.3 updates announcements and testing:
yum clean all
I can't explain it. I can't say what's going on on your system, especially with so little information.
Personally, I run the following commands all the time:
yum clean metadata ; yum updateI very rarely need to use
yum clean all, and I don't remember having to do an additionalrm. And yet, I run the above commands a lot during testing campaigns. -
@gduperrey said in XCP-ng 8.3 updates announcements and testing:
yum clean metadata ; yum update
OK, I'll try this next time.
P.S I've updated the 2 hosts via XO all teh time from 8.3 beta. Always showed patches available in XO. Started with the previous 8.3 updates that they didn't show and I had to run those commands.
-
@manilx We recently upgraded our Koji build system. This may have caused disruptions in this recent update release yesterday, where an XML file was generated multiple times. This has now been fixed and should not happen again. This may explain the issue encountered this time, particularly with the notification of updates via XO.
Note that normally yum metadata expires after a few hours and so it should normally return to normal on its own.
-
New update candidates for you to test!
A new batch of non-urgent updates is ready for user tests before a future collective release. Below are the details about these.
Maintenance updates
blktap: Fix a bad integer conversion that interrupts valid coalesce calls on large VDIs. This fixes an error that could occur on VHD coalesces, generating logs on the SMAPI side.kernel:- Fix compatibility issues with Minisforum MS-A2 machines. For more information, you can consult this forum post.
- Backport fix for CVE-2020-28374, a vulnerability that is unlikely to be exploitable in XCP-ng, fixed as defence-in-depth.
xapi&xen:- Add a new
/etc/xenopsd.conf.ddirectory, in which users can add a.conffile with configuration values for xenopsd. - Patch Xen to support a new option allowing to activate the remapping of grant-tables as Writeback. This fixes a performance issue for Linux Guests on AMD processors. Guests need their kernel to support the feature which enables this fix (Linux distributions that have recent enough kernels or apply fixes from the mainline LTS kernels are OK. Older ones are not. Some currently supported LTS distros don't have the patch yet: RHEL 8 and 9 and their derivatives are not ready yet - no effect on older distros such as Ubuntu 20.04. See partial list below). Windows and *BSD guests were not affected by the performance problem this change solves.
- While we are confident with this change, we decided to make it opt-in at first, so that users be conscious of the change and also know how to revert it if any side effects remain in edge cases. To enable the fix pool-wide, create a file named
/etc/xenopsd.conf.d/custom.confwith the following line:xen-platform-pci-bar-uc=false- Then restart the toolstack on the host:
xe-toolstack-restart - Then add the configuration and restart the toolstack on every other hosts of the pool
- Then stop and start VMs so that the setting is applied to them at boot.
- Then restart the toolstack on the host:
- In a future update, this will become the default.
- This is not the end of the way towards better performance on AMD EPYC servers, but it's significant progress!
- Add a new
xo-lite:- [Host/VM/Dashboard] Fix display error due to inversion of upload and download
- [Sidebar] Updated sidebar to auto close when the screen is small
- [SearchBar] Updated query search bar to work in responsive (PR #8761)
- [Pool,Host/Dashboard] CPU provisioning considers all VMs instead of just running VMs
- For more details, we invite you to read the blog post about the latest Xen-Orchestra update.
OS support for the AMD performance workaround:
- Debian: 11 (5.10: TODO), 12 (6.1: OK)
- Ubuntu: 20.04 LTS (5.4: EOL), 22.04 LTS (5.15: SOON, HWE 6.8: OK), 24.04 LTS (6.8 & HWE 6.14: OK)
- openSUSE Leap, 15.5 (5.14: EOL) 15.6 (6.4: OK)
- SUSE Enterprise (LTSS) : SLE15 SP3 - LTSS (5.3: Not upstream), SLE15 SP4/5 - LTSS (5.14: Not upstream), SLE15 SP6+ (OK)
- RHEL (+derivates): 8 (4.19: EOL-ish?), 9 (5.14: Not upstream), 10 (6.12: OK)
- Fedora: All supported: OK (37+)
- Alpine Linux: All supported: OK (v3.18+)
- EOL = distro is EOL
- Not upstream = not covered by Linux stable project (i.e probably needs discussions with distro)
- SOON: Distro needs to update its kernel
Test on XCP-ng 8.3
yum clean metadata --enablerepo=xcp-ng-testing yum update --enablerepo=xcp-ng-testing rebootThe usual update rules apply: pool coordinator first, etc.
Versions:
blktap: 3.55.5-2.3.xcpng8.3kernel: 4.19.19-8.0.38.4.xcpng8.3xapi: 25.6.0-1.11.xcpng8.3xen: 4.17.5-15.2.xcpng8.3xo-lite: 0.13.1-1.xcpng8.3
What to test
Normal use and anything else you want to test.
Test window before official release of the updates
None defined, but early feedback is always better than late feedback, which is in turn better than no feedback
")
-
Updated both of my test hosts.
Machine 1:
Intel Xeon E-2336
SuperMicro board.Machine 2:
Minisforum MS-01
i9-13900H (e-cores disabled)
32 GB Ram
Using Intel X710 onboard NICEverything rebooted and came up fine. None of my test systems are AMD based at the moment!
-
I don’t have AMD based hosts for XCP-ng. However may I suggest an additional validation test of this change, against Debian 13 when stable is released during or following tomorrow. I recon it should work - newer Linux Kernel version 6.12 series, though can’t be sure! Best check to avoid nasty surprises.
-
@john.c said in XCP-ng 8.3 updates announcements and testing:
I don’t have AMD based hosts for XCP-ng. However may I suggest an additional validation test of this change, against Debian 13 when stable is released during or following tomorrow. I recon it should work - newer Linux Kernel version 6.12 series, though can’t be sure! Best check to avoid nasty surprises.
The performance fix support is related to the kernel version. All kernel >= 5.19 work with it (or that have https://lore.kernel.org/all/20220530082634.6339-1-jgross@suse.com/), this includes Debian 13.
-
@gduperrey Updated and running. Single hosts were fine. No AMD testing.
Upgrading a busy pool seems to have had some odd issues with VM migration, but all seems to be running fine now. I had upgraded the pool from 8.2.1 to 8.3 last month and everything has been fine. This time (after rebooting pool master) while trying to migrate guests so I could reboot hosts got a few XO errors like:
xo:api WARN admin | vm.migrate(...) [1s] =!> XapiError: INTERNAL_ERROR(Object with type VM and id bd38ee46-2701-3022-ec61-03bf3ffbdcc9/config does not exist in xenopsd) xo:api WARN admin | vm.migrate(...) [2s] =!> XapiError: INTERNAL_ERROR(Object with type VM and id 235de1d7-832e-f1a7-fa1c-a45877aab8f6/config does not exist in xenopsd)It was only a few on one host. I can NOT confirm this is related to the updates as I'm not having problems now. After manually rebooting the host and stuck guests, things were ok again.
-
Updated and enabled (but on an Intel machine so far). I think I will enable it on our prod with the new config, this won't hurt
(full EPYC) -
Installed on a 2 Node pool consisting of 2
HP EliteDesk 300 G3 Mini with- 1x i7 6700T & 1x i5 6500T
- 32GB RAM each
- NFS VM SR
- iSCSI VM SR
- various SMB ISO SR
VMs migrated during reboot withput issues, also no issues with migration after updates completed with all nodes rebooted. Alos no issues found with VMs. Primarily AlmaLinux 9 and FreeBSD 13.
-
First of all ...... a BIG THANK YOU for this patch !
Tested on Minisforum AMD 7945HX based pc; and I can confirm that XCP-ng boots with ACPI PSS & C Cores as mentioned in this post and it works with both options enabled.
So excited that I have tested this only and replied before testing other things..

UPDATE :
While updating this, I actually had to do 2 updates (last stable update patch of 7 files + this one)After this installation, GPU (Nvidia) passthrough completely seems to be broken. Before the update(s) the host had to be turnoff completely, power cable had to be removed and then replugged to reset the graphics card (which used to work as I was able to run the card); but now attaching the graphics card to VM makes the VM hang on VM boot and at times, the host is also abruptly restarted (as if someone as pressed the HW reset button).
I am not sure whether the problem is in this update or the last stable one; but graphics card reset for Nvidia ( I think it has to do with ACPI reset ) still remains a problem.
Would be great if you guys can look into this.
-
Updated on our prod cluster, works very well (full EPYC)
-
@gduperrey I updated my little AMD Ryzen 5 5600U (Zen3) and it's running great!
As for the important VM to VM network performance, using Debian 13 and iperf3 single thread, before (update not enabled) is about 7.2-8Gb/sec. After the update (xen-platform-pci-bar-uc=false) I get about 10.1-13Gb/sec. So that's about a 40-60% improvement. This brings it in line with similar small Intel systems.
I did not see any change (or problem) setting it on my small test Intel system (getting about 10.1-10.8Gb/sec).
FYI: Remember, after the config change and
xe-toolstack-restart, restart the VMs! -
Yeah I had to stop then start the VM to enjoy the new performance. On my end, iperf (not iperf3) bring even more perf on my setup, especially with multiple threads (-P4 and -P8 gave more than 100% boost)
-
New update candidate for you to test!
A new non-urgent update is ready for user testing before a future collective release. Below are the details.
A bug was found in the Emergency Network Reset due to desynchronisation between
xsconsoleand XAPI. This issue prevented the Emergency Network Reset from working at all. This update includes the fixes from the upstreamxsconsoleproject to fix it.
Maintenance updates
xsconsole- Backport sync of network reset trigger file path with XAPI to fix emergency network reset
- Backport fix for pool.conf IPv6 to avoid IPv6 truncation
Test on XCP-ng 8.3
yum clean metadata --enablerepo=xcp-ng-testing yum update --enablerepo=xcp-ng-testing rebootReboot is not strictly necessary, but the
xsconsoleinstance running on the first virtual terminal of your host won't be restarted otherwise. If you do not reboot, make sure to startxsconsolefrom another terminal after the update.The usual update rules apply: pool coordinator first, etc.
Versions:
xsconsole: 11.0.8-1.2.xcpng8.3
What to test
Normal xsconsole usage, is still useful feedback. However, if possible, the most helpful test would be performing an Emergency Network Reset through
xsconsole, making actual configuration changes and verifying that they are correctly applied after reboot.Test window before official release of the updates
None defined, but early feedback is always better than late feedback, which is in turn better than no feedback