S
Offline
Posts
-
RE: XCP-ng 8.3 updates announcements and testing
Temps seem to be working on i5-10500T:
[11:46 delta-2 ~]# xenpm get-core-temp Package0: 57°C CPU0: 56°C CPU2: 57°C CPU4: 56°C CPU6: 56°C CPU8: 55°C CPU10: 57°C
As this is my first time installing these update candidates, is there no other action required after doing:
yum clean metadata --enablerepo=xcp-ng-testing,xcp-ng-candidates yum update --enablerepo=xcp-ng-testing,xcp-ng-candidates rebootMeaning I am not permanently in testing mode now? Next yum update should just pull the latest stable versions?
-
RE: Gather CPU utilization of host as variable for prometheus exporter
Yay! Santa came early this year!!
-
RE: Is it possible yet to select a specific network adapter for Backups?
Is this possible now? I can only see the management NIC.
-
RE: Gather CPU utilization of host as variable for prometheus exporter
I was about to link Mike's work here, but wanted to say how we desperately need a metrics system that would be exposed from a centralized location. There's no way in hell I'm giving a docker host credential access to the hypervisor it resides on (and all the other hypervisors) - on the other hand, if the metrics were exposed only via XO and limited in terms of where these metrics could be accessed from, now that would be a sold implementation.
-
Just an idea :) - (SATA controller passthrough)
Hey, since I'm running TrueNAS virtualized, I wanted to passthrough the SATA controller.
This led me to a journey of updating to 8.3, just so I could do it through xen orchestra, which I did. After I toggled the controller, the system restarted and all of a sudden xcp-ng didn't want to boot. It was stuck in the dracut emergency shell.
I had absolutely no idea why, until I realized the system itself is on a SATA SSD, and not an m.2 drive.
I had to manually change the grub config for it to be able to boot to the main config again, which was a bit stressful.
Anyways, my idea, just adding a little popup warning, or something similar that this could happen if users have xcp-ng installed on a SATA drive, just to prevent future headaches for homelabbers such as myself, but in reality, it could happen to anyone.
-
RE: Xen Orchestra Prometheus Backup Metrics?
Good things take time.
Your team is doing god's work.
Remember to stay healthy, in both mind and body! -
RE: Xen Orchestra Prometheus Backup Metrics?
Got it, thanks!
I'm certain many if not all enterprise users would be interested in such a feature. -
RE: Xen Orchestra Prometheus Backup Metrics?
@olivierlambert That's where my question comes in
")
Any plans on having these exposed for monitoring in Grafana?
-
RE: Xen Orchestra Prometheus Backup Metrics?
@olivierlambert Could you confirm please if netdata provides such metrics? ^
-
RE: Xen Orchestra Prometheus Backup Metrics?
@olivierlambert Just to confirm, I want to look at the size of daily backups created by Xen Orchestra, and the time/speed it took for them to complete, basically this page, but on a graph:
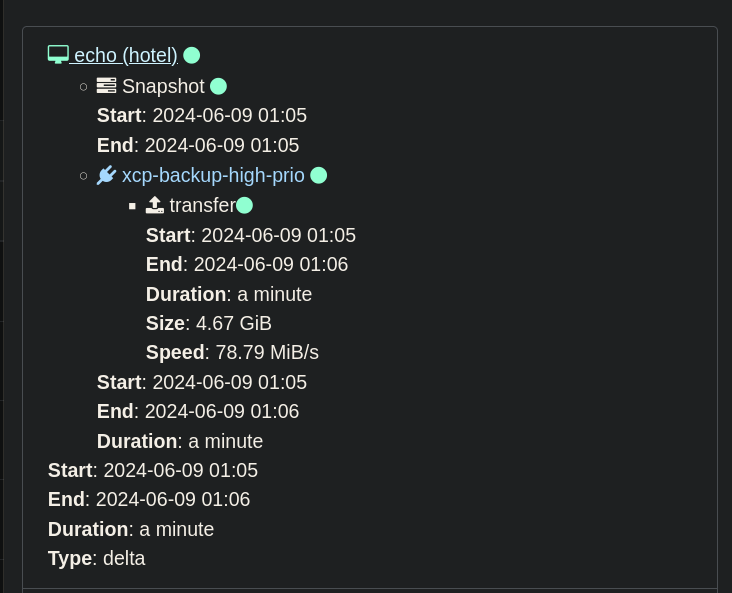
I'm not sure that is something netdata can offer?
-
Xen Orchestra Prometheus Backup Metrics?
Any plans on having these exposed for monitoring in Grafana?
I would really much like to see a graph which would correlate backup length, backup size, per VM, per Job, etc.
-
cleanVm: incorrect backup size in metadata
cleanVm: incorrect backup size in metadata path "/xo-vm-backups/db8b6e5f-6e3a-e919-f5c1-d097f46eb259/20240321T000510Z.json" actual 21861989376 expected 21861989888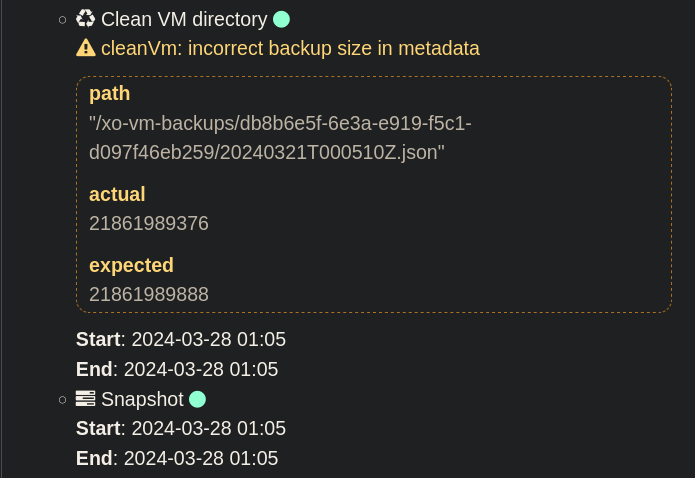
I've been having this warning for 3~ months, on all my VMs.
At first the difference was just a few bytes (if those are bytes), but now the difference seems to be growing.Running XO from the sources, updated multiple times during those 3 months, and also updated yesterday, same warning still occurred during last night's backup.
Any ideas how to get rid of this?
-
NDB Connections per Disk?
Hi,
I do not understand what this setting does.
To tailor the backup process to your specific needs and infrastructure, you can adjust the number of NBD connections per exported disk. This setting is accessible in the Advanced backup job section and allows for further customization to optimize performance according to your network conditions and backup requirements:More connections = faster backup? What's the trade-off?
-
RE: Error: Connection refused (calling connect ) (XCP-ng toolstack hang on boot)
@olivierlambert I do.
I have also noticed something extremely weird.
I have 3 HDDs attached to one host.
2x2TB raid 1 (software raid done on the XCP-ng host)
1x4TBlsblkshows:... SNIP ... sda 8:0 0 1.8T 0 disk ├─sda2 8:2 0 1.8T 0 part └─sda1 8:1 0 2G 0 part ... sdb 8:16 0 1.8T 0 disk ├─sdb2 8:18 0 1.8T 0 part └─sdb1 8:17 0 2G 0 part └─md127 9:127 0 2G 0 raid1 ... sde 8:64 0 3.7T 0 disk ├─sde2 8:66 0 3.7T 0 part └─sde1 8:65 0 2G 0 part └─md127 9:127 0 2G 0 raid1All 3 disks are passed through to a TrueNAS VM on the host, and all the data is properly stored, but I have no idea why mdadm shows that the 4TB disk is part of the raid, instead of the other one?
/dev/md127: Version : 1.2 Creation Time : Sun Aug 27 14:32:08 2023 Raid Level : raid1 Array Size : 2094080 (2045.00 MiB 2144.34 MB) Used Dev Size : 2094080 (2045.00 MiB 2144.34 MB) Raid Devices : 2 Total Devices : 2 Persistence : Superblock is persistent Update Time : Sun Oct 8 12:07:28 2023 State : clean Active Devices : 2 Working Devices : 2 Failed Devices : 0 Spare Devices : 0 Consistency Policy : resync Name : november:swap0 UUID : ae045fa0:74b00896:3134ede5:c837bec3 Events : 27 Number Major Minor RaidDevice State 0 8 65 0 active sync /dev/sde1 1 8 17 1 active sync /dev/sdb1Anyways, this doesn't seem to be the issue, since the other host which has no HDDs attached, only m.2 VM SR's, and it also took exactly 10 minutes for the toolstack to go up.
Now XO can't reach any of the hosts, even though all the VMs are up.
-
RE: Error: Connection refused (calling connect ) (XCP-ng toolstack hang on boot)
@olivierlambert Ah, I understand the naming convention now.
So XO, but XO is irellevant to this issue. The problem was the 10 minutes it took the toolstack to boot up, compared to the 1-2 minutes it always took.
I updated XCP-ng now, rebooted, and both hosts took 10 minutes for the stack to come up again. Any ideas what could be causing this delay and how we could troubleshoot it?
-
RE: Error: Connection refused (calling connect ) (XCP-ng toolstack hang on boot)
@olivierlambert Sorry for the delay, I'm not receiving emails for replies here, for some reason.
I'm using XO from the sources
Xen Orchestra, commit 3c047 xo-server 5.124.0 xo-web 5.126.0XCP-ng was fully up to date when issues occurred, I do have a few updates pending now, but haven't rebooted since the issue:
software-version (MRO) : product_version: 8.2.1; product_version_text: 8.2; product_version_text_short: 8.2; platform_name: XCP; platform_version: 3.2.1; product_brand: XCP-ng; build_number: release/yangtze/master/58; hostname: localhost; date: 2023-08-09; dbv: 0.0.1; xapi: 1.20; xen: 4.13.5-9.36; linux: 4.19.0+1; xencenter_min: 2.16; xencenter_max: 2.16; network_backend: openvswitch; db_schema: 5.603 `` -
Error: Connection refused (calling connect ) (XCP-ng toolstack hang on boot)
Hi, I use a startup script that starts VMs in a specific order, every time my main and single XCP-ng host is restarted.
The past few days I've been getting random failures, where at first the XOA VM just loses connectivity to the host toolstack, even though all VMs are up and the host is functional (I can ssh in).
The script was configured like this:
#!/bin/bash # xe vm-list for name-label, add in start order vms=(vm1 vm2 vm3 etc...) wait=30s # No need to modify below initwait=3m vmslength=${#vms[@]} log=/root/scripts/startup.log start_vm () { echo -n "[$(date +"[%Y-%m-%d %H:%M:%S]")] Starting $1 ... " >> ${log} /opt/xensource/bin/xe vm-start name-label=$1 if [ $? -eq 0 ] then echo "Success" >> ${log} else echo "FAILED" >> ${log} fi # Wait if not the last vm if [ "$1" != "${vms[${vmslength}-1]}" ] then echo "Waiting ${wait}" >> ${log} sleep ${wait} fi } echo "[$(date +"[%Y-%m-%d %H:%M:%S]")] Running autostart script (Waiting ${initwait})" > ${log} sleep ${initwait} for vm in ${vms[@]} do start_vm ${vm} done echo "[$(date +"%T")] Startup complete." >> ${log} echoAs you can see the initwait is set to 3m, having the script wait for the XCP-ng toolstack to get ready, and I've had no issues with this config for the past year.
Now I have noticed that the toolstack takes about 10 minutes to start, where it took about 2 beforehand. I have no idea what's going wrong because I didn't do any updates in the meantime.
Does anyone have an idea where I should look to see what's causing this 10 minute hang?
Even after rebooting the host, after the XOA VM is up, it can't connect to the toolstack for some reason:
connect ETIMEDOUT host-ip:443Update: the XOA error is due to a kernel issue. 5.10.0-25-amd64 works, 5.10.0-26-amd64 cannot connect to any XCP-ng host. This still leaves me wondering why the XCP-ng host toolstack startup time has increased so drastically.
-
RE: Which networks require NBD to benefit from faster backups?
@olivierlambert Understood, thank you.
So I don't need to enable NBD on all my VMs, although I'm curious is there any drawback or perhaps positive sides of enabling NBD for every network?