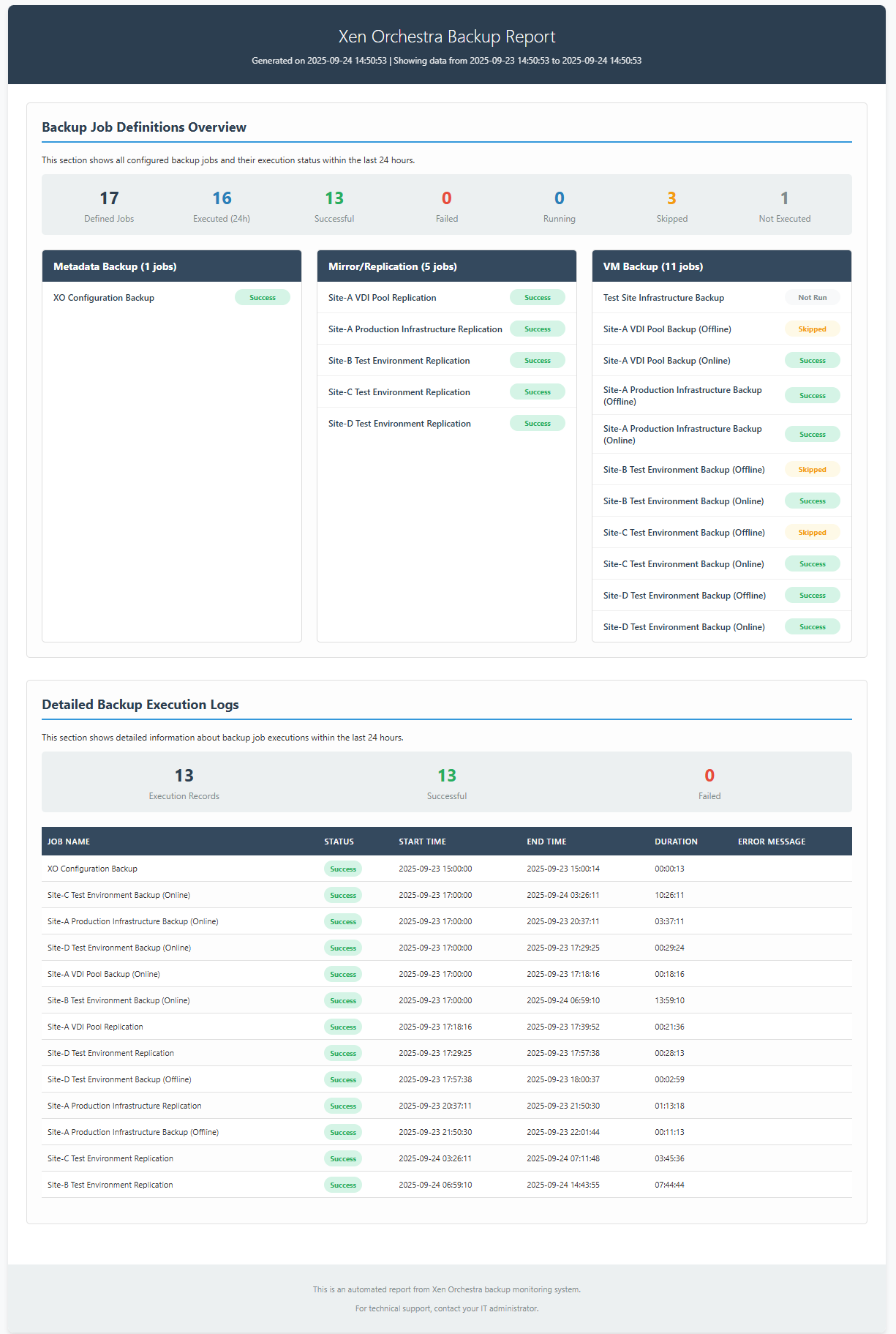
Sorry in advance for the long-winded post but I am experiencing some long backup times and trying to understand where the bottleneck lies and if there’s anything that I could change to improve the situation.
We’re currently using backups through the XOA, backing up to remotes on a Dell Data Domain via NFS. The backup is configured to use an XOA backup proxy for this job to keep the load off of our main XOA.
As an example we have a delta backup job configured for a pool and it backs up about 100 VMs. We have our concurrency set to 16, we use NBD and changed block tracking and we merge backups synchronously. The last backup for this job took 15 hours and moved just over 2 TiB of data.
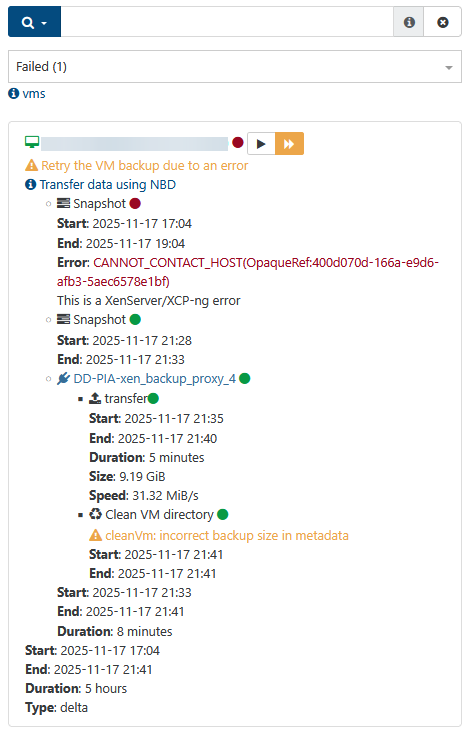
After examining the logs from this backup (downloading the json and converting to excel format for easier analysis) I found that there are 4 distinct phases for each VM backup: an initial clean, a snapshot, a transfer and a final clean. I have also found that the final clean phase takes by far the most amount of time on each backup.
The Initial Clean Duration time for each server was typically somewhere between a couple seconds and 30 seconds.
The Snapshot Duration was somewhere between 2-10 minutes per VM.
The Transfer Duration varied between a few seconds and around 30 minutes.
The Final Clean Duration however was anywhere between 25 minutes on the low end to almost 5 hours on the high end. The amount of time that this phase took was not proportional to the disk size of the vm being backed up or the transfer size for the backup. I found 2 VMs, each with a single 100GB hard disk and both moved around 20GB of changed data. One of them experienced a Final Clean Duration of 30 minutes and the other was 4 hours and 30 minutes in the same backup job.
We also have a large vmware infrastructure and use Dell Power Protect to backup the VMs there to the same Data Domain and we do not see similar issues with backup times in that system. So that got me thinking what the differences were between them and how some of those differences might be affecting the backup job duration.
One of the biggest differences that I could come up with was the fact that Power Protect uses the DDBoost protocol to communicate with the Data Domains whereas we had to create NFS exports from the Data Domain to use as backup remotes in Xen Orchestra.
Since DDBoost uses client side deduplication it significantly cuts down on the amount of data transferred to the Data Domain. But our transfer time wasn’t the bottleneck here, it was the final clean duration time.
This led me to investigate what is actually happening during this phase and please correct me if I’m wrong but it seems like when XO performs coalescing over NFS after the backup:
The coalescing process reads each modified block from the child VHD and writes it back to the parent VHD.
Over NFS, this means:
Read request travels to Data Domain
Data Domain reconstructs the deduplicated block (rehydration)
Full block data travels back to the proxy (or all the way back to the the xcp-ng host, I’m not entirely sure on this one)
xcp-ng processes the block
Full block data travels back to Data Domain
Data Domain deduplicates it again (often finding it's duplicate)
So it seems that the Data Domain must constantly rehydrate (reconstruct) deduplicated data for reads, only to immediately deduplicate the same data again on writes.
With DDBoost, it seems like this cycle doesn't happen because the client already knows what's unique.
So it seems that each write during coalescing potentially triggers:
Deduplication processing
Compression operations
Copy-on-write overhead for already deduplicated blocks
This happens for every block during coalescing, even though most blocks haven't actually changed.
So I guess I have a few questions. Is anyone else using NFS to a Data Domain as a backup target for backups in Xen Orchestra and if so have you seen the same kind of performance?
For others that backup to a target device that doesn’t handle inline dedup and compression do you see the same or better performance from your backup job times?
Does Vates have any plans to incorporate the DDBoost library as an option for the supported protocols when connecting a backup remote?
Is there any expectation that the qcow2 disk format could help with this at all vs vhd format?