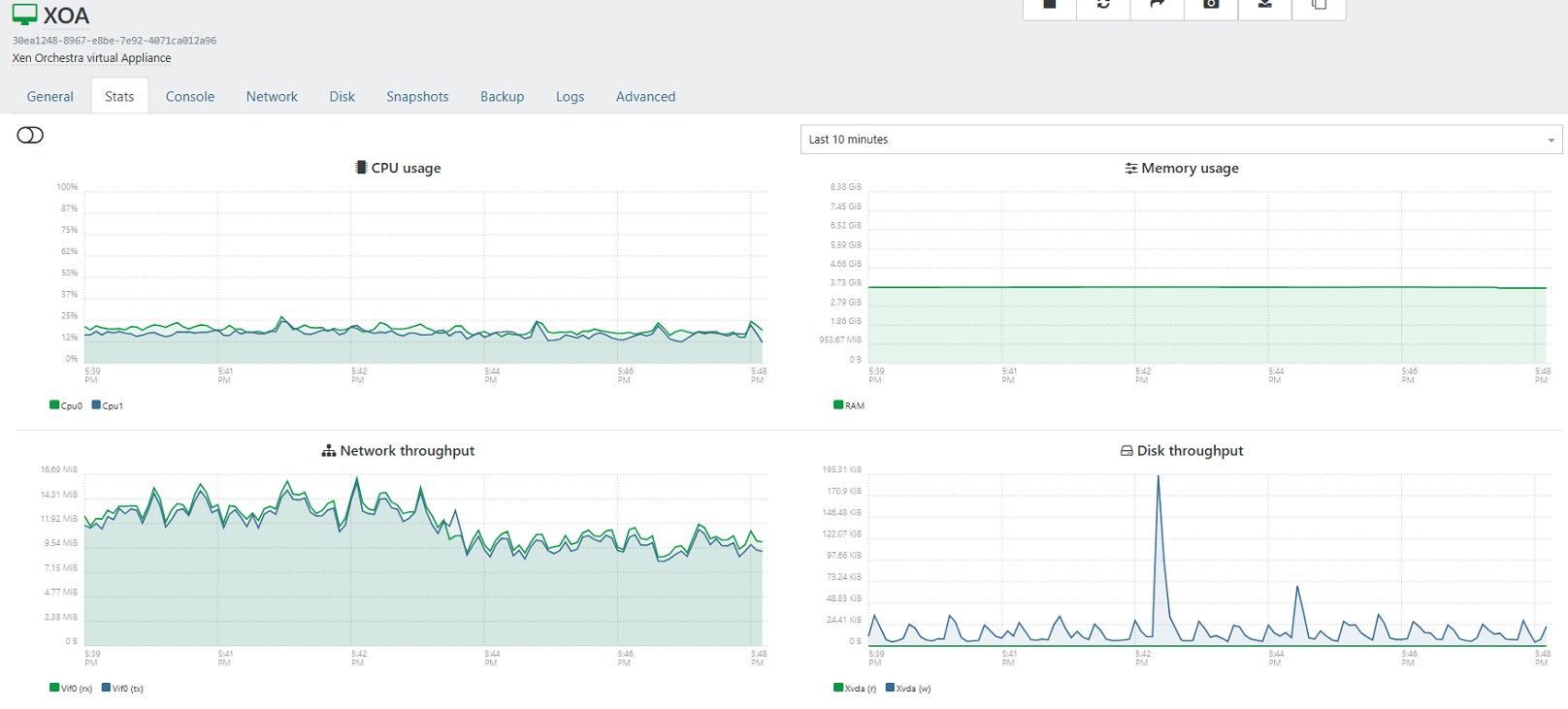
We have been doing a fair bit of testing on our side with this client, and we have discovered it appears to be an ISP issue of some kind.
What we are finding is utilizing iperf utility a single TCP stream appears to be capping out around 40Mbps on a 1Gbps fiber circuit.
In iperf if we run multiple streams, each stream will be right around 40Mbps, so 4 streams we will get around 160Mbps throughput to our DR location.
Testing on the clients' secondary providers fiber circuit we run just fine.
Little outside of XCP-ng and XOA here and battling that out with our ISP ")
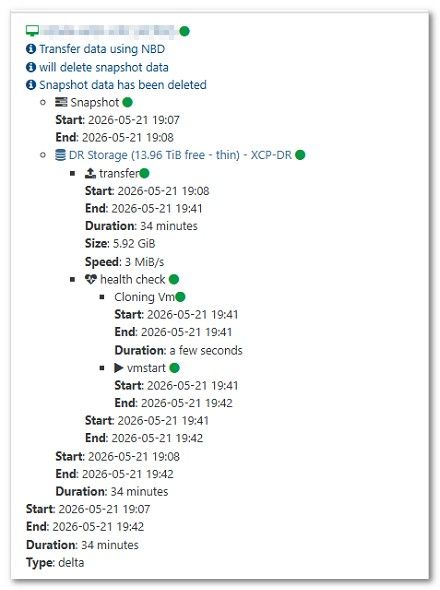
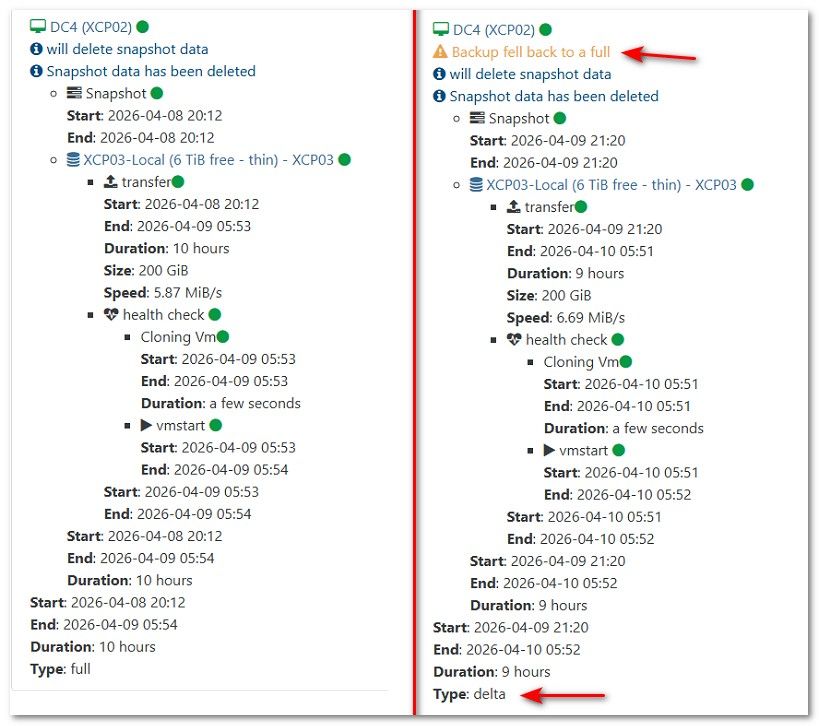
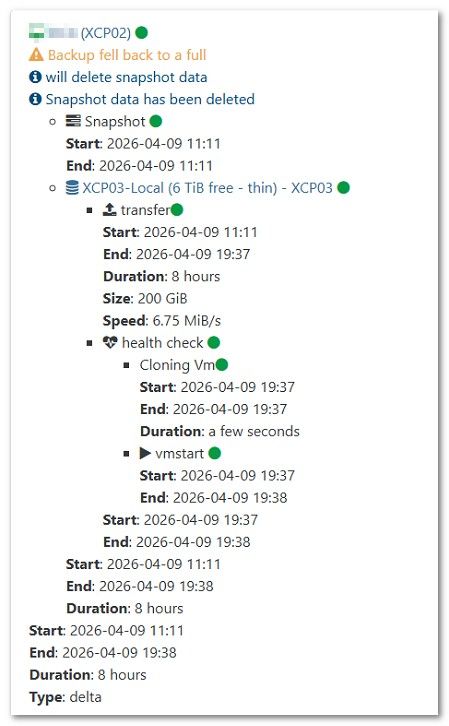
But that does lead me to a general question about replication.
Is the data mover process a single TCP stream per disk?
If so, is there any way to do a multi stream per disk?
Thanks