SR Garbage Collection running permanently
-
It takes few min, but i see that task runing almost non stop for only one storage.
At VDI list i see something weird: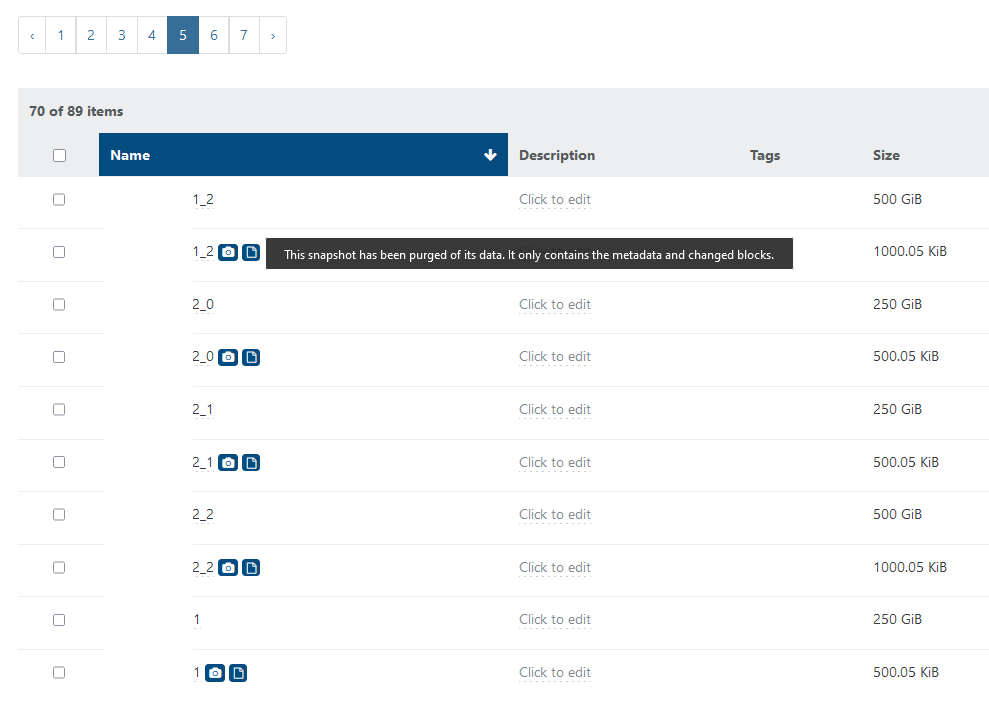
Nothing similar at other pools\sr.
-
Hi Tristis,
On the GC issue, have you checked the SR's Advanced tab to see if it lists VDI to be coalesced? You may also want to check
SMlogto see if there are exceptions preventing the GC from completing.For the image, check your backup jobs for the following settings --

This behavior should be present on all SRs where these options are enabled on the associated backups.
Regards, Dan
-
something like this?
Jan 17 00:00:40 host SMGC: [2648626] *~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~* Jan 17 00:00:40 host SMGC: [2648626] *********************** Jan 17 00:00:40 host SMGC: [2648626] * E X C E P T I O N * Jan 17 00:00:40 host SMGC: [2648626] *********************** Jan 17 00:00:40 host SMGC: [2648626] _doCoalesceLeaf: EXCEPTION <class 'util.SMException'>, Timed out Jan 17 00:00:40 host SMGC: [2648626] File "/opt/xensource/sm/cleanup.py", line 2449, in _liveLeafCoalesce Jan 17 00:00:40 host SMGC: [2648626] self._doCoalesceLeaf(vdi) Jan 17 00:00:40 host SMGC: [2648626] File "/opt/xensource/sm/cleanup.py", line 2483, in _doCoalesceLeaf Jan 17 00:00:40 host SMGC: [2648626] vdi._coalesceVHD(timeout) Jan 17 00:00:40 host SMGC: [2648626] File "/opt/xensource/sm/cleanup.py", line 933, in _coalesceVHD Jan 17 00:00:40 host SMGC: [2648626] self.sr.uuid, abortTest, VDI.POLL_INTERVAL, timeOut) Jan 17 00:00:40 host SMGC: [2648626] File "/opt/xensource/sm/cleanup.py", line 188, in runAbortable Jan 17 00:00:40 host SMGC: [2648626] raise util.SMException("Timed out") Jan 17 00:00:40 host SMGC: [2648626] Jan 17 00:00:40 host SMGC: [2648626] *~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~* Jan 17 00:00:40 host SMGC: [2648626] *** UNDO LEAF-COALESCE Jan 17 00:00:40 host SMGC: [2648626] Got sm-config for 3b0ee0f0(2000.000G/616.178G?): {'paused': 'true', 'vhd-blocks': 'eJzsvQ1gHFd1MHrv7Ghn5CjWyHGskeN4R45jCwpB *** Jan 17 00:00:40 host SMGC: [2648626] Unpausing VDI 3b0ee0f0(2000.000G/616.178G?) -
@Tristis-Oris said in SR Garbage Collection running permanently:
something like this?
Yes. Are you running XCP-ng 8.2.1 or 8.3?
On the snapshot issue, do you have any idea how they are being created?
-
@Danp
VDIs was migrated 8.2>8.3. Without snapshots, because of CBT.
Other pools was migrated by same way and have no such issue.i can't remember anything special, why that could happens.
-
@Tristis-Oris There's a fix for the time out during leaf coalesce on XCP-ng 8.3 that should be released soon. You can install it now with the following command --
yum install https://updates.xcp-ng.org/8/8.3/testing/x86_64/Packages/sm-3.2.3-1.15.xcpng8.3.x86_64.rpm https://updates.xcp-ng.org/8/8.3/testing/x86_64/Packages/sm-fairlock-3.2.3-1.15.xcpng8.3.x86_64.rpm -
@Danp reboot is required?
-
I have ran into this numerous times. Its one of the reasons i have not switched to "Purge Snapshot data when using CBT" on all my jobs yet.
I hope the fixes in testing solve the issue, what has been fixing it for me in the meantime is modifying the following:
Edit /opt/xensource/sm/cleanup.py : Modify LIVE_LEAF_COALESCE_MAX_SIZE and LIVE_LEAF_COALESCE_TIMEOUT to the following values: LIVE_LEAF_COALESCE_MAX_SIZE = 1024 * 1024 * 1024 # bytes LIVE_LEAF_COALESCE_TIMEOUT = 300 # seconds -
@Tristis-Oris Not AFAIK but it wouldn't hurt to be sure that the latest fixes are running.
-
- install patch, reboot pool.
- GC job started during restart and stuck at 0%, so i restart toolstack again.
- now nothing is running, bad snapshots not disappeared.
Should i wait longer or?
-
@Tristis-Oris Did you install the patch on all of the hosts in the pool? Have you tried rescanning an SR to kick off the GC process?
-
@Danp after some time GC task started automaticaly and running for 1 hour already. Still about 50%.
-
@Tristis-Oris GC done, ~5 items removed, ~20 left.
-
Good, so it is working
")
-
@olivierlambert is it some limit for items removal per run?
-
The GC is doing one chain after another. We told XenServer team back in 2016 that it could probably merge multiple chains at once, but they told us it was too risky. So we did not focus on that. Patience is key there. Clearly, we'll do better in the future.
-
@olivierlambert got it. Will see what happens in few days.
-
It will accelerate. First merges are the slowest ones, but then it's going faster and faster.
-
2 days, few backup cycles, snapshots amount won't descrease.
-
@Tristis-Oris Check
SMlogfor further exceptions.

Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login