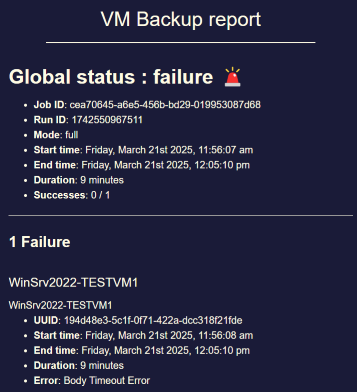
Potential bug with Windows VM backup: "Body Timeout Error"
-
@olivierlambert transfered
")
-
I backed up another Windows Server 2022 that had a lot of free space, setting no compression is the workaround right now. I'll have to get both of these shrunk down to reasonable and see if compression starts working. That's and after lunch task for the second "big" VM. I'll report back after performing the shrink steps on the one I can reboot today.
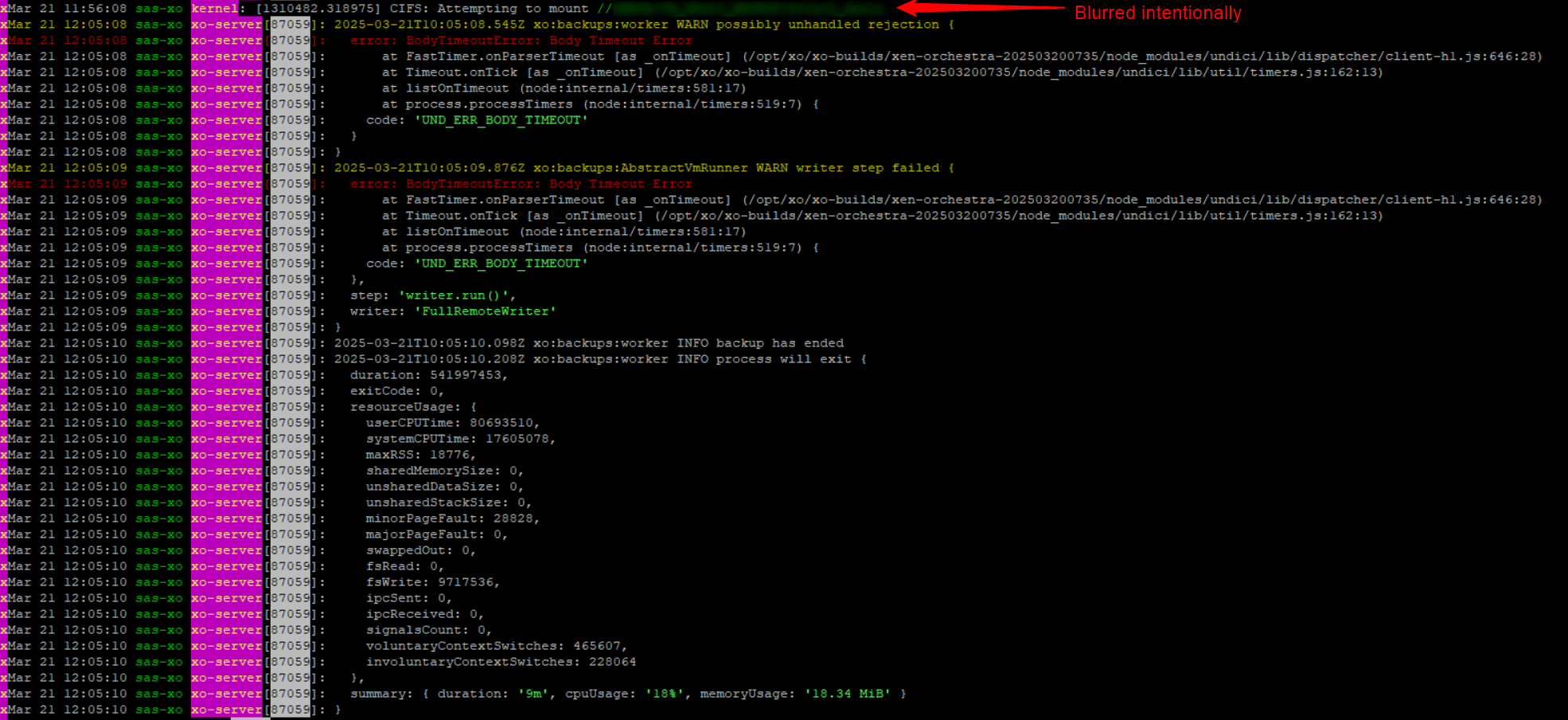
I agree with the working theory way up at the top... The process is still going, counting each empty "block" and "compressing" it, but with no data moving for over 5 minutes, it errors out. And 120-150GB worth of empty space in a Windows VM is enough to hit that timer.
Why the Linux machines don't do this? Might be because all of mine are done in less than 10 minutes total, which doesn't leave a lot of time where that timer can run. 3 of my linux with "large" disk went just fine, a couple only took 3 minutes to compress and copy to the remote share.
[edit] After shrinking and moving the partitions, I'm finding that XO is not allowed to decrease the size of a "disk", so I might just be stuck with no compression on these two VMs.
-
@florent can you help him?
-
Hey,
I am experiencing the same issue using XO from sources (commit 4d77b79ce920925691d84b55169ea3b70f7a52f6), Node version 22, Debian 13.
I have multiple backup jobs and only one which is a full backup job is giving me issues.
Most VMs can be backed up by this full backup job just fine but some error out with "body timeout error", e.g.:
{ "id": "1762017810483", "message": "transfer", "start": 1762017810483, "status": "failure", "end": 1762018134258, "result": { "name": "BodyTimeoutError", "code": "UND_ERR_BODY_TIMEOUT", "message": "Body Timeout Error", "stack": "BodyTimeoutError: Body Timeout Error\n at FastTimer.onParserTimeout [as _onTimeout] (/etc/xen-orchestra/node_modules/undici/lib/dispatcher/client-h1.js:646:28)\n at Timeout.onTick [as _onTimeout] (/etc/xen-orchestra/node_modules/undici/lib/util/timers.js:162:13)\n at listOnTimeout (node:internal/timers:588:17)\n at process.processTimers (node:internal/timers:523:7)" } }XO from sources VM has 8 vCPU and 8GB RAM.
Link speed of the XCP-ng hosts is 50 Gbit/s.
XO VM can reach 20 Gbit/s to the NAS in iperf.Zstd is enabled for this backup job.
It appears that only big VMs (as in disk size) have this issue.
The VMs that have this issue on the full backup job can be backed up just fine via delta backup job.I read in another thread that this issue can be caused by dom0 hardware constrains but dom0 has 16 vCPU and is at ~40% CPU usage while backups are running.
RAM usage sits at 2GB out of 8GB used.I changed my full backup job to GZIP compression and will see if this helps.
Will report back.
I really need compression due to the large virtual disks of some VMs...Best regards
MajorP -
@MajorP93 im seeing this as well, I think the issue is related to communication between XO and XCP-NG.
I noticed that it doesn't seem to depend on the vdi size in our case, but rather latency between XO and XCP-NG, which are on different sites and connected via IPSEC VPN. -
@nikade Hmm I have a hard time understanding what might cause this issue in my case since all of our 5 XCP-ng hosts are on the same site. They can talk on layer 2 with each other and have 2x 50 Gbit/s LACP bond each...
The XO VM is running on the pool master itself.
Some of the VMs that threw this error are also even running on the pool master itself.
So I would expect that the traffic does not even have to exit the physical host in this case...
Latency should be perfectly fine in this case...All XCP-ng hosts, XO VM and NAS (backup remote) can ping each other at below 1ms latency...
Really weird.
If anyone has an idea regarding what could possibly cause this I would be grateful.
As I said before I want to test Gzip instead of Zstd but I have to wait until this backup job finished.
It has ~40TB of data to backup in total
-
-
@olivierlambert said in Potential bug with Windows VM backup: "Body Timeout Error":
I think we have a lead, I've seen a discussion between @florent and @dinhngtu recently about that topic
Sounds good!
So there is a fix currently being worked on? -
I think we have a lead to explore, we'll keep you posted when we have a branch to test
")
-
@olivierlambert said in Potential bug with Windows VM backup: "Body Timeout Error":
I think we have a lead to explore, we'll keep you posted when we have a branch to test
Sure! Thank you very much.
When there is a branch available I will be happy to compile, test and provide any information / log needed. -
I did 2 more tests.
- using full backup with encryption disabled on the remote (had it enabled before) --> same issue
- switching from zstd to gzip --> same issue