Continuous Replication jobs creates full backups every time since 2025-09-06 (xo from source)
-
@olivierlambert Correct. Running commit 4944ea902ff19f172b1b86ec96ad989e322bec2c works.
-
@florent so it's like https://github.com/vatesfr/xen-orchestra/commit/a459015ca91c159123bb682f16237b4371a312a6 might introduced a regression?
-
@Andrew then again, with such a precise report, the fix is easier
the fix should join master soon
-
If you want to test, you can switch to the relevant branch, which is
fix_replicationhttps://github.com/vatesfr/xen-orchestra/pull/8971
closed fix(backups): replication doing always a full #8971
-
@olivierlambert
fix_replicationworks for some... but most of my VMs now have an error:
the writer IncrementalXapiWriter has failed the step writer.checkBaseVdis() with error Cannot read properties of undefined (reading 'managed')."result": { "message": "Cannot read properties of undefined (reading 'managed')", "name": "TypeError", "stack": "TypeError: Cannot read properties of undefined (reading 'managed')\n at file:///opt/xo/xo-builds/xen-orchestra-202509150025/@xen-orchestra/backups/_runners/_writers/IncrementalXapiWriter.mjs:29:15\n at Array.filter (<anonymous>)\n at IncrementalXapiWriter.checkBaseVdis (file:///opt/xo/xo-builds/xen-orchestra-202509150025/@xen-orchestra/backups/_runners/_writers/IncrementalXapiWriter.mjs:26:8)\n at file:///opt/xo/xo-builds/xen-orchestra-202509150025/@xen-orchestra/backups/_runners/_vmRunners/IncrementalXapi.mjs:159:54\n at callWriter (file:///opt/xo/xo-builds/xen-orchestra-202509150025/@xen-orchestra/backups/_runners/_vmRunners/_Abstract.mjs:33:15)\n at IncrementalXapiVmBackupRunner._callWriters (file:///opt/xo/xo-builds/xen-orchestra-202509150025/@xen-orchestra/backups/_runners/_vmRunners/_Abstract.mjs:52:14)\n at IncrementalXapiVmBackupRunner._selectBaseVm (file:///opt/xo/xo-builds/xen-orchestra-202509150025/@xen-orchestra/backups/_runners/_vmRunners/IncrementalXapi.mjs:158:16)\n at process.processTicksAndRejections (node:internal/process/task_queues:105:5)\n at async IncrementalXapiVmBackupRunner.run (file:///opt/xo/xo-builds/xen-orchestra-202509150025/@xen-orchestra/backups/_runners/_vmRunners/_AbstractXapi.mjs:378:5)\n at async file:///opt/xo/xo-builds/xen-orchestra-202509150025/@xen-orchestra/backups/_runners/VmsXapi.mjs:166:38" } -
Feedback for you @florent

-
@peo Yes, same problem!
-
@olivierlambert @florent Looks like 1471ab0c7c79fa6dca9a1598e7be2a141753ba91 (in current master) has fixed the issue.
But, during testing I found a new related issue (no error messages). Running current XO master b16d5...
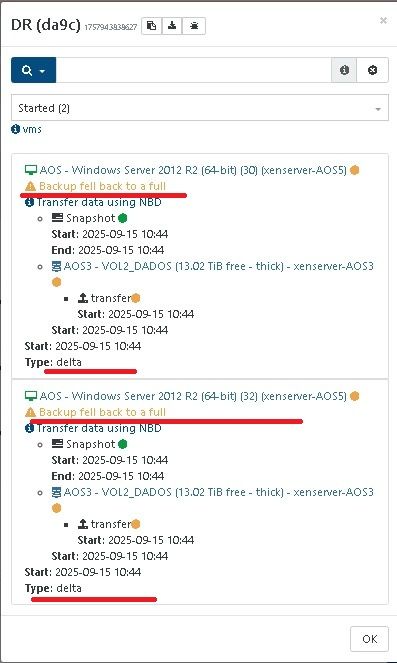
During the normal CR delta backup job, two VMs shows the warning message:
Backup fell back to a fullbut it did a delta (not full) backup.I caused this by running a different CR backup job (for testing) that used the two same VMs but to a different SR. The new test job did a full backup and delta backup correctly. Since there is only one CBT snapshot the normal backup job did recognize that the snapshot was not for the original normal backup job and should have done a full (and started a new CBT snapshot), but it only did a short delta.
As the VMs were off, I guess it could correctly use the other CBT snapshot as no blocks had changed... Just odd that CR backup said it was going to do a full and then did a delta.
-
-
@JB this means that it should have done a delta ( as per the full backup interval ) , but had to fall back to a full for at least one disk
this can happens after a failed transfer, a new disk added and some edge case. This issue was not really visible before the latest release, even if the impacts can be important , saturating network and storage.We are investigating this ( especially @Bastien-Nollet ) , and expect to have a fix and/or an explanation fast
Are you using "purge snapshot data" option ? Are there anything on the journalctl logs ?
-
@florent Thanks, Florent! No, No!
-
@JB Doyou have anything related in journalctl ? like
can't connect through NBD, fall back to stream exportorcan't compute delta ${vdiRef} from ${baseRef}, fallBack to a fullor anything starting by 'xo:xapi:xapi-disks' -
Sep 15 10:00:01 xo1 xo-server[5582]: 2025-09-15T14:00:01.026Z xo:backups:worker INFO starting backup Sep 15 10:00:32 xo1 xo-server[5582]: 2025-09-15T14:00:32.794Z xo:xapi:xapi-disks INFO Error in openNbdCBT XapiError: SR_BACKEND_FAILURE_460(, Failed to calculate changed blocks for given VD Is. [opterr=Source and target VDI are unrelated], ) Sep 15 10:00:32 xo1 xo-server[5582]: at XapiError.wrap (file:///opt/xo/xo-builds/xen-orchestra-202509150942/packages/xen-api/_XapiError.mjs:16:12) Sep 15 10:00:32 xo1 xo-server[5582]: at default (file:///opt/xo/xo-builds/xen-orchestra-202509150942/packages/xen-api/_getTaskResult.mjs:13:29) Sep 15 10:00:32 xo1 xo-server[5582]: at Xapi._addRecordToCache (file:///opt/xo/xo-builds/xen-orchestra-202509150942/packages/xen-api/index.mjs:1073:24) Sep 15 10:00:32 xo1 xo-server[5582]: at file:///opt/xo/xo-builds/xen-orchestra-202509150942/packages/xen-api/index.mjs:1107:14 Sep 15 10:00:32 xo1 xo-server[5582]: at Array.forEach (<anonymous>) Sep 15 10:00:32 xo1 xo-server[5582]: at Xapi._processEvents (file:///opt/xo/xo-builds/xen-orchestra-202509150942/packages/xen-api/index.mjs:1097:12) Sep 15 10:00:32 xo1 xo-server[5582]: at Xapi._watchEvents (file:///opt/xo/xo-builds/xen-orchestra-202509150942/packages/xen-api/index.mjs:1270:14) Sep 15 10:00:32 xo1 xo-server[5582]: at process.processTicksAndRejections (node:internal/process/task_queues:105:5) { Sep 15 10:00:32 xo1 xo-server[5582]: code: 'SR_BACKEND_FAILURE_460', Sep 15 10:00:32 xo1 xo-server[5582]: params: [ Sep 15 10:00:32 xo1 xo-server[5582]: '', Sep 15 10:00:32 xo1 xo-server[5582]: 'Failed to calculate changed blocks for given VDIs. [opterr=Source and target VDI are unrelated]', Sep 15 10:00:32 xo1 xo-server[5582]: '' Sep 15 10:00:32 xo1 xo-server[5582]: ], Sep 15 10:00:32 xo1 xo-server[5582]: call: undefined, Sep 15 10:00:32 xo1 xo-server[5582]: url: undefined, Sep 15 10:00:32 xo1 xo-server[5582]: task: task { Sep 15 10:00:32 xo1 xo-server[5582]: uuid: '6265a41c-29c3-f4d9-5f0c-e52db6e0fcc9', Sep 15 10:00:32 xo1 xo-server[5582]: name_label: 'Async.VDI.list_changed_blocks', Sep 15 10:00:32 xo1 xo-server[5582]: name_description: '', Sep 15 10:00:32 xo1 xo-server[5582]: allowed_operations: [], Sep 15 10:00:32 xo1 xo-server[5582]: current_operations: {}, Sep 15 10:00:32 xo1 xo-server[5582]: created: '20250915T14:00:32Z', Sep 15 10:00:32 xo1 xo-server[5582]: finished: '20250915T14:00:32Z', Sep 15 10:00:32 xo1 xo-server[5582]: status: 'failure', Sep 15 10:00:32 xo1 xo-server[5582]: resident_on: 'OpaqueRef:65b7a047-094b-4c7a-a503-2823e92b9fe4', Sep 15 10:00:32 xo1 xo-server[5582]: progress: 1, Sep 15 10:00:32 xo1 xo-server[5582]: type: '<none/>', Sep 15 10:00:32 xo1 xo-server[5582]: result: '', Sep 15 10:00:32 xo1 xo-server[5582]: error_info: [ Sep 15 10:00:32 xo1 xo-server[5582]: 'SR_BACKEND_FAILURE_460', Sep 15 10:00:32 xo1 xo-server[5582]: '', Sep 15 10:00:32 xo1 xo-server[5582]: 'Failed to calculate changed blocks for given VDIs. [opterr=Source and target VDI are unrelated]', Sep 15 10:00:32 xo1 xo-server[5582]: '' Sep 15 10:00:32 xo1 xo-server[5582]: ], Sep 15 10:00:32 xo1 xo-server[5582]: other_config: {}, Sep 15 10:00:32 xo1 xo-server[5582]: subtask_of: 'OpaqueRef:NULL', Sep 15 10:00:32 xo1 xo-server[5582]: subtasks: [], Sep 15 10:00:32 xo1 xo-server[5582]: backtrace: '(((process xapi)(filename lib/backtrace.ml)(line 210))((process xapi)(filename ocaml/xapi/storage_utils.ml)(line 141))((process xapi)(fi lename ocaml/xapi/message_forwarding.ml)(line 141))((process xapi)(filename ocaml/libs/xapi-stdext/lib/xapi-stdext-pervasives/pervasiveext.ml)(line 24))((process xapi)(filename ocaml/libs/x api-stdext/lib/xapi-stdext-pervasives/pervasiveext.ml)(line 39))((process xapi)(filename ocaml/xapi/rbac.ml)(line 188))((process xapi)(filename ocaml/xapi/rbac.ml)(line 197))((process xapi) (filename ocaml/xapi/server_helpers.ml)(line 77)))' Sep 15 10:00:32 xo1 xo-server[5582]: } Sep 15 10:00:32 xo1 xo-server[5582]: } Sep 15 10:00:35 xo1 xo-server[5582]: 2025-09-15T14:00:35.240Z xo:xapi:vdi WARN invalid HTTP header in response body { Sep 15 10:00:35 xo1 xo-server[5582]: body: 'HTTP/1.1 500 Internal Error\r\n' + Sep 15 10:00:35 xo1 xo-server[5582]: 'content-length: 318\r\n' + Sep 15 10:00:35 xo1 xo-server[5582]: 'content-type: text/html\r\n' + Sep 15 10:00:35 xo1 xo-server[5582]: 'connection: close\r\n' + Sep 15 10:00:35 xo1 xo-server[5582]: 'cache-control: no-cache, no-store\r\n' + Sep 15 10:00:35 xo1 xo-server[5582]: '\r\n' + Sep 15 10:00:35 xo1 xo-server[5582]: '<html><body><h1>HTTP 500 internal server error</h1>An unexpected error occurred; please wait a while and try again. If the problem persists, please contact your support representative.<h1> Additional information </h1>VDI_INCOMPATIBLE_TYPE: [ OpaqueRef:ec54186c-0ab5-0390-d244-64414e9d8887; CBT metadata ]</body></html>' Sep 15 10:00:35 xo1 xo-server[5582]: } Sep 15 10:00:35 xo1 xo-server[5582]: 2025-09-15T14:00:35.249Z xo:xapi:xapi-disks WARN can't compute delta OpaqueRef:888ccaa8-07c6-e6f0-3bfb-3e6b5ac4da2a from OpaqueRef:ec54186c-0ab5-0390-d2 44-64414e9d8887, fallBack to a full { Sep 15 10:00:35 xo1 xo-server[5582]: error: Error: invalid HTTP header in response body Sep 15 10:00:35 xo1 xo-server[5582]: at checkVdiExport (file:///opt/xo/xo-builds/xen-orchestra-202509150942/@xen-orchestra/xapi/vdi.mjs:36:19) Sep 15 10:00:35 xo1 xo-server[5582]: at process.processTicksAndRejections (node:internal/process/task_queues:105:5) Sep 15 10:00:35 xo1 xo-server[5582]: at async Xapi.exportContent (file:///opt/xo/xo-builds/xen-orchestra-202509150942/@xen-orchestra/xapi/vdi.mjs:244:5) Sep 15 10:00:35 xo1 xo-server[5582]: at async #getExportStream (file:///opt/xo/xo-builds/xen-orchestra-202509150942/@xen-orchestra/xapi/disks/XapiVhdStreamSource.mjs:123:20) Sep 15 10:00:35 xo1 xo-server[5582]: at async XapiVhdStreamSource.init (file:///opt/xo/xo-builds/xen-orchestra-202509150942/@xen-orchestra/xapi/disks/XapiVhdStreamSource.mjs:135:23) Sep 15 10:00:35 xo1 xo-server[5582]: at async #openExportStream (file:///opt/xo/xo-builds/xen-orchestra-202509150942/@xen-orchestra/xapi/disks/Xapi.mjs:128:7) Sep 15 10:00:35 xo1 xo-server[5582]: at async #openNbdStream (file:///opt/xo/xo-builds/xen-orchestra-202509150942/@xen-orchestra/xapi/disks/Xapi.mjs:81:22) Sep 15 10:00:35 xo1 xo-server[5582]: at async XapiDiskSource.openSource (file:///opt/xo/xo-builds/xen-orchestra-202509150942/@xen-orchestra/xapi/disks/Xapi.mjs:191:18) Sep 15 10:00:35 xo1 xo-server[5582]: at async XapiDiskSource.init (file:///opt/xo/xo-builds/xen-orchestra-202509150942/@xen-orchestra/disk-transform/dist/DiskPassthrough.mjs:28:41) Sep 15 10:00:35 xo1 xo-server[5582]: at async file:///opt/xo/xo-builds/xen-orchestra-202509150942/@xen-orchestra/backups/_incrementalVm.mjs:67:5 Sep 15 10:00:35 xo1 xo-server[5582]: } -
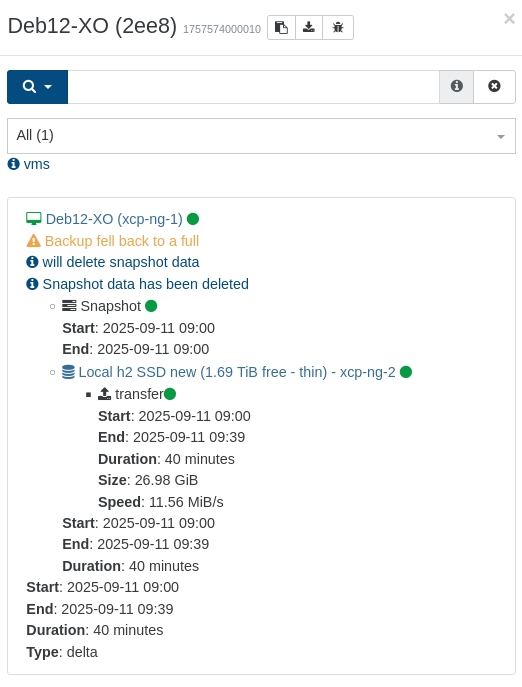
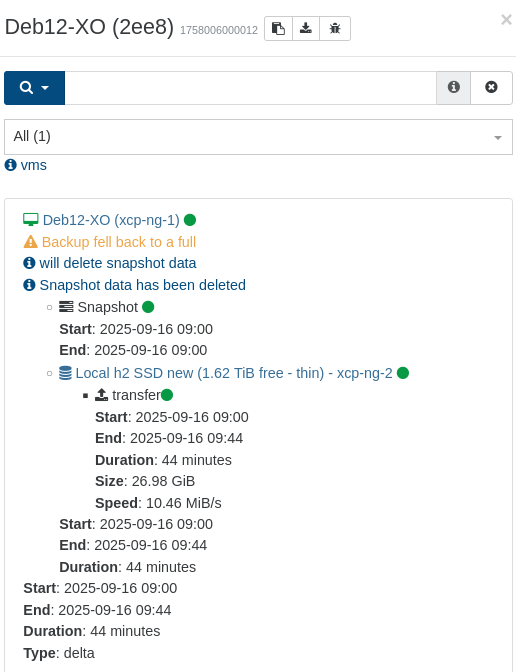
I'm currently testing the "fixed" version. At the time I ran the replications the first time, I expected and accepted it doing new "first" full backups/transfers, but even this small, singe-disk VM (the one for my XO) is still doing full transfers:

This simple operation previously taking 2-5 minutes now takes 44 minutes:
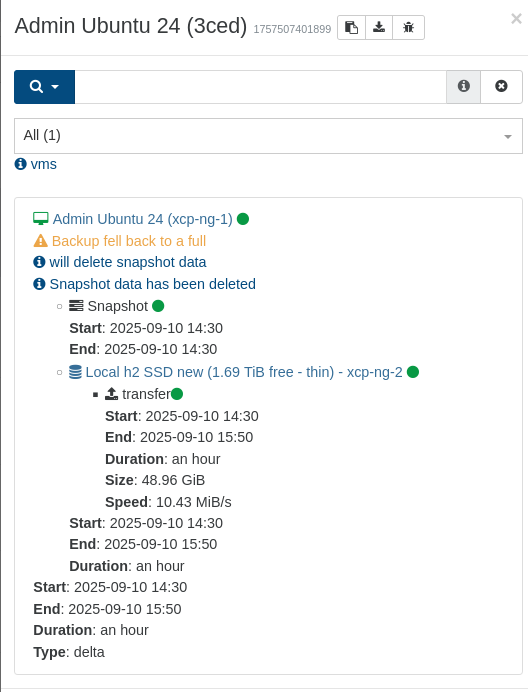
Compared to the previous "normal" backup time:
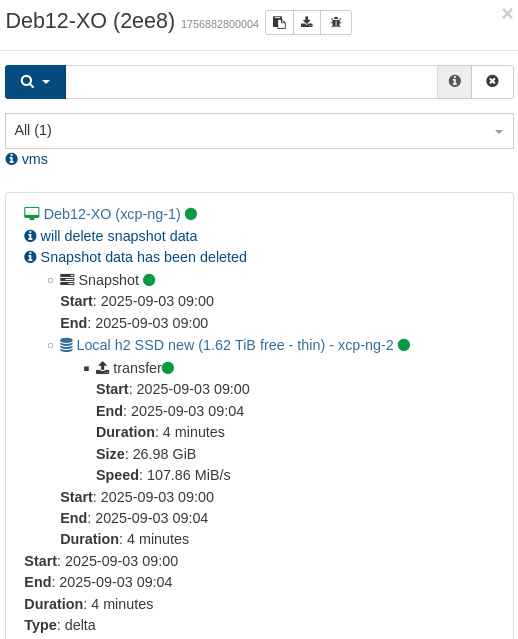
The same goes for "Admin Ubuntu 24", single but slightly larger disk (50GB) which yesterday took 4 hours (initial "new" "first" backup, so I don't know if it still takes that time)
-
I made the backup again and everything went back to normal. Everything is wonderful! Thank you so much!
-
-
@florent said in Continuous Replication jobs creates full backups every time since 2025-09-06 (xo from source):
@Andrew @peo
are you using purge snapshot data ?
In both case, can you try disabling it and disabling CBT on the relevant VMs ?Yes, I was using CBT + purge snapshots, but that might not have been the reason for the sluggish transfer speeds with the later versions of XO.
I discovered that the SSD on my destination host were going bad, a write of a /dev/null-filled test file (1GB then 5GB) on the device started at expected 450MB/s, but slowed down to less than 10MB/s. Found a bunch of unexpected errors (because the disk was more or less new) in the logs by dmesg.
Doing the replication to another host made it fast even when transferred in full.
CBT+delete = still "Backup fell back to a full" (this was the third since my XO update)
CBT w/o delete = first backup=full transfer (4 min) and garbage collection (a few more minutes), second=delta transfer (a few seconds backup time) -
@peo without deleting, the CBT can fail, but XO can still compute the changed blocks
before previous release, the fallback was hidden if you didn't look at the sizethe CBT issue is on the hypervisor storage side .
But at least , the replication issue is fixed, we are back to the good old issues
-
@florent It seems the
Type: deltadisplay duringBackup fell back to a fullmay just be a display issue as it does seem to run a full copy.