XO(A) - could we not use UTF(?) junk?
-
Hi again.
The official way of install gives, among others:
# bash -c "$(curl -s http://xoa.io/deploy)" Welcome to the XOA auto-deploy script! ... Importing XOA VM⌠Booting XOA VM⌠... Waiting for your XOA to be readyâŚI don't know what characters this junk was supposed to be after "VM" and "ready", but it's not accidental. I get the same cr.p on another XCP-ng host.
Really, could we not use UTF (I suspect) chars unless really needed (like in people's names), please, please?
-
UTF-8 should be used in any terminal since at least 10 years, what are you using? (this is probably the
…) -
@olivierlambert said in XO(A) - could we not use UTF(?) junk?:
UTF-8 should be used in any terminal since at least 10 years, what are you using? (this is probably the
…)- In an ideal world many thing should be present.
- Various systems: Linux ones, MS's ones...
- So three dots ... would do, no need for specials characters.
Another example:
a few days ago after fresh installing XCP-ng I could hardly read smartctl manpage even on the physical console of the very same system because there were so many unreadable characters in it.I really mean: in plain computer-related English messages everything can be properly expressed with just ASCII characters. Let's not complicate simple things, please, please...
-
Yes, ASCII is (generally) enough for plain English, but English is not the only language out there so everyone should migrate to UTF-8.
Because UTF-8 is fully compatible with ASCII for basic characters and we have no special needs we'll update the deploy script to be more backward compatible.
-
Done, thanks for your report
")
-
@julien-f said in XO(A) - could we not use UTF(?) junk?:
Yes, ASCII is (generally) enough for plain English, but English is not the only language out there
Of course. But I'm talking about English language set as the system language.
so everyone should migrate to UTF-8.
Like there should be no poverty...
Because UTF-8 is fully compatible with ASCII for basic characters and we have no special needs we'll update the deploy script to be more backward compatible.
Thanks!
-
Regarding the UTF-8 discussion: it's different from poverty. UTF-8 is a superior standard, and especially universal. "It works for me" isn't a valid argument when it comes to language.
ASCII is OK if USA were the only country in the world, but I assure you it's not the case
") I can argue we want to use only "Latin" because we are French working on this project: as you can see, it's not a valid excuse.
I can argue we want to use only "Latin" because we are French working on this project: as you can see, it's not a valid excuse.Note this graph (stopping in 2012, it's very likely far better now, I bet on UTF-8 at more than 80% easily):
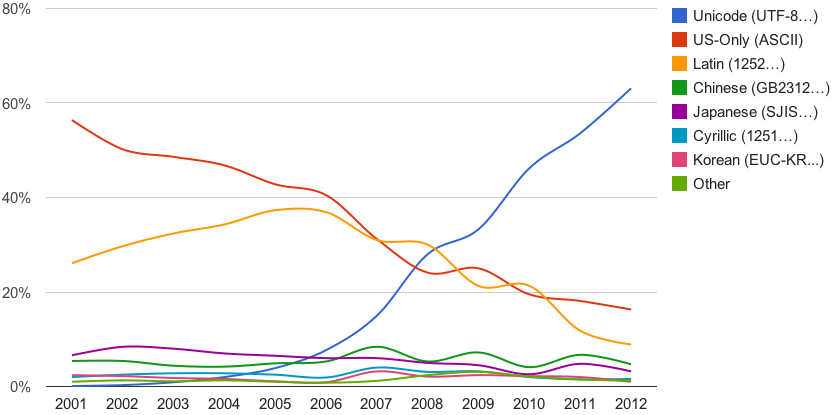
Source: http://pinyin.info/news/2015/utf-8-unicode-vs-other-encodings-over-time/
So yeah, you can keep to ASCII, like 640KiB should be enough for everyone, and so on
Are you still on your Pentium 2? Same thing Technically speaking, I'm surprised you have display issue on any modern Linux terminal which are UTF-8 by default for a long time.
So no, UTF-8 is not junk. It's like saying any other language than yours is junk.
-
@olivierlambert said in XO(A) - could we not use UTF(?) junk?:
Regarding the UTF-8 discussion: it's different from poverty. UTF-8 is a superior standard, and especially universal.
The sentence with "poverty" was an example. "SHOULD" is not "IS". Theory is one thing, reality is the other :-(.
"It works for me" isn't a valid argument when it comes to language.
Good point for my argument. You seem to say "UTF-8 works for me", but it does NOT for me, that's the fact. One can't argue the facts.
ASCII is OK if USA were the only country in the world, but I assure you it's not the case
I surely know :-). I'm not from there, I don't live there.
I can argue we want to use only "Latin" because we are French working on this project: as you can see, it's not a valid excuse.
Let me remind: I'm talking about English language set for the system, not an other.
Note this graph (stopping in 2012, it's very likely far better now, I bet on UTF-8 at more than 80% easily):
You can bet and even if it's 80%, it's is not 100%. And 20% is quite much.
Source: http://pinyin.info/news/2015/utf-8-unicode-vs-other-encodings-over-time/
How many people (percent) are disabled? Surely less than 20%. So why are buildings constructed accessible for wheelchairs?
So yeah, you can keep to ASCII, like 640KiB should be enough for everyone, and so on
Are you still on your Pentium 2? Same thing Yes.
A few from production servers which I still maintain:- Pentium II 350 MHz
- Pentium III 800 MHz
- Pentium III 930 MHz
They work. They are sufficient for their job.
Technically speaking, I'm surprised you have display issue on any modern Linux terminal which are UTF-8 by default for a long time.
I'm surprised by many things almost daily. That's life.
So no, UTF-8 is not junk.
UTF-8 is not junk. What it produces on the displays I observe - is.
It's like saying any other language than yours is junk.
BTW, English is not my native language :-).
-
Title is: "could we not use UTF(?) junk", so it would mean UTF is junk. Saying "could we remove some UTF-8 char" would have been more neutral
And no, I'm not saying "UTF-8 works for me", I say "UTF-8 is universal and should be used by everyone", unlike "regional other encoding". I think you get my point
-
@olivierlambert said in XO(A) - could we not use UTF(?) junk?:
Title is: "could we not use UTF(?) junk", so it would mean UTF is junk. Saying "could we remove some UTF-8 char" would have been more neutral
OK, I admit I'm quite tired (so irritated) with never-ending problems with UTF.
And no, I'm not saying "UTF-8 works for me", I say "UTF-8 is universal and should be used by everyone",
As I have written: "should" is not "is". "Is" is a fact. "Should" is a wishing.
unlike "regional other encoding". I think you get my point
I'm not proposing any regional encoding. ASCII is not a regional encoding. It's a subset. Like a common denominator. One who can read UTF, can read ASCII. The opposite is not always true.
-
Been tired by UTF-8: I really don't understand. This seems a basic effort to be able to communicate with the rest of the world without troubles. I remember the time when I migrated a lot of stuff to UTF-8 (mainly databases) back in 2008, since then I never had any problem. Maybe you are a bit defiant against change? (not a judgement, I really try to understand what's your problem with UTF-8)
-
marked as solved to show that the main question of that thread is solved
the other stuff is more political/personal... seems not to be solvable by a single commit ... -
+1
640KiB for everyone
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login