XCP-ng 8.3 betas and RCs feedback 🚀
-
@probain I left this conflict on purpose because update via yum is not supported from 8.2 to 8.3.
-
Since updating one of our linux based virtual appliances (SingleWire Infromacast) no longer boots. It begins booting then hits
"kexec_core: Starting new kernel" then powers off.
xl dmesg shows the following:
(XEN) [15750.951614] d11v0 Triple fault - invoking HVM shutdown action 3 (XEN) [15750.951615] *** Dumping Dom11 vcpu#0 state: *** (XEN) [15750.951617] ----[ Xen-4.17.4-3 x86_64 debug=n Not tainted ]---- (XEN) [15750.951617] CPU: 11 (XEN) [15750.951618] RIP: 0010:[<ffffffffb3000089>] (XEN) [15750.951618] RFLAGS: 0000000000010006 CONTEXT: hvm guest (d11v0) (XEN) [15750.951619] rax: ffffffffb3000089 rbx: 0000000000100800 rcx: 00000000000000a0 (XEN) [15750.951620] rdx: 000000004a411000 rsi: 000000000fbf3000 rdi: 000000006072a000 (XEN) [15750.951621] rbp: 000000000d000000 rsp: 000000004a403f58 r8: 0000000016000000 (XEN) [15750.951621] r9: 000000004a410d28 r10: 000000004a72d000 r11: 000000000000000e (XEN) [15750.951622] r12: 0000000000000000 r13: 0000000000000000 r14: 0000000000000000 (XEN) [15750.951622] r15: 0000000000000000 cr0: 0000000080000011 cr4: 00000000000000a0 (XEN) [15750.951623] cr3: 000000006072a000 cr2: ffffffffb3000089 (XEN) [15750.951623] fsb: 0000000000000000 gsb: 0000000000000000 gss: 0000000000000000 (XEN) [15750.951624] ds: 0018 es: 0018 fs: 0000 gs: 0000 ss: 0018 cs: 0010Any ideas? Was working on the latest batch of updates before the ones released today.
EDIT:
Running a yum downgrade xen-hypervisor xen-dom0-libs xen-dom0-tools xen-tools xen-libs followed by a reboot gets the VM booting again.
-
@flakpyro Interesting. I will build intermediary releases of Xen to help narrow down to the changes that caused this. Will you be available to test them?
-
@stormi Of course, anything i can do to help just let me know. We have a number of systems we can use to test builds on.
-
This is ultimately a bug in Linux. There was a range of Linux kernels which did something unsafe on kexec which worked most of the time but only by luck. (Specifically - holding a 64bit value in a register while passing through 32bit mode, and expecting it to still be intact later; both Intel and AMD identify this as having model specific behaviour and not to rely on it).
A consequence of a security fix in Xen (https://xenbits.xen.org/xsa/advisory-454.html) makes it reliably fail when depended upon in a VM.
Linux fixed the bug years ago, but one distro managed to pick it up.
Ideally, get SingleWire to fix their kernel. Failing that, adjust the VM's kernel command line to take any
,lowor,highoff the crashkernel= line, because that was the underlying way to tickle the bug IIRC.The property you need to end up with is that
/proc/iomemshows theCrash kernelrange being below the 4G boundary, because the handover logic from one kernel to the other simply didn't work correctly if the new kernel was above 4G. -
@andyhhp Thanks, from what i had found on google i suspected this was a bug. Their disto is high customized too, here is what grub looks like:
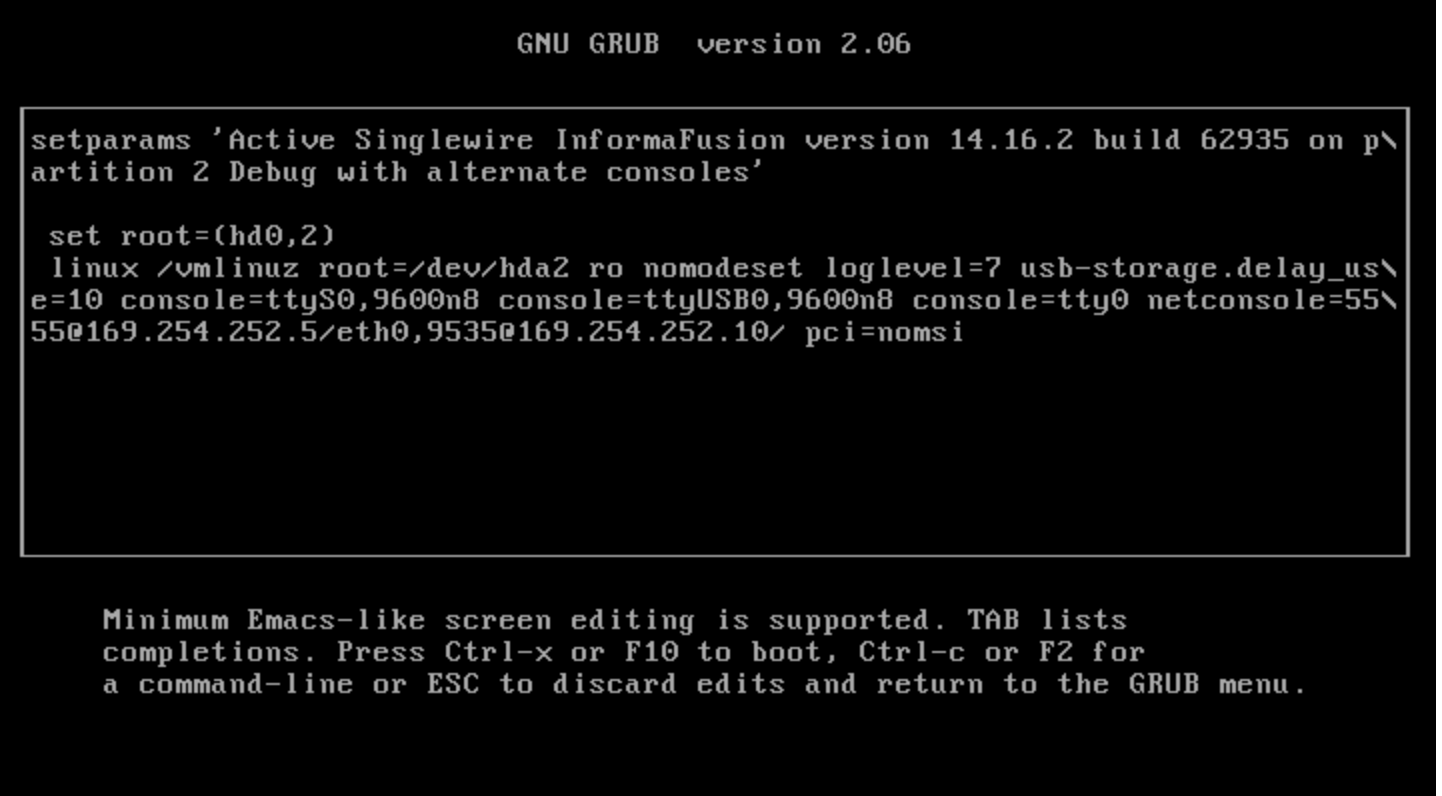
Talking to the person who maintains this i learned there is a 14.24 version of the software out that seems to work, it looks like they fixed it in a later release. I was hoping to get it booting as to buy that person time to perform the upgrade. In the mean time i have rolled back Xen to 4.17.3.
-
@flakpyro If Singlewire have already fixed the bug, then just do what is is necessary to update the VM and be done with it.
That screenshot of grub poses far more questions than it answered, and I doubt we want to get into any of them.
-
@andyhhp I will pass that on thanks! I believe you're right in the long run this is something we are better off redeploying on their new appliance.
-
-
@stormi Update of my XCP-ng 8.3 test server through XO from source (88 patches) went really well and after a reboot (not sure if that was needed), my VMs started normaly
 . I will report back if something comes up. Looking forward to the RC
. I will report back if something comes up. Looking forward to the RC 
-
Applied recent 87 updates to 3-node home-lab pool running XCP-ng 8.3 using XO from source on the latest commit. The update worked perfectly and a mix of existing Linux and Windows VMs are running normally after the update.
-
11 hosts and thirty something VMs (windows, linux, bsd mix) and update went fine.
-
Updated 2 hosts with the current packages for 8.3. No issues during the package install and things have been running well so far. Keep up the amazing work XCP-NG/XO teams.

-
Good Morning,
I updated 2 1-node instances, one running on a Lenovo M920q and one running on a N5105 fanless devices. The Lenovo update run perfect but the N5105 device ended up in a boot loop. Both were on 8.3beta with the latest patches before.
Turned out the initrd image wasn't build but
/boot/initrd-4.19.0+1.img.cmdwas there. Running the command in the/boot/initrd-4.19.0+1.img.cmd(new-kernel-pkg --install --mkinitrd "$@" 4.19.0+1) created it and the reboot was successful. -
@patient0 Any chance you had rebooted before the initrd had a chance to build?
-
@stormi I was very thin on providing information, Sorry about that.
Using docker container XO I applied the patches and did something else for maybe 20 or 30 minutes. Then there were no more pending patches but also no mention of a necessary reboot. Usually I get two warning triangles, one for no-support for XO and the other that a reboot is necessary to apply the patches.
I was a bit suprised that the 88 patches didn't require a reboot but I wanted to do one anyway.
After putting the host in maintenance mode I pressed 'Smart Reboot' and let it do it's magic (the magic reboot loop that time).
Maybe I did not wait long enough. To be honest I don't really now what I would check to see if the patches are finished with applying. Usually when no there are no patches pending I do reboot. Seems I was just lucky with the Lenovo not having the problem.
-
@stormi I found that the interface-rename script broke with this update due to changes in python, specifically the line where the script concats two dict.keys(): the keys() method signature changed to return dict_keys, which doesn't have the add (or w/e it's named) method, so "a.keys()+b.keys()" fails now. I had to hand-edit the script to get it working, the fix is trivial: concat lists of keys rather than the keys directly.
-
-
@r0ssar00 hi, that issue would arise if you ran this script with python3, but it's interpreter is set as
/usr/bin/python- How did you call this script, did you manually call it with python3? It should be ran by just running the command on the CLI eginterface-rename -
@stormi
Updated ryzen 1700 late last week, and Threadripper 5975 and Epyc 7313p servers. No issues so far.
Installing fresh on epyc 9224 this week