Backup Alternatives
-
Is deduplication such a big deal? I mean, the cost of it is not negligible and (at least with SMAPIv1) the gain isn't great at all.
-
With dedup i mean dedup of the backup repo. And its an extremely big deal for backup repos. Backup vendors put a lot of effort in this. CommVault and NetBackup have it natively and Veeam does recommend deduplicated storage (Data Domain,...).
In our case we use an S3 backend and if you pay for a month worth of full backups 2-3 times a full backup size or 30 times a compressed full backup size is really a big deal. And we keep out backups sometimes for month.
We are doing bi-weekly fulls with our homebuilt kopia strategy of a 1.3 TB SR (no empty disks) and are using apx. 1.37 TB S3.
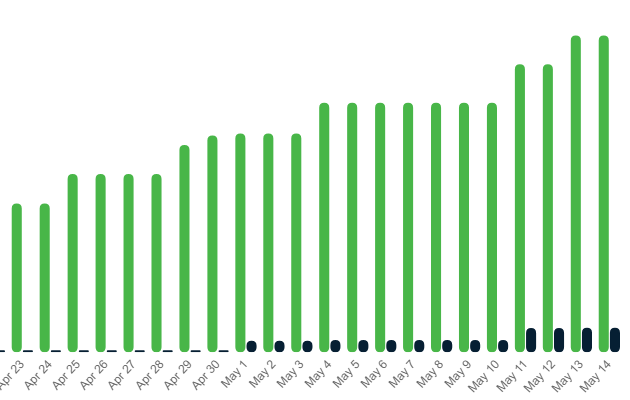
its from 0.64 TB up to 1.37 TB. Green is size used and black are the blocks which could be deleted.
if someone is interested why we use kopia instead of restic. restic is super slow on dumps to stdout and on mount. we use mount in combination with libguestfs to do file-level-recovery.
this is the script. not super professional and not the best error-handling but it may be useful:
#!/bin/bash VMNAME=$1 SERVER=$2 SERVER=${SERVER:=172.25.10.2} BACKUPDESC="Backup $(date +'%Y-%m-%d %H:%M:%S') of VM $VMNAME" echo "$(date +'%Y-%m-%d %H:%M:%S') Starting Backup of vm $VMNAME" echo SERVER:$SERVER PASS=$(cat /root/.pass) export XE_EXTRA_ARGS="server=$SERVER,port=443,username=root,password=$PASS" VMID=$(xe vm-list name-label=$VMNAME | grep uuid | sed "s/.*: //g") if [ -z "$VMID" ] then echo VMID not found exit 1 fi echo VMID: $VMID SNAPID=$(xe vm-snapshot uuid=$VMID new-name-label=backup_$VMNAME) if [ -z "$SNAPID" ] then echo SNAPID not found exit 1 fi echo SNAPID: $SNAPID declare -a DISKID declare -a DISKNAME TEMPD=$(mktemp -d) mkdir $TEMPD/data echo "$(date +'%Y-%m-%d %H:%M:%S') Temp directory: $TEMPD" xe vm-export metadata=true uuid=$VMID filename=$TEMPD/data/metadata.ova.tar xe snapshot-disk-list uuid=$SNAPID vdi-params=all vbd-params=all > $TEMPD/data/vdi.txt xe vm-list name-label=$VMNAME params=all > $TEMPD/data/vm.txt ls -l $TEMPD/data DISKID=( $(xe snapshot-disk-list uuid=$SNAPID vdi-params=uuid,name-label vbd-params=false | grep uuid | awk '{print $5}') ) DISKNAME=( $(xe snapshot-disk-list uuid=$SNAPID vdi-params=uuid,name-label vbd-params=false | grep name-label | awk '{print $4}') ) echo DISKID: ${DISKID[@]} echo DISKNAME: ${DISKNAME[@]} for i in ${!DISKID[@]}; do DN=${DISKNAME[$i]} DID=${DISKID[$i]} echo "$(date +'%Y-%m-%d %H:%M:%S') tagging disk $i is ${DID} ${DN}" xe vdi-param-set name-description="$BACKUPDESC" uuid=$DID done for i in ${!DISKID[@]}; do DN=${DISKNAME[$i]} DID=${DISKID[$i]} echo "$(date +'%Y-%m-%d %H:%M:%S') backup disk $i is ${DID} ${DN}" xe vdi-export uuid=$DID filename= format=raw | kopia snapshot create --tags=vm:$VMNAME,data=$DN --no-progress --log-level=warning --override-source=/vms/$VMNAME/$DN --stdin-file=${DID}.vhd - || echo "ERROR" sleep 5 xe vdi-destroy uuid=$DID done tar cvpf $TEMPD/metadata.tar -C $TEMPD/data . kopia snapshot create --tags=vm:$VMNAME,data=meta --no-progress --log-level=info --override-source=/vms/$VMNAME $TEMPD/metadata.tar || echo "ERROR" rm -rf $TEMPD echo "$(date +'%Y-%m-%d %H:%M:%S') waiting 30s" sleep 30 echo "$(date +'%Y-%m-%d %H:%M:%S') deleting snapshot $SNAPID of VM $VMNAME" xe snapshot-uninstall uuid=$SNAPID force=true || echo ERROR sleep 20 xe snapshot-uninstall uuid=$SNAPID force=true > /dev/null 2>&1 || true echo "$(date +'%Y-%m-%d %H:%M:%S') Done Backup of vm $VMNAME" -
We tried dedup for the backup repo with ZFS, to see the ratio kept. Due to VHD fragmentation, the gain was between 10 to 30% tops. Far far from being useful. That's why I think it would makes sense with SMAPIv3 and not v1 (because of the VHD format and its fragmentation)
edit: also a simple script like this won't be able to deal with chain protection and many other important features.
-
@olivierlambert The problem is what you dedup.
We dedup raw VDI exports and they are nearly perfect dedup candidates.
I attached our script in the previous post.With XVA i also only get 25% dedup ratio because of the tar metadata-problem. We decided that this is useless.
-
We tested to dedup the VHD exported. Your dedup ratio will diminish inexorably with time, as your VHD will become more and more fragmented. In raw, it should be similar at some point, since blocks aren't removed after usage (no trim support in SMAPIv1)
-
To clarify: In a XVA the folder names are of the kind Ref... and the number in the folder-name is random. This kills the dedup. If we could force the folder-name to be like Disk_[1,2,3,4] XVAs would be very good deduplicatable
-
@olivierlambert
We are using dedup backup-stores for years now and yes they grow if you keep very long time-ranges. but they never grow as much as compressed fulls. and if you only keep shorter ranges (1-2 month) than the dedup ration will be nearly constant after some month.I just checked the CommVault-Repos of our customers and they are all above 70% dedup saving and about 50% of the repos are above 90% dedup saving.
Depending on the size of their backup NAS they all have retention seetings between 60 days and one year.
Our own XenBackup S3 repo for Kopia will stop to grow when we delete older snapshots. for now we just kep backing up and this is the reason why it grows.

i removed the first column because it would show confidential customer information.
-
Dedup is a huge deal, in our SAN we're seeing a 6.7:1 ratio which means we're saving a ton of money. With that said, Veeam for example also has dedup but it totally sucks.
I think it might be hard to get a good ratio with backup-data. -
@rfx77 I don't know how you can keep shorter range if you do forever incremental
 The fragmentation will only grow
The fragmentation will only grow -
Is there any possibility to disable compression?
I think, it could be a good option to fully give ZFS control over the remote:- ZFS can do compression
- Without "external compression", deduplication could be much more efficient
-
We benched ZFS dedup without compression and the result was bad. I'm convinced everything will change with a proper data path that will support trim.
-
@olivierlambert dedup has nothing to do with forever incremental.
if you are doing backups, only the changed blocks are stored and the blocks which are not used in any backup are deleted. all blocks are backuped but the software stores only the blocks which are new
with our kopia solution we do always full backups. kopia manages the dedup. with commvault we do fulls and incs
i think that most people here are thinking to much backup as the way veeam does it with reverse-inc and forever inc. veeam does it in a very specific way. with commvault, netbackup,... we do classic fulls and incs.
i dont know how to describe it better. if you do an incremental backup you only backup the changed blocks. when you do a full afterwards these blocks are already in the backup repo so they dont have to be written. you can do incs and fulls and you will only have the blocks in the repo which are necessary to restore these backups. so one year of daily fulls or incs may not use more then 3-4 times a full in the backup repo.
-
To be clear. i never talked about deduplicated storage. i am always talking about deduplicated backup store. the edup is not done by the fs but by the backup-software
deduplicated storage is a completely different topic which can be addresse with sapiv3 but its not the think my posts are all about
-
@olivierlambert we are talking about different things. i dont mean dedup storage. i am talking about deduplicated backup store. the dedup is done by the backup-software (kopia,restic,borg, commvault,...) they support various backends like s3, ftp, sftp, local disk,...
-
@nikade You can see the ratios in the picture above. they are all around 90%
-
@rfx77 That's exactly what I'm talking about. As I said, we tested dedup ratio with exported VHD files and it tends to diminish pretty quickly as you have more and more fragmentation, at a point it's worthless. But, yes it works pretty well if you have similar templates underneath and little fragmentation.
-
@olivierlambert this backup looks really good. I currently in my VMware space use veeam. It's ok. I mainly just run backups of my virtuals and move them to an offline storage so if an encryption hack gets in, they can't encrypt the disks. So I run a script to move the file through a link to a Synology. That is just the VMs. For all my SQLs I run smss jobs to back up dbs and then transaction logs every 15 min. Again moving to offline storage. That gets me at least 15 min recovery to the crash. So I really do not focus too much on the backup software but to get me a VM back but my data i do separately so I have to ability to restore locally or move it to external resource. People here have some good discussions on the backup. Good thread
-
@olivierlambert fragmentation does not matter with deduplication (at least how dedup is used in backup repos). i dont know why it does not work in your case. we do raw and not vhd. maybe thats a point. there can also be a problem when the guest-filesystem is zfs or btrfs because how those filystem alain their blocks.
in general (with non ROW/COW guest fs) fragmentation should not do any harm. at least thats what we see at our customers backup repos. and they have windows and different linux guests. we do not use base templates so there should not be any hidden benefit of something.
-
We tested with VHD format, not with raw. We could do a test, but with raw you can't do deltas.
-
@wtdrisco we are testing with alike A3 from Quadric software, it is a good solution as well, they have a lot of experience with xenserver and xcp as well, they also have builtin deduplication.