CBT: the thread to centralize your feedback
-
@flakpyro in general this error means that the cbt is not valid, we have seen this as well and i know vates is looking into this. In general we saw this problem more on nfs then on iscsi, not shure if it is nfs related but maybe if u have access to an iscsi target try your results there.
-
@rtjdamen this test pool is running on TrueNAS, so i could configure iSCSI. Our production is on NFS so i tried to keep test close to the same as far as storage is concerned. We currently use NBD + CBT without the snapshot delete function in production and it works well via NFS. Will continue to keep testing as updates roll out and look forward to when this is completely stable. If there's anything anyone at Vates needs log or test wise i'm happy to help!
-
@flakpyro i think that would be a good test, can u check how it is behaving on iscsi on your end?
-
@StormMaster Thank you - I experienced that too , 2 backup plans with same VMs. Backup failed once out of two with error message "can't create a stream from a metadata VDI, fall back to a base"
-
@chr1st0ph9 i understand a fix is being made for this, @florent patched our proxy yesterday and since then no more fulls so far!
-
@rtjdamen Thats great news, with both block and file based SRs?
-
this branch ( already deployed on @rtjdamen systems) add a better handing of host that took too much time to compute the changed block list :
https://github.com/vatesfr/xen-orchestra/pull/8120it will be release in patch this week
I am still investigating an error that still occurs occasionally : XapiError: SR_BACKEND_FAILURE_460(, Failed to calculate changed blocks for given VDIs. [opterr=Source and target VDI are unrelated], )
-
@florent thanks for letting me know, on our end this error seems to occur on the same vms every time, it are just a handfull. Could it be these vms are facing higher load on them what causes xapi tasks to take longer then expected?
-
@rtjdamen @florent Be very curious to test this once it hits XOA.
The lab i am testing this a two host pool with each server having a 24 Core Epyc CPU and 256 GB of ram. There are only around 4 VMs running on this test environment currently and all are low load VMs.
Is it still something that mostly occurs with file based SRs? I never did get a chance to setup ISCSI and test with it instead of NFS.
Once this becomes stable there i definitely plan to switch to this backup method in production!
-
@flakpyro no on my end there is no difference for nfs or iscsi on XOA backups, we only had this issue with Alike Backup, my assumption was this would be the case in XOA as well, but not at this time.
What i found out is that one of my vms facing this issue has 2 disks, both on a different SR, i am moving one of the disks to the same SR and check tomorrow (tonight will be a full after migrating) if this is still the case there.
The other vm we face this issue on is has both disks on the same SR so that cannot be the case there. keep u posted on the results.
-
@rtjdamen we found a clue with @Bastien-Nollet : there was a race condition between the timeframe allowed to enable CBT and the snapshot, leading to a snapshot taken before CBT , thus failing to compute correctly the list of changed block at the next backup
The fix is deployed, and we'll see this night. If everything goes well, this night will be a full, but the disks will keep CBT enabled. And the next night, we'll have delta
if everything is ok, it will be released in a second patch ( 5.100.2 )
-
@florent sounds like a plan! i will keep an eye on them and let u know the results!
-
Hi,
I observed one issue with the backup process when the CBT is enabled. The case is showing when the VM has two disks on different SRs. When the backup tries to be taken, it fails, and the machine goes to a state where no other changes/reconfiguration is possible. It is not possible to disable CBT, move a disk to a different SR or create another backup. Sometimes after a failed backup the console access and machine are freezing. Everything works fine when all of the VM disks are on one SR.The logs from the first backup:

-
Hi @barwys
Can you provide more details? We need to know on which commit or XOA version you are
")
-
@olivierlambert Xen Orchestra, commit 804af
Both SRs are the shared storage by Fibre Channels connection (multipathing enabled). I tested on the Windows or Linux guest system as well. XenTools respectively 9.4.0/9.3.3 and 8.4.0-1 respectively. -
This commit is already a week old, please update to the latest one, rebuild and try again
-
Hello @olivierlambert,
After upgrading to commit 05c4e, I cannot reproduce this issue again. It seems to work much better.
Thanks -
Great! Please remember to always be on latest commit before reporting a problem, as you can see the code base is evolving fast
")
-
@olivierlambert Unfortunately after updating to 5.100.2 (XOA and Proxies) i am still running into XOA backups falling back to full after preforming a VM migration between two hosts within a pool when snapshot deletion is enabled. This doesnt happen if the snapshot is retained.
My test setup:
Servers: 2 x HP DL325 Gen 10 AMD Epyc Servers
Storage: TrueNAS Mini R running TrueNAS Scale 24.10 serving an NFS SR shared between both servers.
All VMs running on the same shared SR on the TrueNAS.Scenario:
VM 1 Migrated from Host A to Host B
VM 2 Migrated from Host B to Host ARunning a CBT with Snapshot delete backup after migration the VM between hosts while they remain on the same shared SR results in the error:
"Can't do delta with this vdi, transfer will be a full"
"Can't do delta, will try to get a full stream"Full log and screenshot of the error:
2024-11-14T19_20_40.383Z - backup NG.json.txt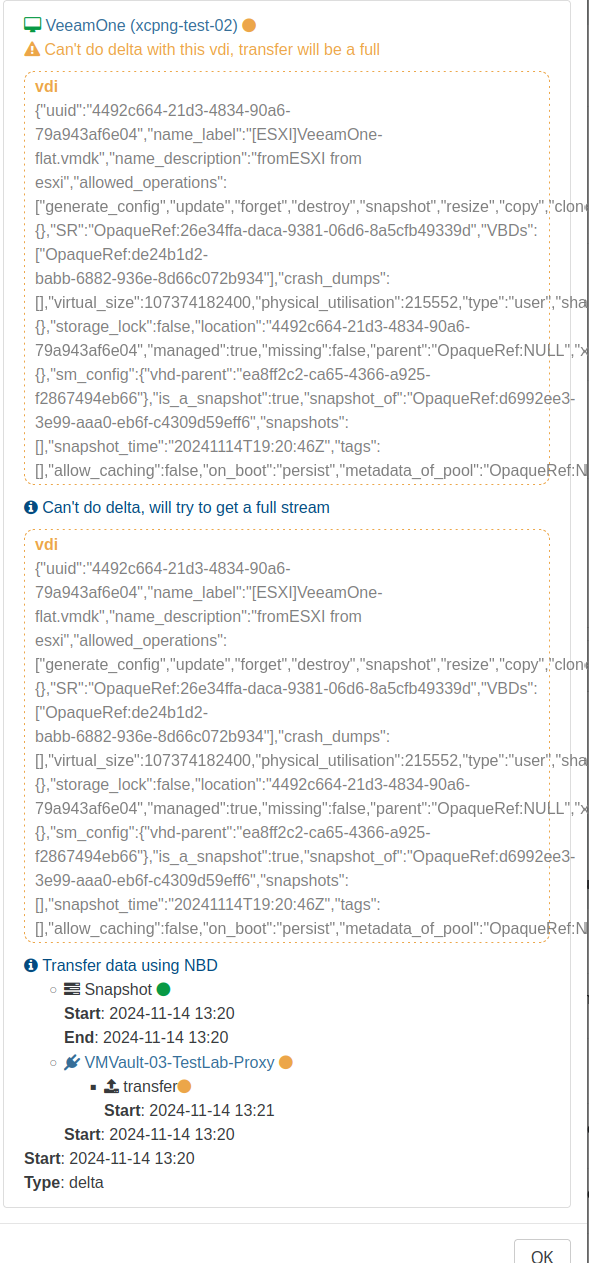
-
Sadly you are the only one we know we this problem that we cannot reproduce

I suppose we already checked that the VDI UUID doesn't change after the migration right?
