CBT: the thread to centralize your feedback
-
@StormMaster Thank you - I experienced that too , 2 backup plans with same VMs. Backup failed once out of two with error message "can't create a stream from a metadata VDI, fall back to a base"
-
@chr1st0ph9 i understand a fix is being made for this, @florent patched our proxy yesterday and since then no more fulls so far!
-
@rtjdamen Thats great news, with both block and file based SRs?
-
this branch ( already deployed on @rtjdamen systems) add a better handing of host that took too much time to compute the changed block list :
https://github.com/vatesfr/xen-orchestra/pull/8120it will be release in patch this week
I am still investigating an error that still occurs occasionally : XapiError: SR_BACKEND_FAILURE_460(, Failed to calculate changed blocks for given VDIs. [opterr=Source and target VDI are unrelated], )
-
@florent thanks for letting me know, on our end this error seems to occur on the same vms every time, it are just a handfull. Could it be these vms are facing higher load on them what causes xapi tasks to take longer then expected?
-
@rtjdamen @florent Be very curious to test this once it hits XOA.
The lab i am testing this a two host pool with each server having a 24 Core Epyc CPU and 256 GB of ram. There are only around 4 VMs running on this test environment currently and all are low load VMs.
Is it still something that mostly occurs with file based SRs? I never did get a chance to setup ISCSI and test with it instead of NFS.
Once this becomes stable there i definitely plan to switch to this backup method in production!
-
@flakpyro no on my end there is no difference for nfs or iscsi on XOA backups, we only had this issue with Alike Backup, my assumption was this would be the case in XOA as well, but not at this time.
What i found out is that one of my vms facing this issue has 2 disks, both on a different SR, i am moving one of the disks to the same SR and check tomorrow (tonight will be a full after migrating) if this is still the case there.
The other vm we face this issue on is has both disks on the same SR so that cannot be the case there. keep u posted on the results.
-
@rtjdamen we found a clue with @Bastien-Nollet : there was a race condition between the timeframe allowed to enable CBT and the snapshot, leading to a snapshot taken before CBT , thus failing to compute correctly the list of changed block at the next backup
The fix is deployed, and we'll see this night. If everything goes well, this night will be a full, but the disks will keep CBT enabled. And the next night, we'll have delta
if everything is ok, it will be released in a second patch ( 5.100.2 )
-
@florent sounds like a plan! i will keep an eye on them and let u know the results!
-
Hi,
I observed one issue with the backup process when the CBT is enabled. The case is showing when the VM has two disks on different SRs. When the backup tries to be taken, it fails, and the machine goes to a state where no other changes/reconfiguration is possible. It is not possible to disable CBT, move a disk to a different SR or create another backup. Sometimes after a failed backup the console access and machine are freezing. Everything works fine when all of the VM disks are on one SR.The logs from the first backup:

-
Hi @barwys
Can you provide more details? We need to know on which commit or XOA version you are
")
-
@olivierlambert Xen Orchestra, commit 804af
Both SRs are the shared storage by Fibre Channels connection (multipathing enabled). I tested on the Windows or Linux guest system as well. XenTools respectively 9.4.0/9.3.3 and 8.4.0-1 respectively. -
This commit is already a week old, please update to the latest one, rebuild and try again
-
Hello @olivierlambert,
After upgrading to commit 05c4e, I cannot reproduce this issue again. It seems to work much better.
Thanks -
Great! Please remember to always be on latest commit before reporting a problem, as you can see the code base is evolving fast
")
-
@olivierlambert Unfortunately after updating to 5.100.2 (XOA and Proxies) i am still running into XOA backups falling back to full after preforming a VM migration between two hosts within a pool when snapshot deletion is enabled. This doesnt happen if the snapshot is retained.
My test setup:
Servers: 2 x HP DL325 Gen 10 AMD Epyc Servers
Storage: TrueNAS Mini R running TrueNAS Scale 24.10 serving an NFS SR shared between both servers.
All VMs running on the same shared SR on the TrueNAS.Scenario:
VM 1 Migrated from Host A to Host B
VM 2 Migrated from Host B to Host ARunning a CBT with Snapshot delete backup after migration the VM between hosts while they remain on the same shared SR results in the error:
"Can't do delta with this vdi, transfer will be a full"
"Can't do delta, will try to get a full stream"Full log and screenshot of the error:
2024-11-14T19_20_40.383Z - backup NG.json.txt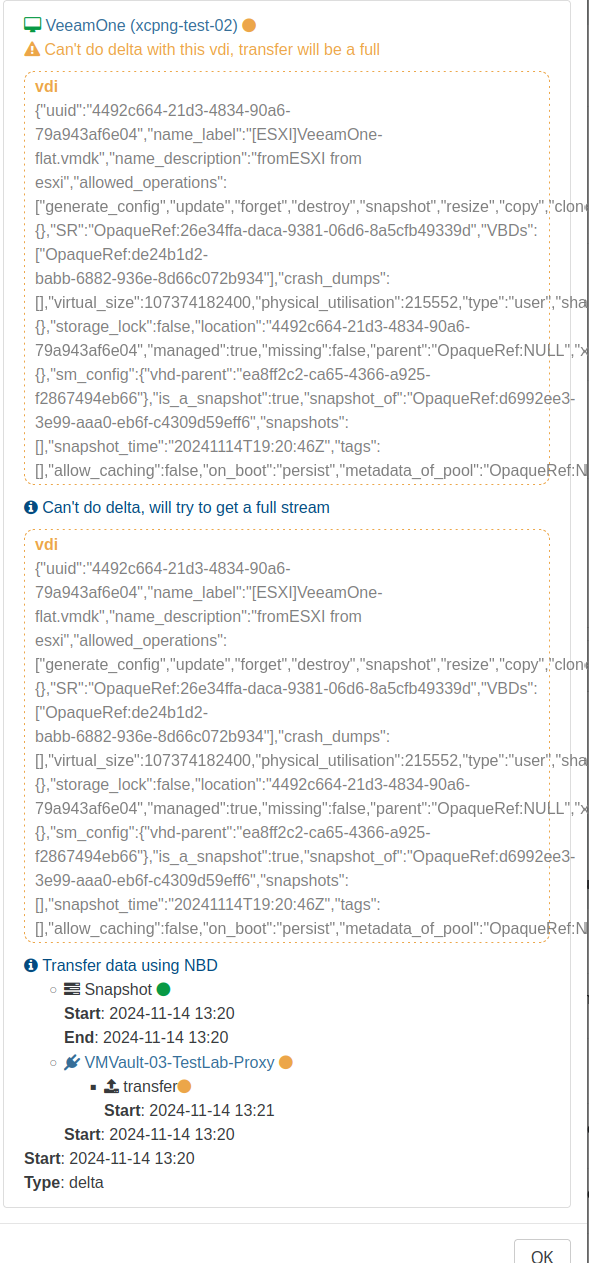
-
Sadly you are the only one we know we this problem that we cannot reproduce

I suppose we already checked that the VDI UUID doesn't change after the migration right?
-
@olivierlambert Yeah we did confirm the UUID does not change. These are VMs that were imported from VMware using the XOA wizard if that makes any difference.
The only other pool i have i could try on would be our production pool which is using CBT but is not removing the snapshot.
However if i migrate a VM between hosts on that pool and run a backup job i see this on the pool masters SMLog
Nov 14 21:06:50 xcpng-prd-03 SM: [3980818] Size of bitmap: 491520 Nov 14 21:06:50 xcpng-prd-03 SM: [3980818] lock: acquired /var/lock/sm/c63f7214-c1ef-4fc3-b174-cb78dffcbaa6/cbtlog Nov 14 21:06:50 xcpng-prd-03 SM: [3980818] ['/usr/sbin/cbt-util', 'get', '-n', '/var/run/sr-mount/16e4ecd2-583e-e2a0-5d3d-8e53ae9c1429/c63f7214-c1ef-4fc3-b174-cb78dffcbaa6.cbtlog', '-c'] Nov 14 21:06:50 xcpng-prd-03 SM: [3980818] pread SUCCESS Nov 14 21:06:50 xcpng-prd-03 SM: [3980818] lock: released /var/lock/sm/c63f7214-c1ef-4fc3-b174-cb78dffcbaa6/cbtlog Nov 14 21:06:50 xcpng-prd-03 SM: [3980818] Raising exception [460, Failed to calculate changed blocks for given VDIs. [opterr=Source and target VDI are unrelated]] Nov 14 21:06:50 xcpng-prd-03 SM: [3980818] ***** generic exception: vdi_list_changed_blocks: EXCEPTION <class 'xs_errors.SROSError'>, Failed to calculate changed blocks for given VDIs. [opterr=Source and target VDI are unrelated] Nov 14 21:06:50 xcpng-prd-03 SM: [3980818] File "/opt/xensource/sm/SRCommand.py", line 111, in run Nov 14 21:06:50 xcpng-prd-03 SM: [3980818] return self._run_locked(sr) Nov 14 21:06:50 xcpng-prd-03 SM: [3980818] File "/opt/xensource/sm/SRCommand.py", line 161, in _run_locked Nov 14 21:06:50 xcpng-prd-03 SM: [3980818] rv = self._run(sr, target) Nov 14 21:06:50 xcpng-prd-03 SM: [3980818] File "/opt/xensource/sm/SRCommand.py", line 326, in _run Nov 14 21:06:50 xcpng-prd-03 SM: [3980818] return target.list_changed_blocks() Nov 14 21:06:50 xcpng-prd-03 SM: [3980818] File "/opt/xensource/sm/VDI.py", line 757, in list_changed_blocks Nov 14 21:06:50 xcpng-prd-03 SM: [3980818] "Source and target VDI are unrelated") Nov 14 21:06:50 xcpng-prd-03 SM: [3980818] Nov 14 21:06:50 xcpng-prd-03 SM: [3980818] ***** NFS VHD: EXCEPTION <class 'xs_errors.SROSError'>, Failed to calculate changed blocks for given VDIs. [opterr=Source and target VDI are unrelated] Nov 14 21:06:50 xcpng-prd-03 SM: [3980818] File "/opt/xensource/sm/SRCommand.py", line 385, in run Nov 14 21:06:50 xcpng-prd-03 SM: [3980818] ret = cmd.run(sr) Nov 14 21:06:50 xcpng-prd-03 SM: [3980818] File "/opt/xensource/sm/SRCommand.py", line 111, in run Nov 14 21:06:50 xcpng-prd-03 SM: [3980818] return self._run_locked(sr) Nov 14 21:06:50 xcpng-prd-03 SM: [3980818] File "/opt/xensource/sm/SRCommand.py", line 161, in _run_locked -- Nov 14 21:07:05 xcpng-prd-03 SM: [3981883] Size of bitmap: 25165824 Nov 14 21:07:05 xcpng-prd-03 SM: [3981883] lock: acquired /var/lock/sm/90202d5b-8016-49a3-92dd-4790a2edaa41/cbtlog Nov 14 21:07:05 xcpng-prd-03 SM: [3981883] ['/usr/sbin/cbt-util', 'get', '-n', '/var/run/sr-mount/16e4ecd2-583e-e2a0-5d3d-8e53ae9c1429/90202d5b-8016-49a3-92dd-4790a2edaa41.cbtlog', '-c'] Nov 14 21:07:05 xcpng-prd-03 SM: [3981883] pread SUCCESS Nov 14 21:07:05 xcpng-prd-03 SM: [3981883] lock: released /var/lock/sm/90202d5b-8016-49a3-92dd-4790a2edaa41/cbtlog Nov 14 21:07:05 xcpng-prd-03 SM: [3981883] Raising exception [460, Failed to calculate changed blocks for given VDIs. [opterr=Source and target VDI are unrelated]] Nov 14 21:07:05 xcpng-prd-03 SM: [3981883] ***** generic exception: vdi_list_changed_blocks: EXCEPTION <class 'xs_errors.SROSError'>, Failed to calculate changed blocks for given VDIs. [opterr=Source and target VDI are unrelated] Nov 14 21:07:05 xcpng-prd-03 SM: [3981883] File "/opt/xensource/sm/SRCommand.py", line 111, in run Nov 14 21:07:05 xcpng-prd-03 SM: [3981883] return self._run_locked(sr) Nov 14 21:07:05 xcpng-prd-03 SM: [3981883] File "/opt/xensource/sm/SRCommand.py", line 161, in _run_locked Nov 14 21:07:05 xcpng-prd-03 SM: [3981883] rv = self._run(sr, target) Nov 14 21:07:05 xcpng-prd-03 SM: [3981883] File "/opt/xensource/sm/SRCommand.py", line 326, in _run Nov 14 21:07:05 xcpng-prd-03 SM: [3981883] return target.list_changed_blocks() Nov 14 21:07:05 xcpng-prd-03 SM: [3981883] File "/opt/xensource/sm/VDI.py", line 757, in list_changed_blocks Nov 14 21:07:05 xcpng-prd-03 SM: [3981883] "Source and target VDI are unrelated") Nov 14 21:07:05 xcpng-prd-03 SM: [3981883] Nov 14 21:07:05 xcpng-prd-03 SM: [3981883] ***** NFS VHD: EXCEPTION <class 'xs_errors.SROSError'>, Failed to calculate changed blocks for given VDIs. [opterr=Source and target VDI are unrelated] Nov 14 21:07:05 xcpng-prd-03 SM: [3981883] File "/opt/xensource/sm/SRCommand.py", line 385, in run Nov 14 21:07:05 xcpng-prd-03 SM: [3981883] ret = cmd.run(sr) Nov 14 21:07:05 xcpng-prd-03 SM: [3981883] File "/opt/xensource/sm/SRCommand.py", line 111, in run Nov 14 21:07:05 xcpng-prd-03 SM: [3981883] return self._run_locked(sr) Nov 14 21:07:05 xcpng-prd-03 SM: [3981883] File "/opt/xensource/sm/SRCommand.py", line 161, in _run_lockedThis goes away after the the initial backup run after the VM migration and all runs after result in nothing in the SMLog. Because i am not removing the snapshot the backup still runs as a delta however this leads me to believe if i enabled snapshot delete on that pool i would run into the same issue and a full backup would run instead.
I'm not sure what i would be doing that's unique to cause this. TestLab is NFS4 on a TrueNAS and Production is NFS3 on a Pure X20 array.
I will soon be able to test this on our DR site pool but we are currently waiting on hardware for that to arrive.
-
I have no idea why you are the only one to have this issue, which is why it's weird

-
@olivierlambert So today i installed the latest round of updates on the test pool which moved all the VMs back and forth during a rolling pool update. I then let everything sit for a couple hours then ran the backup job and this time it did not throw any errors. So thats even more confusing.
Perhaps its because i am kicking off a backup job immediately after migrating the VMs? As a test i am going to move them around again now, wait an hour then attempt to run the job.
Edit: Waiting did not seem to help. Running the job manually again resulted in a full being run again with the same
Can't do delta with this vdi, transfer will be a full
Can't do delta, will try to get a full stream
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login