CBT: the thread to centralize your feedback
-
From what i have seen if CBT fails for some reason, the chain is broken or the metadata is missing it will fall back on single NDB, most likely a new full.
-
Enabling the new Purge snapshot data when using CBT on Delta backups
results in
cleanVm: incorrect backup size in metadata. But it seems to be successful anyway.
Update: I'm getting this regardless of what "Purge snapshot data when using CBT" is set to. So I'm right now not sure about what causes it.XOsource: commit 96b76. ?

-
[NOBAK] tag is ignored with CBT patch.
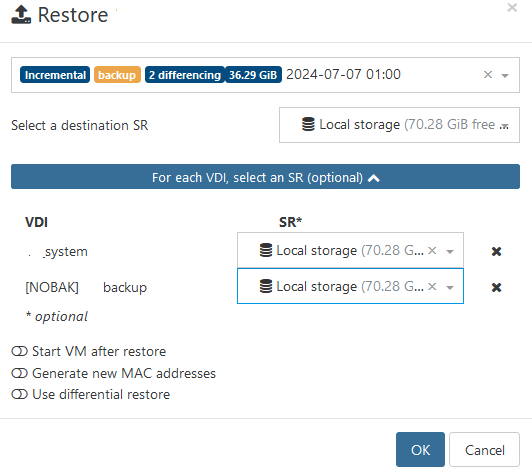
before update it works fine. no 2nd disk available for restore.
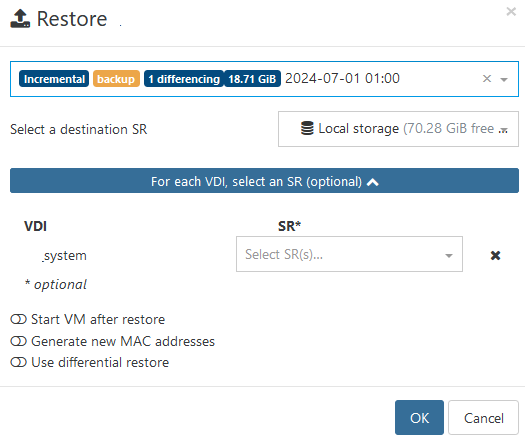
my share is run out of space)

-
@Tristis-Oris is it any way to remove only 1 disk backup chain, to not wait rotation? i can't just clear everything.
-
@ajpri1998 IIRC:
- CBT will be enabled as soon you use NBD, no other choice (having 2 different code paths was too prone to problems and bugs, without forgetting the initial VHD diff code)
- Sure, we can do that! Telling @Bastien-Nollet about it
")
-
I started seeing this error this afternoon.
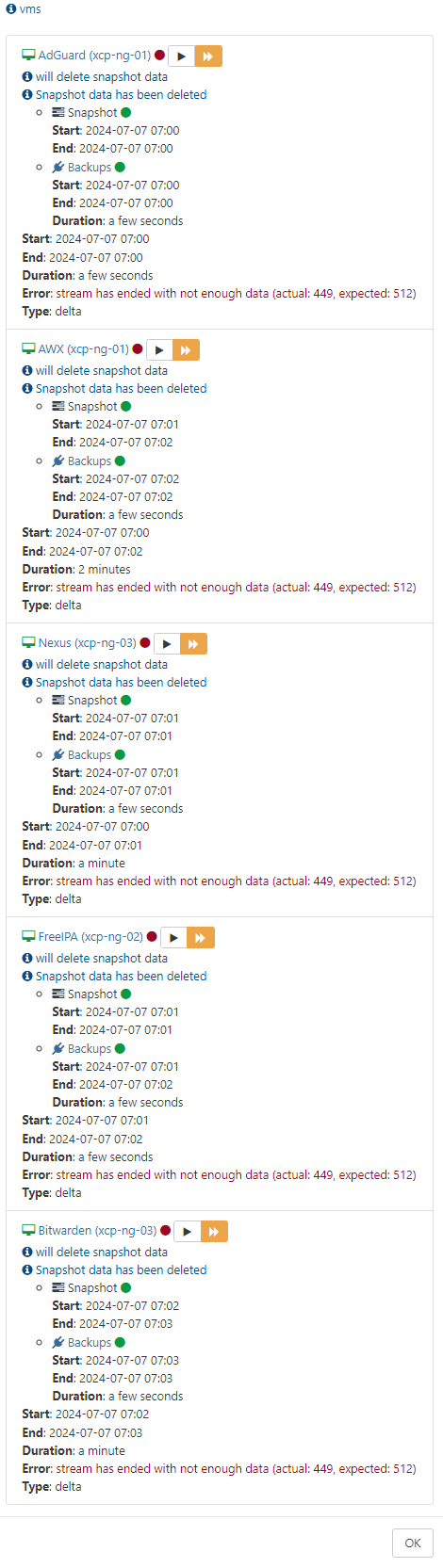
The failed job also happened to run after a monthly backup job that I have setup that does a full backup to some immutable storage that I have but I am not sure if it is related I just wanted to add that information. Below is the log from the failed backup.
2024-07-07T11_00_11.127Z - backup NG.json.txt -
@Delgado I saw those errors when I disabled/enabled CBT on disks or changed the NBD+CBT option in the backup job. If you have more than one job that works on the same VM you need to have the backup options the same.
I think that migrating the VDI to a different SR also changes the CBT setting.
-
@Andrew Thanks for the info! I had a feeling it may have been that one normal backup mode I ran. I'll stick to the deltas.
-
@olivierlambert Having a strange failure now (XO and XOA the same). I'm trying to migrate a VDI (only) to a new SR (same pool) after it has been backed up with CBT enabled. The VM is off (cold). XO disables CBT and requests the migration but the migrate fails and it tries again repeatedly endlessly. If I delete the snapshots then it moves.
-
@Delgado Full/CR/Delta backups should work as long as CBT is left enabled on the guest VDI and other backup jobs don't disable it.
-
@Andrew interesting thanks. I didn't disable nbd + cbt in the delta job or cbt on the disks. I just set up another job as a normal full backup mode.
-
@Andrew hi Andrew, when u migrate a vdi CBT has to be disabled, XO will take care off this. I think the snapshot has to be removed as well. Looks like the code for this is not functional yet.
-
Thanks for the feedback, @florent is back on Tuesday
-
@olivierlambert, I first want to compliment the work that has been done. As a first release, it already seems very stable. I have shared some logs with support to investigate the data_destroy issue and some minor error messages that appeared. We managed to migrate all our backup jobs to CBT over the weekend. It was challenging to coalesce all the snapshots, but it has been completed. The difference in coalesce speed is significant, which is a great improvement for XOA backups. I will monitor the backups and observe how they evolve in the coming weeks.
Please let us know if you need any additional input or if there are any updates regarding the data_destroy issue.
-
Thanks for the feedback @rtjdamen
We will do a full sweep with the feedback in this thread and continue to monitor the situation. Also, we switched our own production on it, so if there's issue we will also be on the first seat

-
A little question: in my environment i've big problem with SR migration.
i've opened a ticket and the answer is:
There is currently a problem with NBD backup where the VDI are not correctly disconnected from the Dom0.
The team is investigating but for now if you want to avoid more being accumulated, it is advised to disable NBD backups.
I've disabled NBD and for small SR work fine, for big SR i can't try (three days estimated for migration..)This problem is resolved?
Or i can't use CBT? -
It depends on the SR you are using. If it's XOSTOR or not. On XOSTOR, NBD is causing some challenges. But if it's a regular SR, the issue should be fixed since we are enforcing removal of VDI attached to the control domain.
-
@olivierlambert no xostor, sr is on fiber channel san (two san with some volumes, HDD or SSD)
may i try the reactivation of both? -
Without more context, I would say "yes"
CBT will reduce the amount to coalesce. Try to keep NBD "Number of NBD connection per disk" at 1 to be on the safe side. -
@olivierlambert @florent regarding the error
error {"code":"VDI_IN_USE","params":["OpaqueRef:fbd3bedd-ea60-4984-afca-9b2ec1b7b885","data_destroy"],"call":{"method":"VDI.data_destroy","params":["OpaqueRef:fbd3bedd-ea60-4984-afca-9b2ec1b7b885"]}} vdiRef "OpaqueRef:fbd3bedd-ea60-4984-afca-9b2ec1b7b885"As a test i did the command on this snapshot manually over ssh
xe vdi-data-destroy uuid=This seems to purge the snapshot data correct, so i believe this issue is temporary and maybe a retry itself during the backupjob does resolve it. We see it not so ofter but enough to investigate it more deeper.
Inside the Knowledgebase from xenserver i found this
VDI_IN_USE: The VDI snapshot is currently in use by another operation. Check that the VDI snapshot is not being accessed by another client or operation. Check that the VDI is not attached to a VM. If the VDI snapshot is connected to a VM snapshot by a VBD, you receive this error. Before you can run VDI.data_destroy on this VDI snapshot, you must remove the VM snapshot. Use VM.destroy to remove the VM snapshot.I believe the vdi.destroy is not yet finished complete before the data-destroy is issued, resulting in the vdi in use error.