MAP_DUPLICATE_KEY error in XOA backup - VM's wont START now!

-
Just an update on this:
we made sure all our server times were synced. issue happened again the next run.
just for shits and giggles we restarted toolstack on the all the hosts yesterday and the problem went away. no issues with the backup last night. maybe just a coincidence, we are continuing to monitor.
we also noticed that even though this CHOP error is coming up, snapshots are getting created
-
I have, what is hopefully a final update to this issue(s).
we upgraded to xoa version .99 a few weeks ago and the problem has now gone away. we suspect that some changes were made for timeouts in xoa that have resolved this , and a few other related problems.
-
 O olivierlambert marked this topic as a question on
O olivierlambert marked this topic as a question on
-
O olivierlambert has marked this topic as solved on
-
This problem is back with vengeance. after almost a year of no issues, we have upgraded to version 109.2 of XOA and boom... probably is back
XCP-NG servers are on 8.2.1 May 6th update
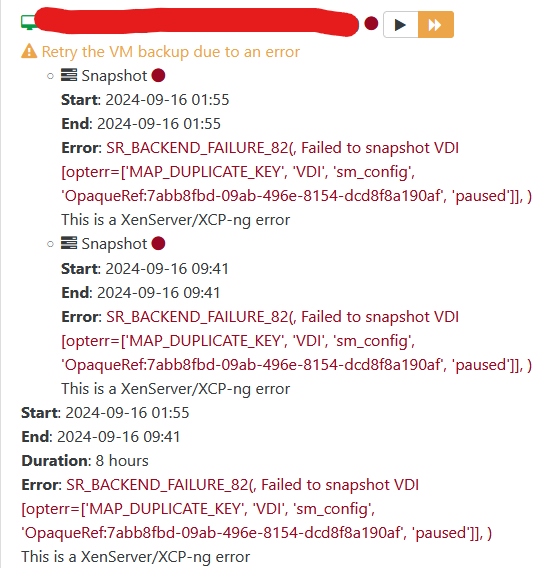
we get this following error in XOA
Error: SR_BACKEND_FAILURE_82(, Failed to snapshot VDI [opterr=failed to pause VDI 7d213264-1f89-488f-b273-eb91c186eaab], )
cant make snapshots of the effected VM anymore...
manual snapshots we get same error:
SR_BACKEND_FAILURE_82(, Failed to snapshot VDI [opterr=failed to pause VDI c51f22e2-ba5c-413b-8afc-9208a2b944ef],
but there is NO issues with the SR.failed 17 backups last night,
failed 3 backups tonight.
across 3 different storage arraysall those VM's we had to shut down and fix.
tapdisk connections to the disk have to be manually killed.we will double check all our interfaces again but i suspect it will be the same as last time:, no errors on networking or storage side.
something has changed, reverted.
-
It's hard to tell how it's triggered. Sometimes there are false correlations. It could be also a load on the SR, some concurrency/race conditions etc.
However, if you can reproduce the issue 100% of the time, then it's different. Those problems are really hard to pinpoint.
-
@olivierlambert the 3 truenas servers are very bored
") we be lucking to be hitting 10% of there abilities even during the backups.
we be lucking to be hitting 10% of there abilities even during the backups.i think i have stumbled across something that maybe a bug or the cause:
lets say we have 5 servers, VM getting this error during backups is running on server3, When this happens we power it down on server3 and clear the stuck tapdisk connections a log entry shows up saying a snapshot link on server5 was also cleared....
example: "Cleared RW for 7d213264-1f89-488f-b273-eb91c186eaab on host 14c98969-ae12-4d7f-9c42-d7656aae01e5 on server5"
... but the VM was running on server3.....so HERE is what i think is happening... just a theory... I think the load balance plugin is moving VMs around during the backup process. could that be possible?? i feel based on what i am seeing this could be the cause.
-
Hmmm that's a possibility. An interesting lead to explore. Ie trying to do it yourself to see if the result if the same?
-
@olivierlambert it has happened again
"XXXXX-nfs-02 (FAST all Flash Storage ZFS/NFS): failed to unpause tapdisk","Failed to unpause tapdisk for VDI ab867371-7a74-4a9f-88a9-9fb89e7dd3de, VMs using this tapdisk have lost access to the corresponding disk(s)","XXXXX XXXX-xcp Pool","Oct 23, 2025 8:18 PM",""
VM for this VDI had been running on host XXX-xcp-03 but there were attachments on the vdi from host XXX-xcp-07 .
we did not manually move this VM but it has moved.
I really think this problem is getting caused by load balancer moving things around while delta backups are running.
can we look into having XOA LB plugin NOT move VM's getting touched by the XOA backup processes?
-
Question for @pierrebrunet I assume
-
Hi @jshiells,
Sorry for not answering earlier, Pierre wasn't working during the past weeks.
I'll soon investigate on how the load balancer interacts with backups.
-
Hi @jshiells,
After some tests, I don't think it can be caused by the load balancer.
If the load balancer tries to migrate a VM that is being backed up, the migration instantly fails and nothing happens.
Reversely, if a backup job starts when a VM is being migrated by the load balancer, the backup will fail for that VM with error "cannot backup a VM currently being migrated".