There is no implementation in XAPI to "copy" VM to remote host (maybe XO has it own implementaion I'm not sure).
Copy works only localy.
You can only migrate it to remote host.
Disclaimer.
Everything you do on your own risk.
But you can do it manually by export/copy VDI from one host to another.
If you do not need "live" copy while VM is running, just stop VM, get all VBDs xe vbd-list vm-name-lable={VM-name}.
You will see all VBDs and VDIs of VM.
Go to certain SR cd /var/run/sr-mount/{SR-UUID} and copy VDI to new host's SR (you can use scp).
On destination host:
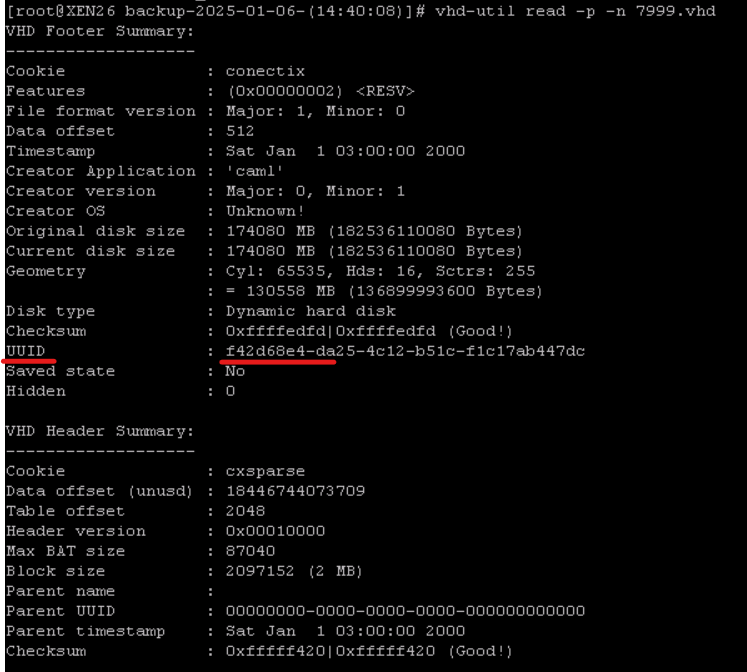
- Get new VDI UUID
vhd-util read -p -n {VDI-UUID}.vhd
- Rename file using this UUID
- Rescan SR on destination host.
- Create VM, attach VDI.
If VDI stored on "shared" SR (iSCSI, NFS, ceph rbd and etc...), firts you have to export VDI by command xe vdi-export uuid={VDI-UUID} filename={VM-Name_xvda}.vhd format=vhd --progress
After success export, copy to destination host, read, rename and etc....
If you need "live" migration you can do it with minimal down time via snapshot.
- Make snapshot with uniq name.
- List VBDs
xe vbd-list vm-name-lable={VM-name}.
- Export all VDIs
xe vdi-export uuid={VDI-UUID} filename={VM-Name_xvda}.vhd format=vhd --progress (repeat for all VDIs).
- Copy to destination host
- Use vhd-util to get new UUID and rename VDI
vhd-util read -p -n {VDI-UUID}.vhd
- Shutdown VM. Do not delete VM before it will not start successfully on "new" host!
- Get snapshot list
xe snapshot-list
- Get disks in snapshot
xe snapshot-disk-list uuid={snapshot_UUID}
- Export diff
xe vdi-export uuid={main_VDI_UUID_from_step_3} filename=2920_delta_xvda.vhd format=vhd base={snapshot_VDI_UUID_from_step_8)} --progress
- Copy diff to destination host
- Import diff
xe vdi-import uuid=VDI_UUID_from_step_5 filename=2920_delta_xvda.vhd format=vhd --progress
") ).
).