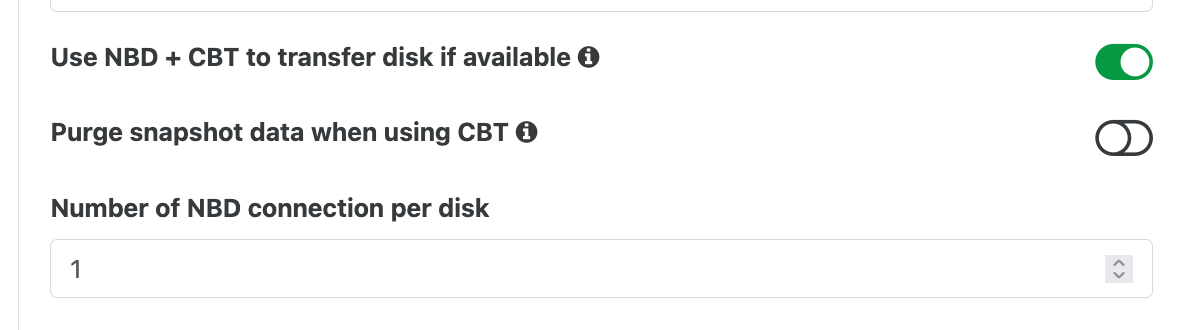
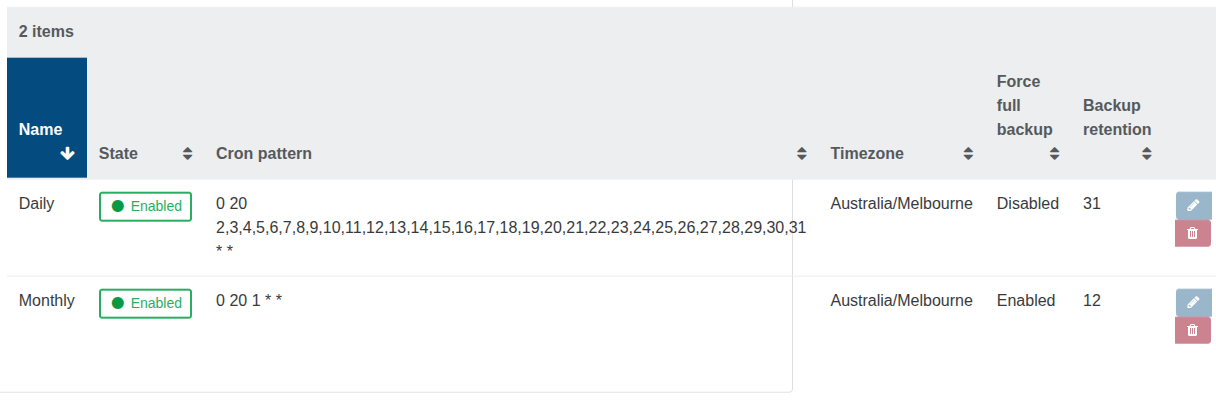
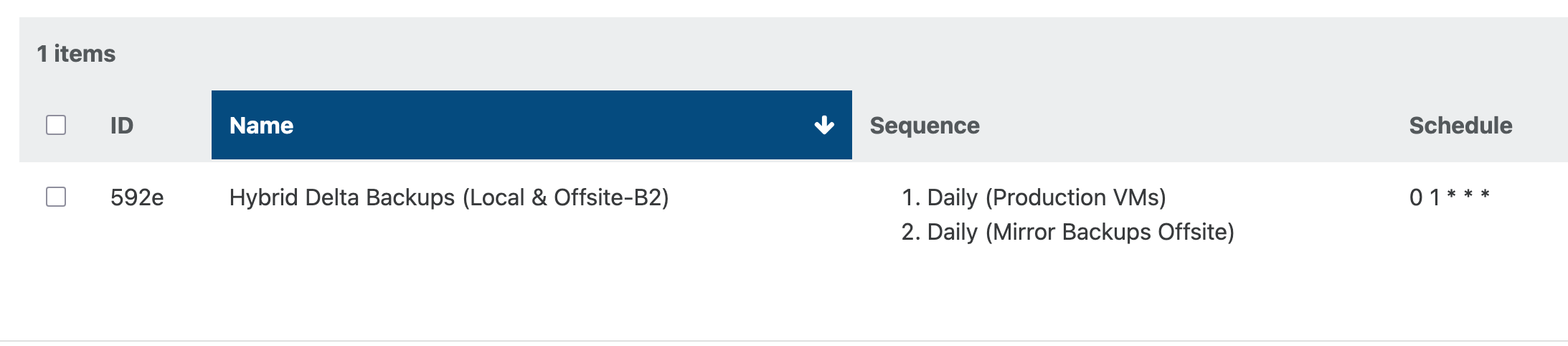
@yeopil21 Run top, xentop, and iostat to see if dom0 and.or the storage device might be a bottleneck. The configuration of your storage device can also be a big factor,
and in some casaes, various performance tweaks are possible. The specific configuration would be helpful: connectivity (NFS, fibre channel, iSCSI), number and size and speeds of disks, RAID configuration, total number of VMs resident on the device, number of independent SRs, provisioning (thin or thick), network (if not fibre channel) speed and settings.
STorage optimization is a bit of an art and in many cases, can be the limiting factor, but as stated, so can the lack of dom0 resources. Also, what clock speed and number of CPUs are on your hosts?