backup mail report says INTERRUPTED but it's not ?

-
@Pilow Thanks, it's promising but we'll wait for more runs on your side
") If it's that, at least it's not a biggie in the end!
If it's that, at least it's not a biggie in the end! -
I agree, let's wait for more runs.
If it's indeed a race condition, we'll still have to figure out a better way to settle this than just adding delay
-
@Bastien-Nollet new day without false INTERRUPTED
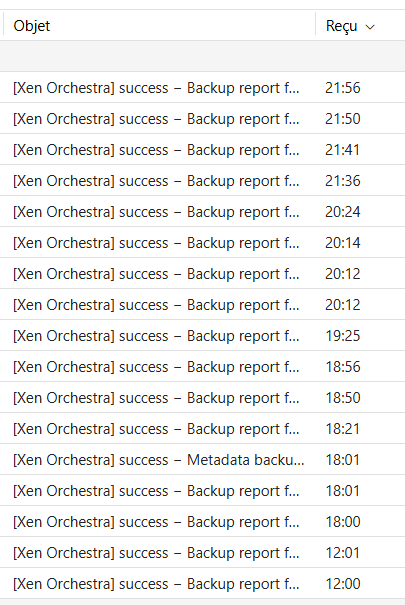
the scrutiny of backup email reports made me find a new bug in backups (not reports this time)
i'll create a new topic about the dreaded BACKUP FELL BACK TO A FULL --> can provoke it on purpose ! -
Thanks @Pilow for the tests.
We'll have to investigate this to fix it more properly than adding a ugly delay.
-
@Bastien-Nollet another good day
I think i'll swap to feedback if problem is back than problem is not here anymore
")
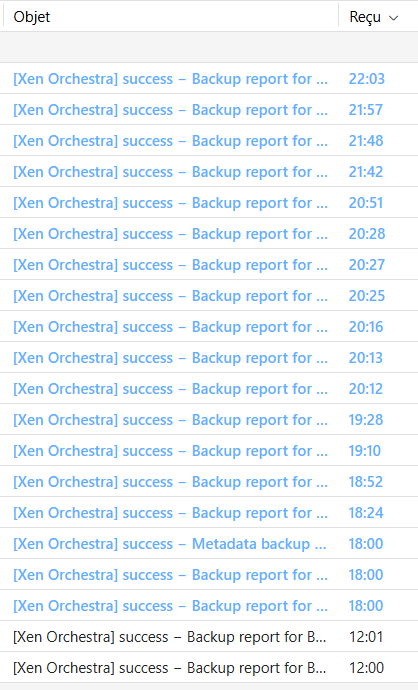
on your side to find something sexier than delay ^^' but it seems to be a race condition
-
Hi @Pilow,
Thanks again for the feedback, I think now we have enough data to be sure it's indeed a race condition.
We noticed that the log you sent earlier in this topic is a backup job using a proxy. Could you tell if the backup jobs that ended up with a wrong status in the report were all using a proxy, or not all of them?
-
@Bastien-Nollet 100% of our backup jobs are done by proxy
we offload that of main XOA that is purely for administration/management -
Hi @Pilow,
I've done some more testing and looked at the code, and I wasn't able to reproduce this behaviour once. It's also unclear to me why it can happen.
We may just add the delay as you did, but 10s is probably too long. Could you try to replace it by a 1s delay instead, and tell us if it's enough?
-
@Bastien-Nollet okay i'll do that tonight and will report back
-
26 backups in a row without interruption, spanning 2 days
And i'm on the 1 second fixguess it is enough...
@Bastien-Nollet said in backup mail report says INTERRUPTED but it's not ?:
I've done some more testing and looked at the code, and I wasn't able to reproduce this behaviour once. It's also unclear to me why it can happen.
I didn't tell but my Remotes are S3 Remotes... could it be because of that ?
-
Thanks again @Pilow
I don't think the remotes being S3 changes something here.
-
@Bastien-Nollet oopsy.
sadly, INTERRUPTED is back....
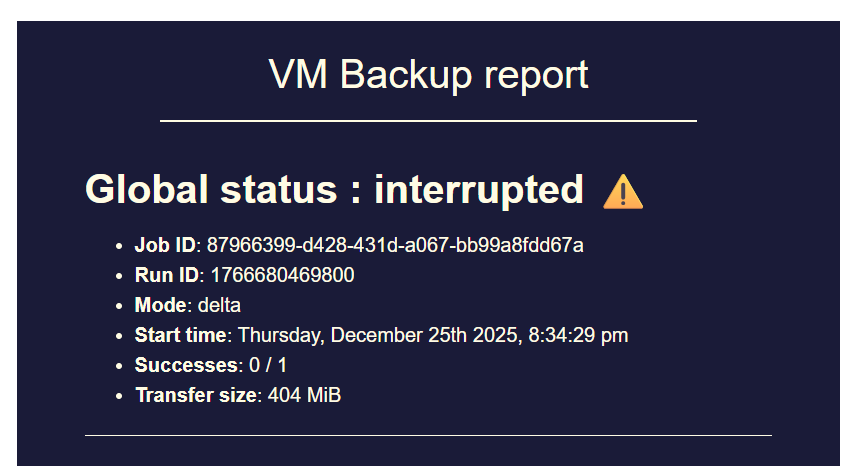
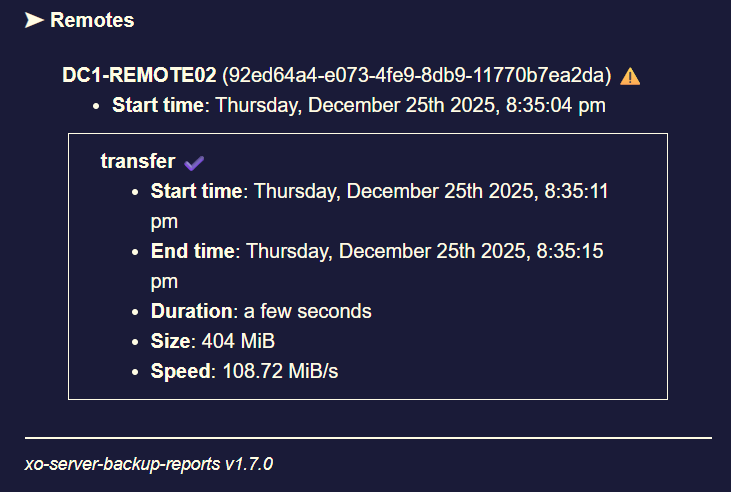
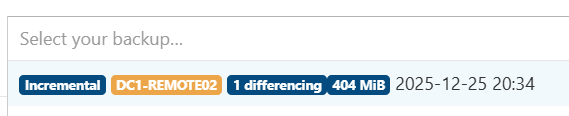
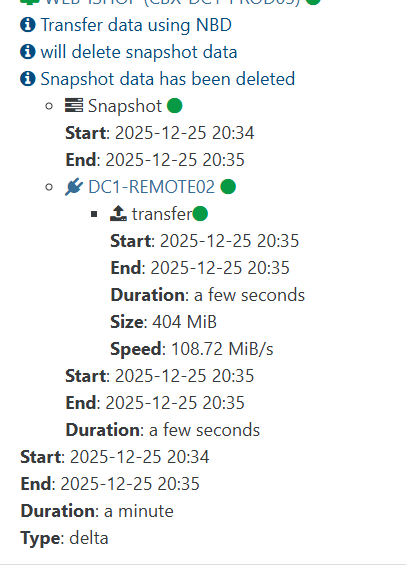
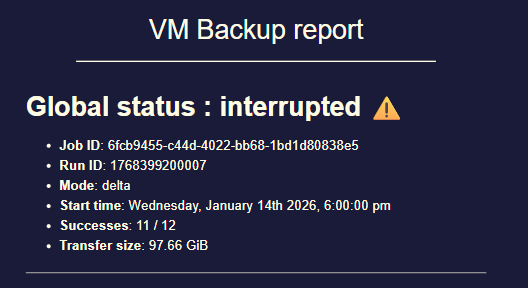
this is what I see in the backup report (a backup job of 12VMs to same S3 remote, only 1 interrupted...)

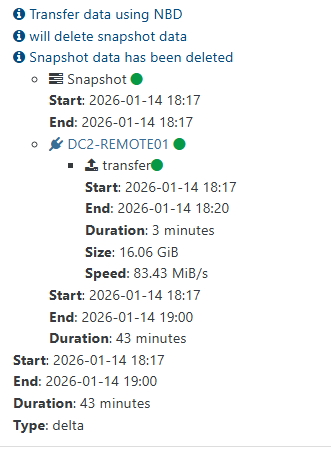
backup JOB in XOA is all green :

-
Ok so 1s is slightly not enough, thanks for the update.
-
@Bastien-Nollet another interrupted today.
I'll add one second by one second till I see it disappear.just modified to 2s delay.
-
@Bastien-Nollet said in backup mail report says INTERRUPTED but it's not ?:
Ok so 1s is slightly not enough, thanks for the update.
Reply
still had issues with 2 sec delay.
it has now been 2 days with 3 sec delay, and no more. could be the sweet spot
-
We're still carrying a bit of investigations to see if we can find the cause of the problem, but if we don't find it we'll add this delay.
Thanks @Pilow for the tests once again
-
We just merged the delay: https://github.com/vatesfr/xen-orchestra/pull/9400
We increased it to 5s to have a security margin, as the optimal delay may not be the same on different configurations.
-
@Bastien-Nollet many thanks
-
Hey,
sadly issue seems to still exist...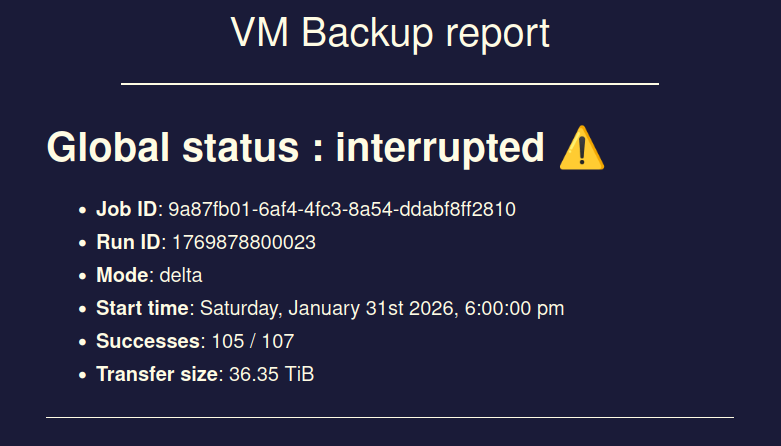
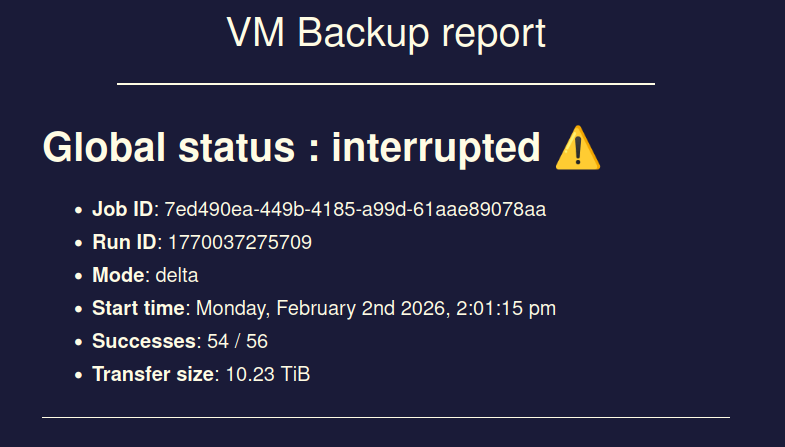
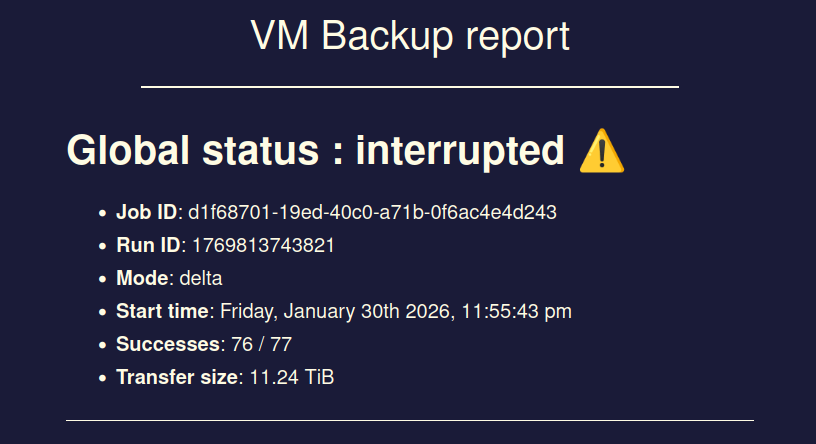
I had 3 backup jobs running at the same time, all of them went into status "interrupted" at the exact same timestamp without me doing anything.
Xen Orchestra did not crash, XO VM has enough RAM, no OOM errors in log or similar.Interestingly the XO VM seems to still send data to the backup remotes even though the jobs show status interrupted.
This exact same issue happened 1 more time in the past but I thought maybe it is only a one-time-hiccup which is why I did not report it here at that point.
Issue first occurred somewhere around the release of XO6, before the XO6 I never had this kind of issue.
Best regards
//EDIT:
maybe to add some relevant info here. I am using XO from sources on Debian 13, NodeJS 24,
Commit fa110ed9c92acf03447f5ee3f309ef6861a4a0d4 ("feat: release 6.1.0").//EDIT2: Oh I just read in the initial post of this thread that on Pilow's end XO GUI reported success for the backup tasks but the emails indicated otherwise.
In my case the tasks also have status "interrupted" in XO GUI (and in the emails aswell as shown via screenshots).//EDIT3: I checked Xen Orchestra logs at the timestamp the backup jobs went into "interrupted" status, please find the log file attached below.
xo-log.txt
Based on the log file it looks like the Node JS process went OOM?
This is really strange as my XO VM has quite a lot of resources (8 vCPU, 10GB RAM). I checked in htop on the XO VM and it never went above 5GB during backups...//EDIT4: I did some research and found that some people had success with limiting their Node JS heap via environment variable.
I setexport NODE_OPTIONS="--max-old-space-size=6144"and will check if that fixes the issue for me.
-
@MajorP93 said in backup mail report says INTERRUPTED but it's not ?:
Hey,
sadly issue seems to still exist...
I had 3 backup jobs running at the same time, all of them went into status "interrupted" at the exact same timestamp without me doing anything.
Xen Orchestra did not crash, XO VM has enough RAM, no OOM errors in log or similar.Interestingly the XO VM seems to still send data to the backup remotes even though the jobs show status interrupted.
This exact same issue happened 1 more time in the past but I thought maybe it is only a one-time-hiccup which is why I did not report it here at that point.
Issue first occurred somewhere around the release of XO6, before the XO6 I never had this kind of issue.
Best regards
//EDIT:
maybe to add some relevant info here. I am using XO from sources on Debian 13, NodeJS 24,
Commit fa110ed9c92acf03447f5ee3f309ef6861a4a0d4 ("feat: release 6.1.0").//EDIT2: Oh I just read in the initial post of this thread that on Pilow's end XO GUI reported success for the backup tasks but the emails indicated otherwise.
In my case the tasks also have status "interrupted" in XO GUI (and in the emails aswell as shown via screenshots).//EDIT3: I checked Xen Orchestra logs at the timestamp the backup jobs went into "interrupted" status, please find the log file attached below.
xo-log.txt
Based on the log file it looks like the Node JS process went OOM?
This is really strange as my XO VM has quite a lot of resources (8 vCPU, 10GB RAM). I checked in htop on the XO VM and it never went above 5GB during backups...It may be due to RSS memory requirements suddenly spiking, for NodeJS when it goes under load, running Xen Orchestra and backup operations (depending on where used can be particularly heavy).
@bastien-nollet @florent @olivierlambert Maybe worth looking into memory loads, for the NodeJS process when running heavy operations, for Xen Orchestra. Maybe necessary to contribute fixes, optimisations and/or medium to long term switch from NodeJS to something else.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login