the writer IncrementalRemoteWriter has failed the step writer.beforeBackup() with error Lock file is already being held. It won't be used anymore in this job execution.
-
@olivierlambert XO Xen Orchestra, commit 987e9
Master, commit ef636 -
I'm not sure to understand, why two different commit numbers?
-
@olivierlambert That's the last update I did yesterday.....
Just updated now to latest: Xen Orchestra, commit ef636
Master, commit ef636 -
Do you have the issue on XOA?
-
@olivierlambert @Business with XOA no. Only HomeLab with XO but it has been rockstable until this.
-
this happens when 2 backup jobs are working on the same VM , or a backup and a background merge worker .
If it's the first case, you can use a job sequence to ensure the backup run one after anotherIf it's the latter, you have a check box to ensure the merge is done directly inside the job (bottom of the advanced settings of the backup job ), instead of doing this in a background job. It will slow down a little the job, but ensure it's completely done.
-
@florent No other backup is running as I mentioned!
And "Merge backups synchronously" is on as mentioned.
This is not it.....
-
@manilx are there multiple job running on the same VM ?
-
@florent Only one single backup job every 2hrs (multiple VM's). Running fore more than 1year without issues (not counting the initianl cbt stuff).

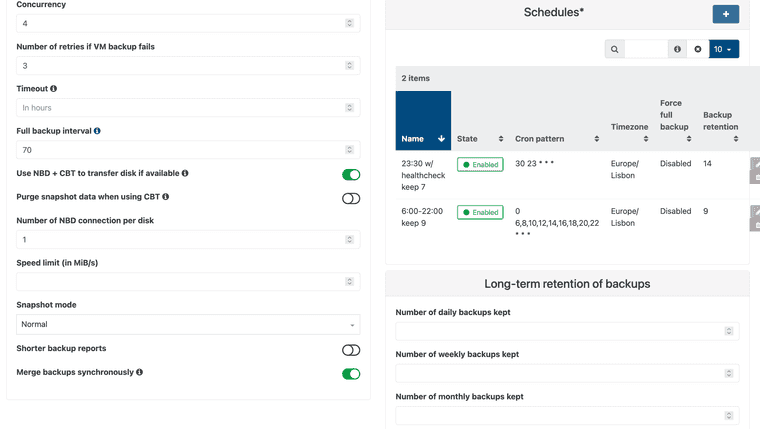
-
@florent This make no sense. There has to be some leftover sometimes of a lock file.
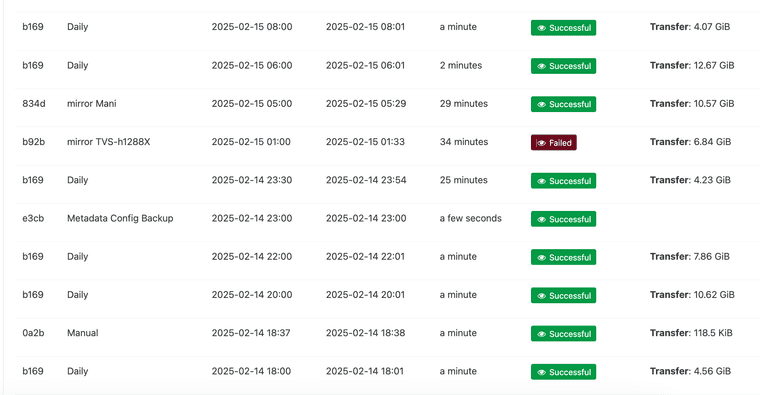
-
So I started getting this a few days ago as well. My backups have been fine for over a year until now, they are constantly failing at random. They will usually succeed just fine if I restart the failed backup. I am currently on commit 494ea. I haven't had time to delve into this though. I just found this post when initially googling.
-
That's interesting feedback, maybe a recently introduced bug. Could you try to go on an older commit to see if you can identify the culprit?
-
@SudoOracle Thx for chiming in!
Glad to know I'm not alone.
-
@olivierlambert I went back to my prior version, which was commit 04dd9. And the very next backup finished successfully. Not sure if this was a fluke, but I have backups going every 2 hours and this was the first to finish successfully today without me clicking the button to retry the backup. I'll report tomorrow on whether they continue to work or not.
-
Okay great, you can use
git bisectto easily find the culprit. Now we also need to find the common situation between you and @manilx : type of backup, advanced options enabled, type of BR, and so on to also understand more about this. -
@olivierlambert I have changed my backup strategy because of that:
Before:
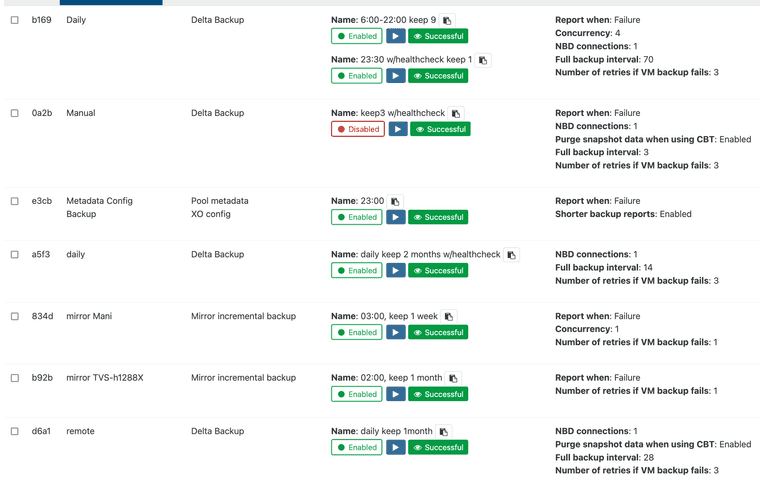
Now:
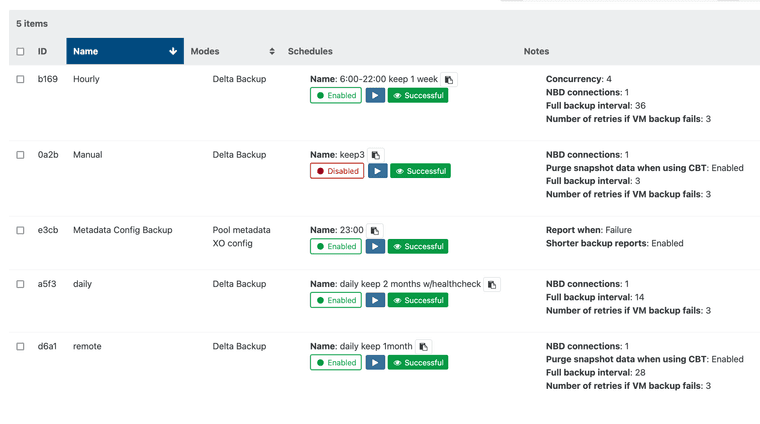
After this the problem did no longer occur.
-
Can you sum up what you did? I admit I don't have enough time to investigate differences between 2 screenshots

-
@olivierlambert Sure!
I had a main backup job running 2 schedules, on bihourly and one last one at the end of the day, the latter one with healthcheck.
Then I had 2 Mirror incremental ones running after that, one to a local NAS and one to a remote NAS @office.
I now have separate backups for the bihourly, end of day and the 2 mirror ones (now they are delta backups directly to the NAS'es).
I hope this explains it.
-
Thanks. As soon the commit generating the error is identified, this will be very helpful for @florent
")
-
@olivierlambert I can then restore the config and retest once it's identified/fixed.... But just now I need the backups working without issues
")
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login