Issue with SR and coalesce
-
@olivierlambert restarted the master, nothing happened
-
It's really hard to tell, have you restarted also all the other pool members?
-
We are having this exact same issue and I have posted in the Discord server to no avail
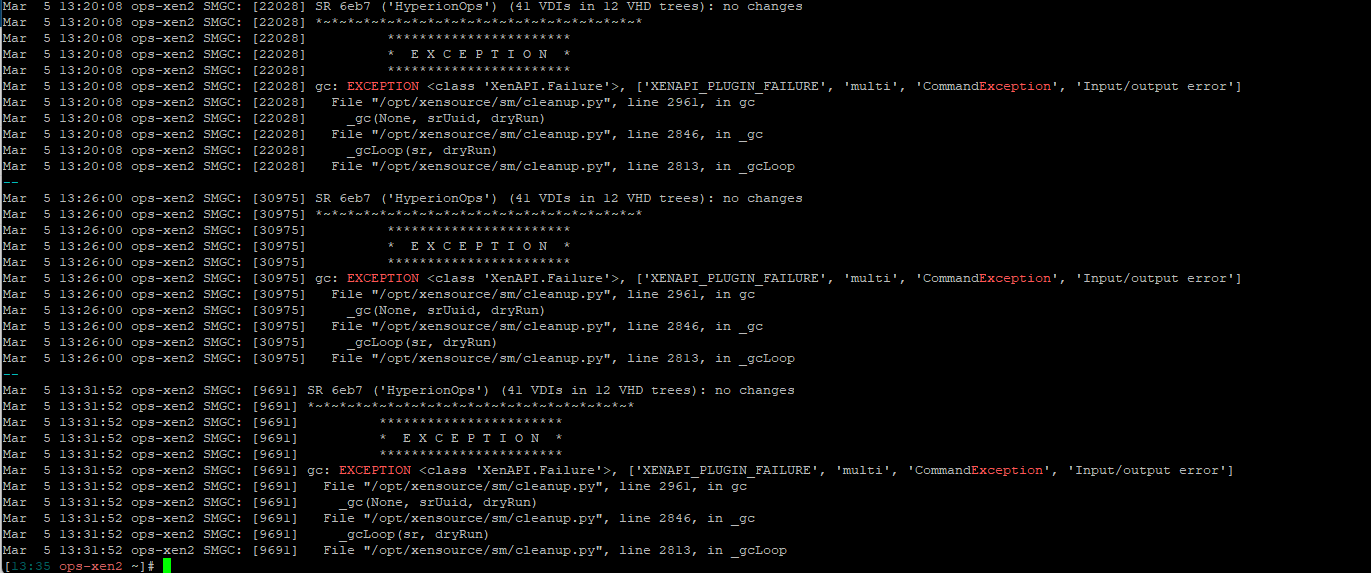
Mar 5 10:05:57 ops-xen2 SMGC: [25218] *~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~* Mar 5 10:05:57 ops-xen2 SMGC: [25218] *********************** Mar 5 10:05:57 ops-xen2 SMGC: [25218] * E X C E P T I O N * Mar 5 10:05:57 ops-xen2 SMGC: [25218] *********************** Mar 5 10:05:57 ops-xen2 SMGC: [25218] gc: EXCEPTION <class 'XenAPI.Failure'>, ['XENAPI_PLUGIN_FAILURE', 'multi', 'CommandException', 'Input/output error'] Mar 5 10:05:57 ops-xen2 SMGC: [25218] File "/opt/xensource/sm/cleanup.py", line 2961, in gc Mar 5 10:05:57 ops-xen2 SMGC: [25218] _gc(None, srUuid, dryRun) Mar 5 10:05:57 ops-xen2 SMGC: [25218] File "/opt/xensource/sm/cleanup.py", line 2846, in _gc Mar 5 10:05:57 ops-xen2 SMGC: [25218] _gcLoop(sr, dryRun) Mar 5 10:05:57 ops-xen2 SMGC: [25218] File "/opt/xensource/sm/cleanup.py", line 2813, in _gcLoop Mar 5 10:05:57 ops-xen2 SMGC: [25218] sr.garbageCollect(dryRun) Mar 5 10:05:57 ops-xen2 SMGC: [25218] File "/opt/xensource/sm/cleanup.py", line 1651, in garbageCollect Mar 5 10:05:57 ops-xen2 SMGC: [25218] self.deleteVDIs(vdiList) Mar 5 10:05:57 ops-xen2 SMGC: [25218] File "/opt/xensource/sm/cleanup.py", line 1665, in deleteVDIs Mar 5 10:05:57 ops-xen2 SMGC: [25218] self.deleteVDI(vdi) Mar 5 10:05:57 ops-xen2 SMGC: [25218] File "/opt/xensource/sm/cleanup.py", line 2426, in deleteVDI Mar 5 10:05:57 ops-xen2 SMGC: [25218] self._checkSlaves(vdi) Mar 5 10:05:57 ops-xen2 SMGC: [25218] File "/opt/xensource/sm/cleanup.py", line 2650, in _checkSlaves Mar 5 10:05:57 ops-xen2 SMGC: [25218] self.xapi.ensureInactive(hostRef, args) Mar 5 10:05:57 ops-xen2 SMGC: [25218] File "/opt/xensource/sm/cleanup.py", line 332, in ensureInactive Mar 5 10:05:57 ops-xen2 SMGC: [25218] hostRef, self.PLUGIN_ON_SLAVE, "multi", args) Mar 5 10:05:57 ops-xen2 SMGC: [25218] File "/usr/lib/python2.7/site-packages/XenAPI.py", line 264, in __call__ Mar 5 10:05:57 ops-xen2 SMGC: [25218] return self.__send(self.__name, args) Mar 5 10:05:57 ops-xen2 SMGC: [25218] File "/usr/lib/python2.7/site-packages/XenAPI.py", line 160, in xenapi_request Mar 5 10:05:57 ops-xen2 SMGC: [25218] result = _parse_result(getattr(self, methodname)(*full_params)) Mar 5 10:05:57 ops-xen2 SMGC: [25218] File "/usr/lib/python2.7/site-packages/XenAPI.py", line 238, in _parse_result Mar 5 10:05:57 ops-xen2 SMGC: [25218] raise Failure(result['ErrorDescription']) Mar 5 10:05:57 ops-xen2 SMGC: [25218] Mar 5 10:05:57 ops-xen2 SMGC: [25218] *~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~* -
This seems to be a Python code error ? Could this be a bug in the GC script ?
-

Just updated a day ago,
All of these backups that are failing have no existing Snapshots

This seems to be because each one has 3 (one has 4) base copies as its not coalescing
Output of grep -A 5 -B 5 -i exception /var/log/SMlog
-
@olivierlambert said in Issue with SR and coalesce:
It's really hard to tell, have you restarted also all the other pool members?
It resolved after i migrate from the SR to another (or to XCP host local storage). But we have scheduled backup jobs running everyday and i'm noticing the VDI to coalesce number is growing up again on these storages.
@Byte_Smarter said in Issue with SR and coalesce:
This seems to be a Python code error ? Could this be a bug in the GC script ?
I think so
-
Hi, this XAPI plugin
multiis called on another host but is failing with IOError.
It's doing a few things on a host related to LVM handling.
It's failing on one of them, you should look into the one having the error to have the full error in SMlog of the host.
The plugin itself is located in/etc/xapi.d/plugins/on-slave, it's the function namedmulti. -
As replied by @dthenot you need to check /var/log/SMlog on all of your hosts to see which one it is failing on and why.
If the storage filled up before this started to happend my guess is that there is something corrupted, if that's the case you might have to clean up manually.I've had this situation once and got help from XOA support, they had to manually clean up some old snapshots and after doing so we triggered a new coalescale (rescan the storage) which were able to clean up the queue.
Untill that's finished I wouldn't run any backups, since that might cause more problems but also slow down the coalescale process. -
In our case there are 0 Snapshots as these are backups restored on a new SR, so I am not sure what there is to coalesce.
We get this when running:
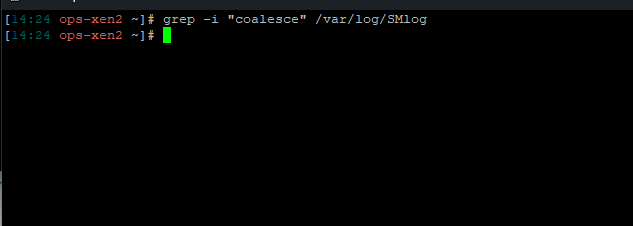
grep -i "coalescale" /var/log/SMlog
We get this when running:
grep -A 5 -B 5 -i exception /var/log/SMlog(Was advised from Discord to find issues with Coalescing)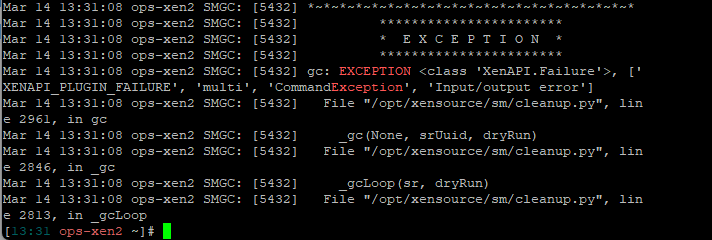
As far as all the hosts ONLY the master which is 'ops-xen2' is showing the logs errors posted earlier.
In theory the only snapshots these should have are the ones taken during the backup process but it never makes these and skips the VMs we want backed up that are the issue here
The SR has several TB of free space and is using ISCSI and is running on its own storage network, along with the fact no VMs running on that SR are showing any issues with the SR IOPS. I am not thinking this is a SR related issues (I can be wrong here)
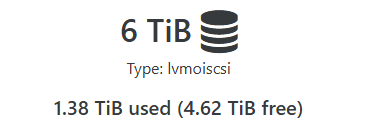
As far as what was posted about the Multi plugin while informative what should I be looking for in the entirety of the SMLog?
These host are running version 8.1.0 and have been running for a decent time so that could be a issue here, we are looking at possibly moving all VMs that are at issue to a totally new host/pool to see if the hosts are the issue.
There are 10 VM's in this pool 5 of them are on a older NAS that we are wanting to replace we have not moved any more over as this issue kind of makes us not want to finish moving them all over until we are secure. We have 5 on the same pool in that new SR I mentioned and from both speed and IOPS seem to be fine and no errors to be seen with the SR.
If we shut down the 5 VM's that are currently an issue they can run the backups just fine but you can not run the backups if they are running.
I don't mind doing the work to fix the issues, I am just still in the process of finding out what the issue that I need to fix is. I would really like if someone has 15 mins to go over the logs with us from XCP and maybe point us in some sort of direction to resolve the issues we are seeing as it does not seem to fall into issues that are in the documentation or the Discord.
-
@Byte_Smarter said in Issue with SR and coalesce:
We get this when running: grep -i "coalescale" /var/log/SMlog
Maybe try with
coalesceinstead -
-
Also ran on the other hosts in pool

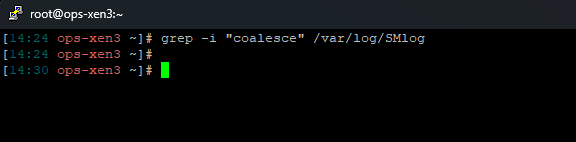
I am assuming that this means its not even attempting to coalesce?
-
@Byte_Smarter
Sorry, can't help You
-
I am sorry too LOL
-
@lucasljorge I don't want to feel like I hijacked your post, are you still having the issues posted ?
-
its ok buddy, please don't feel it, i'm following the discussion and trying to figure out whats happening too.
I added another SR and i'm monitoring the status. Still having performance issues (1 SR is SAS) but, the coalesce number seems to be finally decreasing.
Watching out the backup jobs running and keep you all in touch -
-
Yeah I am at a loss restored systems from Full backups onto a new SR multiple times and it just will not let us backup while they run, turn them off works fine.
Its like XCP's failing to make a snapshot, but you can make snapshots manually and its fine.
Maybe new SR is broken? if that's the case how does that happen when it was just created and added. If there a SR repair tool?
I can not find the error we are getting anywhere and the fact it does not have any logs of coalescing makes me thing its just not doing its job.
-
@lucasljorge How full is the storage, percentage-wise? If over around 90%, a coalesce operation sometimes will not work. You may have to shuffle some of your VM storage to a different SR.
If your host is not responding, you may have to do a reboot to clear out stuck taks if the "xe task-cancel" command isn't working. -
@Byte_Smarter hard to tell whats happening. The Xen version here is 8.2
I read somewhere in other XCP documentation, that the SR has to be at least 30% free to do backup and coalesce jobs properly.
I think that was the problem here, the SR went full and we're unable to run any job. But i had to recreate the old SR to get a success response from Orchestra.
Did you try to migrate the VDI's to another SR?

Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login