XO Community edition backups dont work as of build 6b263
-
FWIW: The XO Community edition backups don't work as of build 6b263. If you roll back to commit 19412 they work fine.
The longer error is:
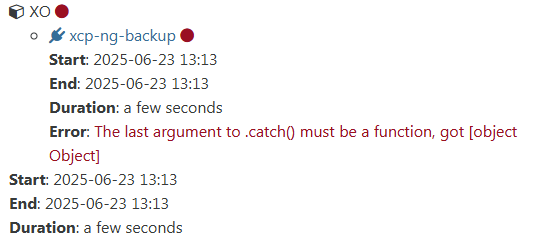
"Error: The last argument to .catch() must be a function, got [object Object]"" "result": {
"message": "The last argument to .catch() must be a function, got [object Object]",
"name": "TypeError",
"stack": "TypeError: The last argument to .catch() must be a function, got [object Object]\n at Promise.caught.Promise.catch (/opt/xo/xo-builds/xen-orchestra-202506201840/node_modules/bluebird/js/release/promise.js:130:19)\n at /opt/xo/xo-builds/xen-orchestra-202506201840/@xen-orchestra/fs/src/abstract.js:717:43\n at next (/opt/xo/xo-builds/xen-orchestra-202506201840/@vates/async-each/index.js:90:37)"
}" -
@archw I can confirm this. My backup start with the first 2 VM's being backed up but then stall.
Reverted back.
-
M manilx referenced this topic on
-
Hi,
Thanks for the report, I'm making sure it's known internally. Ping @lsouai-vates
-
Same here, all backups fail with 6b263
-
I am currently experiencing this issue since updating to the latest version.
How do I roll back to a previous commit? So that I can at least try to get a backup tonight.
Thanks
-
@wf said in XO Community edition backups dont work as of build 6b263:
How do I roll back to a previous commit?
git checkout <target commit>Then rebuild with
yarn; yarn build -
Hi,
Having the same issue, took me a while to figure out that it was a bug as the last backup got interrupted during a power failure and I thought the issues was to do with that! I reverted to a snapshot pre xoa update and it seems to be working now.
-
-
@archw said in XO Community edition backups dont work as of build 6b263:
The last argument to .catch() must be a function, got [object Object]
thanks for the reports
we are testing the fix ( https://github.com/vatesfr/xen-orchestra/pull/8739 )This may be bigger than a simple typo, this code last changes was 2 years ago
We reworked the timeout/retry mechanic of the unlink method as that doesn't perform as well as expected on some object storage backend, expecting new clues on how to improve the situation.
And you reports (24h after the merges) pointed us to a possible solution : We were deleting up to 10^depth files in parallel instead of 2^depth. -
@florent commit 035f5 still seems not to work. Meta Data Backup lasts a few seconds but now it is starting for 2 minutes without doing anything.
-
@uwood a metadata backup shouldn't trigger any timeout
I am retesting it -
@florent meta data backups make the same problems as normal backups. with commit 85868 the problem still exists.
-
 A acebmxer referenced this topic on
A acebmxer referenced this topic on
-
commit 040ae Meta Data Backup fails now instantly.
-
@uwood the fix regarding the "catch" error is still in review, will probably be merged in a few hours
the second fix regarding the stuck stream ( so pool metadata, full backup and disaster recovery) is merged . This one was effectively added in friday's PR
-
second fix is merged
Can you retest master, latest commit ? -
@florent Just updated, and the pool metadata and XO config backup seems to be working. Running the main back up right now and seems to be running fine.
-
@florent commit 1a7b5 seems to work now. meta backup has run succesfully and other backup has run ok too.
-
I've updated to the latest master as well (1a7b5) and my metadata/config backups completed successfully, as did my smaller test backup. However, only 16 of 19 VMs in my main backup job completed. I am re-running the main backup now and will report back if the error recurs.
Update: The job is still running, but here is the error from the three VMs that failed previously: "Error: invalid HTTP header in response body"
-
@katapaltes I did have that HTTP error before, but everything is running successfully now. I'm getting " cleanVm: incorrect backup size in metadata" on all the VMs, but not sure if that's related - it was happening before so not sure if it's related to my power faliure.
-
Yes, you will always see those "cleanVm: incorrect backup size in metadata" warnings, and Vates has said that it's OK to ignore them. You won't see them if you "Store backup as multiple data blocks instead of a whole VHD file," but your storage will need to support the required 500-1000 files per backed up GB (and of course you'll need to evaluate whether you wish to use multiple data blocks instead of VHD files in the first place).
I re-ran my backups and the three VMs that failed backup previously have now succeeded.

Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login