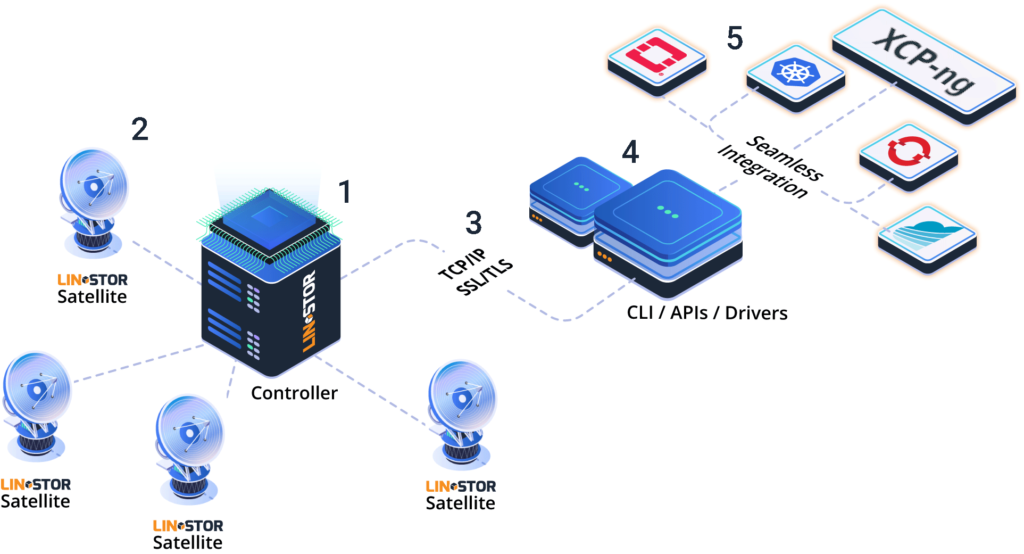
-
@splastunov The DotHill certainly wasn't great for scaling out, because of the age of the firmware and the old-school treatment of the disk arrays.
We did deploy several disk expansion trays that were part populated at purchase as some level of expansion, and operated most of the array as a single underlying pool, which was then split up into iSCSI presented volumes.
So the limitations of the DotHill controllers and firmware we were using didn't address the storage pool scaling issue that CEPH / GPFS / etal are designed to.
However, some of the newer filer heads that treat their entire available disk array as a consolidated pool and support iSCSI would have that scalability, whilst keeping the hypervisor side relatively straight-forward.
CEPH etal are also in a much more mature place than they were back in the early 2010s too, so if I was doing it again, maybe we would go for a solution architecture based around that. Or XOSTOR, of course!
My intent was to present an iSCSI setup instance as something we found relatively bomb-proof, and post-initial configuration, relatively easy to scale. We provisioned 24 port A and B side network switches with jumbo frame support to give us the scalability to add further pools of hypervisors or storage, as required.
-
The typical hypervisor node was provisioned with at least 4 network ports, but most had 8 to allow trunking/resilience for every connection:
Management + live migration (Isolated)
World (Trunk)
iSCSI-A
iSCSI-BThe DotHills were 4 ports per controller, and the two controllers were configured as:
Management
iSCSI-A
iSCSI-B
SpareThe iSCSI-A and iSCSI-B were simple web-managed procurves with 24 ports each.
We had this scaled to 12 hypervisor nodes in 3 pools, all running off the same underlying dothill (dual redundant controller) hardware. We had provisioned some local SSD storage in each hypervisor for any nodes that were struggling for IOPs but ultimately never needed that.
-
OK we have debugged and improved this process, so including it here if it helps anyone else.
How to migrate resources between XOSTOR (linstor) clusters. This also works with piraeus-operator, which we use for k8s.
Manually moving listor resource with thin_send_recv
Migration of data
Commands
# PV: pvc-6408a214-6def-44c4-8d9a-bebb67be5510 # S: pgdata-snapshot # s: 10741612544B #get size lvs --noheadings --units B -o lv_size linstor_group/pvc-6408a214-6def-44c4-8d9a-bebb67be5510_00000 #prep lvcreate -V 10741612544B --thinpool linstor_group/thin_device -n pvc-6408a214-6def-44c4-8d9a-bebb67be5510_00000 linstor_group #create snapshot linstor --controller original-xostor-server s create pvc-6408a214-6def-44c4-8d9a-bebb67be5510 pgdata-snapshot #send thin_send linstor_group/pvc-6408a214-6def-44c4-8d9a-bebb67be5510_00000_pgdata-snapshot 2>/dev/null | ssh root@new-xostor-server-01 thin_recv linstor_group/pvc-6408a214-6def-44c4-8d9a-bebb67be5510_00000 2>/dev/nullWalk-through
Prep migration
[13:29 original-xostor-server ~]# lvs --noheadings --units B -o lv_size linstor_group/pvc-12aca72c-d94a-4c09-8102-0a6646906f8d_00000 26851934208B [13:53 new-xostor-server-01 ~]# lvcreate -V 26851934208B --thinpool linstor_group/thin_device -n pvc-12aca72c-d94a-4c09-8102-0a6646906f8d_00000 linstor_group Logical volume "pvc-12aca72c-d94a-4c09-8102-0a6646906f8d_00000" created.Create snapshot
15:35:03] jonathon@jonathon-framework:~$ linstor --controller original-xostor-server s create pvc-12aca72c-d94a-4c09-8102-0a6646906f8d s_test SUCCESS: Description: New snapshot 's_test' of resource 'pvc-12aca72c-d94a-4c09-8102-0a6646906f8d' registered. Details: Snapshot 's_test' of resource 'pvc-12aca72c-d94a-4c09-8102-0a6646906f8d' UUID is: 3a07d2fd-6dc3-4994-b13f-8c3a2bb206b8 SUCCESS: Suspended IO of '[pvc-12aca72c-d94a-4c09-8102-0a6646906f8d]' on 'ovbh-vprod-k8s04-worker02' for snapshot SUCCESS: Suspended IO of '[pvc-12aca72c-d94a-4c09-8102-0a6646906f8d]' on 'original-xostor-server' for snapshot SUCCESS: Took snapshot of '[pvc-12aca72c-d94a-4c09-8102-0a6646906f8d]' on 'ovbh-vprod-k8s04-worker02' SUCCESS: Took snapshot of '[pvc-12aca72c-d94a-4c09-8102-0a6646906f8d]' on 'original-xostor-server' SUCCESS: Resumed IO of '[pvc-12aca72c-d94a-4c09-8102-0a6646906f8d]' on 'ovbh-vprod-k8s04-worker02' after snapshot SUCCESS: Resumed IO of '[pvc-12aca72c-d94a-4c09-8102-0a6646906f8d]' on 'original-xostor-server' after snapshotMigration
[13:53 original-xostor-server ~]# thin_send /dev/linstor_group/pvc-12aca72c-d94a-4c09-8102-0a6646906f8d_00000_s_test 2>/dev/null | ssh root@new-xostor-server-01 thin_recv linstor_group/pvc-12aca72c-d94a-4c09-8102-0a6646906f8d_00000 2>/dev/nullNeed to yeet errors on both ends of command or it will fail.
This is the same setup process for replica-1 or replica-3. For replica-3 can target new-xostor-server-01 each time, for replica-1 be sure to spread them out right.
Replica-3 Setup
Explanation
thin_sendto new-xostor-server-01, will need to run commands to force sync of data to replicas.Commands
# PV: pvc-96cbebbe-f827-4a47-ae95-38b078e0d584 # snapshot: snipeit-snapshot # size: 21483225088B #get size lvs --noheadings --units B -o lv_size linstor_group/pvc-96cbebbe-f827-4a47-ae95-38b078e0d584_00000 #prep lvcreate -V 21483225088B --thinpool linstor_group/thin_device -n pvc-96cbebbe-f827-4a47-ae95-38b078e0d584_00000 linstor_group #create snapshot linstor --controller original-xostor-server s create pvc-96cbebbe-f827-4a47-ae95-38b078e0d584 snipeit-snapshot linstor --controller original-xostor-server s l | grep -e 'snipeit-snapshot' #send thin_send linstor_group/pvc-96cbebbe-f827-4a47-ae95-38b078e0d584_00000_snipeit-snapshot 2>/dev/null | ssh root@new-xostor-server-01 thin_recv linstor_group/pvc-96cbebbe-f827-4a47-ae95-38b078e0d584_00000 2>/dev/null #linstor setup linstor --controller new-xostor-server-01 resource-definition create pvc-96cbebbe-f827-4a47-ae95-38b078e0d584 --resource-group sc-74e1434b-b435-587e-9dea-fa067deec898 linstor --controller new-xostor-server-01 volume-definition create pvc-96cbebbe-f827-4a47-ae95-38b078e0d584 21483225088B --storage-pool xcp-sr-linstor_group_thin_device linstor --controller new-xostor-server-01 resource create --storage-pool xcp-sr-linstor_group_thin_device --providers LVM_THIN new-xostor-server-01 pvc-96cbebbe-f827-4a47-ae95-38b078e0d584 linstor --controller new-xostor-server-01 resource create --auto-place +1 pvc-96cbebbe-f827-4a47-ae95-38b078e0d584 #Run the following on the node with the data. This is the prefered command drbdadm invalidate-remote pvc-96cbebbe-f827-4a47-ae95-38b078e0d584 #Run the following on the node without the data. This is just for reference drbdadm invalidate pvc-96cbebbe-f827-4a47-ae95-38b078e0d584 linstor --controller new-xostor-server-01 r l | grep -e 'pvc-96cbebbe-f827-4a47-ae95-38b078e0d584'--- apiVersion: v1 kind: PersistentVolume metadata: name: pvc-96cbebbe-f827-4a47-ae95-38b078e0d584 annotations: pv.kubernetes.io/provisioned-by: linstor.csi.linbit.com finalizers: - external-provisioner.volume.kubernetes.io/finalizer - kubernetes.io/pv-protection - external-attacher/linstor-csi-linbit-com spec: accessModes: - ReadWriteOnce capacity: storage: 20Gi # Ensure this matches the actual size of the LINSTOR volume persistentVolumeReclaimPolicy: Retain storageClassName: linstor-replica-three # Adjust to the storage class you want to use volumeMode: Filesystem csi: driver: linstor.csi.linbit.com fsType: ext4 volumeHandle: pvc-96cbebbe-f827-4a47-ae95-38b078e0d584 volumeAttributes: linstor.csi.linbit.com/mount-options: '' linstor.csi.linbit.com/post-mount-xfs-opts: '' linstor.csi.linbit.com/uses-volume-context: 'true' linstor.csi.linbit.com/remote-access-policy: 'true' --- apiVersion: v1 kind: PersistentVolumeClaim metadata: annotations: pv.kubernetes.io/bind-completed: 'yes' pv.kubernetes.io/bound-by-controller: 'yes' volume.beta.kubernetes.io/storage-provisioner: linstor.csi.linbit.com volume.kubernetes.io/storage-provisioner: linstor.csi.linbit.com finalizers: - kubernetes.io/pvc-protection name: pp-snipeit-pvc namespace: snipe-it spec: accessModes: - ReadWriteOnce resources: requests: storage: 20Gi storageClassName: linstor-replica-three volumeMode: Filesystem volumeName: pvc-96cbebbe-f827-4a47-ae95-38b078e0d584Walk-through
jonathon@jonathon-framework:~$ linstor --controller new-xostor-server-01 resource-definition create pvc-96cbebbe-f827-4a47-ae95-38b078e0d584 --resource-group sc-74e1434b-b435-587e-9dea-fa067deec898 SUCCESS: Description: New resource definition 'pvc-96cbebbe-f827-4a47-ae95-38b078e0d584' created. Details: Resource definition 'pvc-96cbebbe-f827-4a47-ae95-38b078e0d584' UUID is: 772692e2-3fca-4069-92e9-2bef22c68a6f jonathon@jonathon-framework:~$ linstor --controller new-xostor-server-01 volume-definition create pvc-96cbebbe-f827-4a47-ae95-38b078e0d584 21483225088B --storage-pool xcp-sr-linstor_group_thin_device SUCCESS: Successfully set property key(s): StorPoolName SUCCESS: New volume definition with number '0' of resource definition 'pvc-96cbebbe-f827-4a47-ae95-38b078e0d584' created. jonathon@jonathon-framework:~$ linstor --controller new-xostor-server-01 resource create --storage-pool xcp-sr-linstor_group_thin_device --providers LVM_THIN new-xostor-server-01 pvc-96cbebbe-f827-4a47-ae95-38b078e0d584 SUCCESS: Successfully set property key(s): StorPoolName INFO: Updated pvc-96cbebbe-f827-4a47-ae95-38b078e0d584 DRBD auto verify algorithm to 'crct10dif-pclmul' SUCCESS: Description: New resource 'pvc-96cbebbe-f827-4a47-ae95-38b078e0d584' on node 'new-xostor-server-01' registered. Details: Resource 'pvc-96cbebbe-f827-4a47-ae95-38b078e0d584' on node 'new-xostor-server-01' UUID is: 3072aaae-4a34-453e-bdc6-facb47809b3d SUCCESS: Description: Volume with number '0' on resource 'pvc-96cbebbe-f827-4a47-ae95-38b078e0d584' on node 'new-xostor-server-01' successfully registered Details: Volume UUID is: 52b11ef6-ec50-42fb-8710-1d3f8c15c657 SUCCESS: Created resource 'pvc-96cbebbe-f827-4a47-ae95-38b078e0d584' on 'new-xostor-server-01' jonathon@jonathon-framework:~$ linstor --controller new-xostor-server-01 resource create --auto-place +1 pvc-96cbebbe-f827-4a47-ae95-38b078e0d584 SUCCESS: Successfully set property key(s): StorPoolName SUCCESS: Successfully set property key(s): StorPoolName SUCCESS: Description: Resource 'pvc-96cbebbe-f827-4a47-ae95-38b078e0d584' successfully autoplaced on 2 nodes Details: Used nodes (storage pool name): 'new-xostor-server-02 (xcp-sr-linstor_group_thin_device)', 'new-xostor-server-03 (xcp-sr-linstor_group_thin_device)' INFO: Resource-definition property 'DrbdOptions/Resource/quorum' updated from 'off' to 'majority' by auto-quorum INFO: Resource-definition property 'DrbdOptions/Resource/on-no-quorum' updated from 'off' to 'suspend-io' by auto-quorum SUCCESS: Added peer(s) 'new-xostor-server-02', 'new-xostor-server-03' to resource 'pvc-96cbebbe-f827-4a47-ae95-38b078e0d584' on 'new-xostor-server-01' SUCCESS: Created resource 'pvc-96cbebbe-f827-4a47-ae95-38b078e0d584' on 'new-xostor-server-02' SUCCESS: Created resource 'pvc-96cbebbe-f827-4a47-ae95-38b078e0d584' on 'new-xostor-server-03' SUCCESS: Description: Resource 'pvc-96cbebbe-f827-4a47-ae95-38b078e0d584' on 'new-xostor-server-03' ready Details: Auto-placing resource: pvc-96cbebbe-f827-4a47-ae95-38b078e0d584 SUCCESS: Description: Resource 'pvc-96cbebbe-f827-4a47-ae95-38b078e0d584' on 'new-xostor-server-02' ready Details: Auto-placing resource: pvc-96cbebbe-f827-4a47-ae95-38b078e0d584At this point
jonathon@jonathon-framework:~$ linstor --controller new-xostor-server-01 v l | grep -e 'pvc-96cbebbe-f827-4a47-ae95-38b078e0d584' | new-xostor-server-01 | pvc-96cbebbe-f827-4a47-ae95-38b078e0d584 | xcp-sr-linstor_group_thin_device | 0 | 1032 | /dev/drbd1032 | 9.20 GiB | Unused | UpToDate | | new-xostor-server-02 | pvc-96cbebbe-f827-4a47-ae95-38b078e0d584 | xcp-sr-linstor_group_thin_device | 0 | 1032 | /dev/drbd1032 | 112.73 MiB | Unused | UpToDate | | new-xostor-server-03 | pvc-96cbebbe-f827-4a47-ae95-38b078e0d584 | xcp-sr-linstor_group_thin_device | 0 | 1032 | /dev/drbd1032 | 112.73 MiB | Unused | UpToDate |To force the sync, run the following command on the node with the data
drbdadm invalidate-remote pvc-96cbebbe-f827-4a47-ae95-38b078e0d584This will kick it to get the data re-synced.
[14:51 new-xostor-server-01 ~]# drbdadm invalidate-remote pvc-96cbebbe-f827-4a47-ae95-38b078e0d584 [14:51 new-xostor-server-01 ~]# drbdadm status pvc-96cbebbe-f827-4a47-ae95-38b078e0d584 pvc-96cbebbe-f827-4a47-ae95-38b078e0d584 role:Secondary disk:UpToDate new-xostor-server-02 role:Secondary replication:SyncSource peer-disk:Inconsistent done:1.14 new-xostor-server-03 role:Secondary replication:SyncSource peer-disk:Inconsistent done:1.18 [14:51 new-xostor-server-01 ~]# drbdadm status pvc-96cbebbe-f827-4a47-ae95-38b078e0d584 pvc-96cbebbe-f827-4a47-ae95-38b078e0d584 role:Secondary disk:UpToDate new-xostor-server-02 role:Secondary peer-disk:UpToDate new-xostor-server-03 role:Secondary peer-disk:UpToDateSee: https://github.com/LINBIT/linstor-server/issues/389
Replica-1setup
# PV: pvc-6408a214-6def-44c4-8d9a-bebb67be5510 # S: pgdata-snapshot # s: 10741612544B #get size lvs --noheadings --units B -o lv_size linstor_group/pvc-6408a214-6def-44c4-8d9a-bebb67be5510_00000 #prep lvcreate -V 10741612544B --thinpool linstor_group/thin_device -n pvc-6408a214-6def-44c4-8d9a-bebb67be5510_00000 linstor_group #create snapshot linstor --controller original-xostor-server s create pvc-6408a214-6def-44c4-8d9a-bebb67be5510 pgdata-snapshot #send thin_send linstor_group/pvc-6408a214-6def-44c4-8d9a-bebb67be5510_00000_pgdata-snapshot 2>/dev/null | ssh root@new-xostor-server-01 thin_recv linstor_group/pvc-6408a214-6def-44c4-8d9a-bebb67be5510_00000 2>/dev/null # 1 linstor --controller new-xostor-server-01 resource-definition create pvc-6408a214-6def-44c4-8d9a-bebb67be5510 --resource-group sc-b066e430-6206-5588-a490-cc91ecef53d6 linstor --controller new-xostor-server-01 volume-definition create pvc-6408a214-6def-44c4-8d9a-bebb67be5510 10741612544B --storage-pool xcp-sr-linstor_group_thin_device linstor --controller new-xostor-server-01 resource create new-xostor-server-01 pvc-6408a214-6def-44c4-8d9a-bebb67be5510--- apiVersion: v1 kind: PersistentVolume metadata: name: pvc-6408a214-6def-44c4-8d9a-bebb67be5510 annotations: pv.kubernetes.io/provisioned-by: linstor.csi.linbit.com finalizers: - external-provisioner.volume.kubernetes.io/finalizer - kubernetes.io/pv-protection - external-attacher/linstor-csi-linbit-com spec: accessModes: - ReadWriteOnce capacity: storage: 10Gi # Ensure this matches the actual size of the LINSTOR volume persistentVolumeReclaimPolicy: Retain storageClassName: linstor-replica-one-local # Adjust to the storage class you want to use volumeMode: Filesystem csi: driver: linstor.csi.linbit.com fsType: ext4 volumeHandle: pvc-6408a214-6def-44c4-8d9a-bebb67be5510 volumeAttributes: linstor.csi.linbit.com/mount-options: '' linstor.csi.linbit.com/post-mount-xfs-opts: '' linstor.csi.linbit.com/uses-volume-context: 'true' linstor.csi.linbit.com/remote-access-policy: | - fromSame: - xcp-ng/node nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: xcp-ng/node operator: In values: - new-xostor-server-01 --- apiVersion: v1 kind: PersistentVolumeClaim metadata: annotations: pv.kubernetes.io/bind-completed: 'yes' pv.kubernetes.io/bound-by-controller: 'yes' volume.beta.kubernetes.io/storage-provisioner: linstor.csi.linbit.com volume.kubernetes.io/selected-node: ovbh-vtest-k8s01-worker01 volume.kubernetes.io/storage-provisioner: linstor.csi.linbit.com finalizers: - kubernetes.io/pvc-protection name: acid-merch-2 namespace: default spec: accessModes: - ReadWriteOnce resources: requests: storage: 10Gi storageClassName: linstor-replica-one-local volumeMode: Filesystem volumeName: pvc-6408a214-6def-44c4-8d9a-bebb67be5510 -
Last week I stood up two XCP-ng hosts with LINSTOR without issue.
This week I am standing up a third XCP-ng host and encounter a show stopping error when I try to install LINSTOR:
Error: Package: xcp-ng-linstor-1.1-3.xcpng8.2.noarch (xcp-ng-linstor)
Requires: sm-linstor
...
Failed to install LINSTOR package: xcp-ng-linstor.This third host is 100% identical in hardware to the first two hosts. Fresh from-scratch new install of XCP-ng. Here is an output of commands and their results on the third host:
[21:35 bol-xcp3 ~]# wget https://gist.githubusercontent.com/Wescoeur/7bb568c0e09e796710b0ea966882fcac/raw/052b3dfff9c06b1765e51d8de72c90f2f90f475b/gistfile1.txt -O install && chmod +x install --2024-11-16 21:35:08-- https://gist.githubusercontent.com/Wescoeur/7bb568c0e09e796710b0ea966882fcac/raw/052b3dfff9c06b1765e51d8de72c90f2f90f475b/gistfile1.txt Resolving gist.githubusercontent.com (gist.githubusercontent.com)... 185.199.111.133, 185.199.110.133, 185.199.109.133, ... Connecting to gist.githubusercontent.com (gist.githubusercontent.com)|185.199.111.133|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 3596 (3.5K) [text/plain] Saving to: ‘install’ 100%[=============================================================================>] 3,596 --.-K/s in 0s 2024-11-16 21:35:08 (22.4 MB/s) - ‘install’ saved [3596/3596] [21:35 bol-xcp3 ~]# ./install --disks /dev/nvme0n1 --thin Loaded plugins: fastestmirror Loading mirror speeds from cached hostfile Excluding mirror: updates.xcp-ng.org * xcp-ng-base: mirrors.xcp-ng.org Excluding mirror: updates.xcp-ng.org * xcp-ng-updates: mirrors.xcp-ng.org Resolving Dependencies --> Running transaction check ---> Package xcp-ng-release-linstor.noarch 0:1.3-1.xcpng8.2 will be installed --> Finished Dependency Resolution Dependencies Resolved ======================================================================================================================= Package Arch Version Repository Size ======================================================================================================================= Installing: xcp-ng-release-linstor noarch 1.3-1.xcpng8.2 xcp-ng-updates 4.0 k Transaction Summary ======================================================================================================================= Install 1 Package Total download size: 4.0 k Installed size: 477 Downloading packages: xcp-ng-release-linstor-1.3-1.xcpng8.2.noarch.rpm | 4.0 kB 00:00:01 Running transaction check Running transaction test Transaction test succeeded Running transaction Installing : xcp-ng-release-linstor-1.3-1.xcpng8.2.noarch 1/1 Verifying : xcp-ng-release-linstor-1.3-1.xcpng8.2.noarch 1/1 Installed: xcp-ng-release-linstor.noarch 0:1.3-1.xcpng8.2 Complete! Loaded plugins: fastestmirror Loading mirror speeds from cached hostfile Excluding mirror: updates.xcp-ng.org * xcp-ng-base: mirrors.xcp-ng.org Excluding mirror: updates.xcp-ng.org * xcp-ng-updates: mirrors.xcp-ng.org Resolving Dependencies --> Running transaction check ---> Package xcp-ng-linstor.noarch 0:1.1-3.xcpng8.2 will be installed --> Processing Dependency: sm-linstor for package: xcp-ng-linstor-1.1-3.xcpng8.2.noarch --> Finished Dependency Resolution Error: Package: xcp-ng-linstor-1.1-3.xcpng8.2.noarch (xcp-ng-linstor) Requires: sm-linstor Available: sm-2.30.8-2.1.0.linstor.4.xcpng8.2.x86_64 (xcp-ng-linstor) sm-linstor Available: sm-2.30.8-2.1.0.linstor.5.xcpng8.2.x86_64 (xcp-ng-linstor) sm-linstor Available: sm-2.30.8-2.1.0.linstor.6.xcpng8.2.x86_64 (xcp-ng-linstor) sm-linstor Available: sm-2.30.8-2.3.0.linstor.1.xcpng8.2.x86_64 (xcp-ng-linstor) sm-linstor Available: sm-2.30.8-2.3.0.linstor.2.xcpng8.2.x86_64 (xcp-ng-linstor) sm-linstor Available: sm-2.30.8-7.1.0.linstor.2.xcpng8.2.x86_64 (xcp-ng-linstor) sm-linstor Available: sm-2.30.8-10.1.0.linstor.1.xcpng8.2.x86_64 (xcp-ng-linstor) sm-linstor Available: sm-2.30.8-10.1.0.linstor.2.xcpng8.2.x86_64 (xcp-ng-linstor) sm-linstor Available: sm-2.30.8-10.1.0.linstor.3.xcpng8.2.x86_64 (xcp-ng-linstor) sm-linstor Available: sm-2.30.8-12.1.0.linstor.2.xcpng8.2.x86_64 (xcp-ng-linstor) sm-linstor Available: sm-2.30.8-12.1.0.linstor.3.xcpng8.2.x86_64 (xcp-ng-linstor) sm-linstor Available: sm-2.30.8-12.1.0.linstor.4.xcpng8.2.x86_64 (xcp-ng-linstor) sm-linstor Installed: sm-2.30.8-13.1.xcpng8.2.x86_64 (@xcp-ng-updates) Not found Available: sm-2.29.1-1.2.xcpng8.2.x86_64 (xcp-ng-base) Not found Available: sm-2.30.4-1.1.xcpng8.2.x86_64 (xcp-ng-updates) Not found Available: sm-2.30.4-1.1.0.linstor.8.xcpng8.2.x86_64 (xcp-ng-linstor) Not found Available: sm-2.30.6-1.1.xcpng8.2.x86_64 (xcp-ng-updates) Not found Available: sm-2.30.6-1.1.0.linstor.1.xcpng8.2.x86_64 (xcp-ng-linstor) Not found Available: sm-2.30.6-1.2.0.linstor.1.xcpng8.2.x86_64 (xcp-ng-linstor) Not found Available: sm-2.30.7-1.1.0.linstor.1.xcpng8.2.x86_64 (xcp-ng-linstor) Not found Available: sm-2.30.7-1.2.0.linstor.1.xcpng8.2.x86_64 (xcp-ng-linstor) Not found Available: sm-2.30.7-1.3.xcpng8.2.x86_64 (xcp-ng-updates) Not found Available: sm-2.30.7-1.3.0.linstor.1.xcpng8.2.x86_64 (xcp-ng-linstor) Not found Available: sm-2.30.7-1.3.0.linstor.2.xcpng8.2.x86_64 (xcp-ng-linstor) Not found Available: sm-2.30.7-1.3.0.linstor.3.xcpng8.2.x86_64 (xcp-ng-linstor) Not found Available: sm-2.30.7-1.3.0.linstor.7.xcpng8.2.x86_64 (xcp-ng-linstor) Not found Available: sm-2.30.7-1.3.0.linstor.8.xcpng8.2.x86_64 (xcp-ng-linstor) Not found Available: sm-2.30.8-2.1.xcpng8.2.x86_64 (xcp-ng-updates) Not found Available: sm-2.30.8-2.1.0.linstor.1.xcpng8.2.x86_64 (xcp-ng-linstor) Not found Available: sm-2.30.8-2.1.0.linstor.2.xcpng8.2.x86_64 (xcp-ng-linstor) Not found Available: sm-2.30.8-2.1.0.linstor.3.xcpng8.2.x86_64 (xcp-ng-linstor) Not found Available: sm-2.30.8-2.3.xcpng8.2.x86_64 (xcp-ng-updates) Not found Available: sm-2.30.8-7.1.xcpng8.2.x86_64 (xcp-ng-updates) Not found Available: sm-2.30.8-10.1.xcpng8.2.x86_64 (xcp-ng-updates) Not found Available: sm-2.30.8-12.1.xcpng8.2.x86_64 (xcp-ng-updates) Not found You could try using --skip-broken to work around the problem You could try running: rpm -Va --nofiles --nodigest Failed to install LINSTOR package: xcp-ng-linstor.It seems the sm* package(s) are missing ? I don't know what to do.
Edit 2024-11-17 1702 CST:
yum install xcp-ng-release-linstorindicatesxcp-ng-release-linstoris already installed and latest version.[16:14 bol-xcp3 ~]# yum install xcp-ng-release-linstor Loaded plugins: fastestmirror Loading mirror speeds from cached hostfile Excluding mirror: updates.xcp-ng.org * xcp-ng-base: mirrors.xcp-ng.org Excluding mirror: updates.xcp-ng.org * xcp-ng-updates: mirrors.xcp-ng.org Package xcp-ng-release-linstor-1.3-1.xcpng8.2.noarch already installed and latest version Nothing to do -
@BlueToast This should be fixed now. Please retry the XOSTOR installation.
-
@Danp Success this this - thanks for the assist.
") Executed with great success:
Executed with great success:yum install xcp-ng-linstor yum install xcp-ng-release-linstor ./install --disks /dev/nvme0n1 --thin -
Since XOSTOR is now supported on XCP-ng 8.3 LTS, should we use the same script or some other method is required ?
Can you remove the heading which states the script is only compatible with 8.2 ? -
Ping @Team-Storage
-
Is CBT meant to be supported on XOSTOR?
I've been experimenting with XOSTOR recently, but upon testing a delta-backup, noticed this warning...

The error message behind this is
SR_OPERATION_NOT_SUPPORTEDwhen callingAsync.VDI.enable_cbt.Running
xe sr-param-list uuid={uuid}shows the following:[~]# xe sr-param-list uuid={...} uuid ( RO) : {...} name-label ( RW): CD6 name-description ( RW): Array of Kioxia CD6 U.2 drives, one in each Host. host ( RO): <shared> allowed-operations (SRO): unplug; plug; PBD.create; update; PBD.destroy; VDI.resize; VDI.clone; scan; VDI.snapshot; VDI.mirror; VDI.create; VDI.destroy {...etc} type ( RO): linstor content-type ( RO): user shared ( RW): true introduced-by ( RO): <not in database> is-tools-sr ( RO): false other-config (MRW): auto-scan: true sm-config (MRO): {...etc}Compared to another SR, the following allowed-operations are missing:
VDI.enable_cbt; VDI.list_changed_blocks; VDI.disable_cbt; VDI.data_destroy; VDI.set_on_bootIs this the expected behaviour? Note that this is using XCP-ng 8.2 (I've yet to test out 8.3).
-
-
@peter_webbird We've already had feedback on CBT and LINSTOR/DRBD, we don't necessarily recommend enabling it. We have a blocking dev card regarding a bug with LVM lvchange command that may fail on CBT volumes used by a XOSTOR SR. We also have other issues related to migration with CBT.
-
@ronan-a @dthenot @Team-Storage
Guys, Can you please clarify which method to use for installing XOSTOR in XCP-ng 8.3 ?
Simple :
yum install xcp-ng-linstor yum install xcp-ng-release-linstor ./install --disks /dev/nvme0n1 --thinOr the script in the first post ?
Or Some other script ? -
@gb.123 Hello,
The instruction in the first post are still the way to go -
@dthenot said in XOSTOR hyperconvergence preview:
@gb.123 Hello,
The instruction in the first post are still the way to goI'm curious about that as well but the first post says that the installation script is only compatible with 8.2 and doesn't mention 8.3. Is that still the case or is the installation script now compatible with 8.3 as well? If not, is there an installation script that is compatible with 8.3?
I know that using XO is the recommended method for installation but I'm interested in an installation script as I would like to try to integrate XOSTOR installation into an XCP-ng installation script I already have which runs via PXE boot.
-
@JeffBerntsen That's why I meant, the way to install written in the first post still work in 8.3, the script still work as expected also, it basically only create the VG/LV needed on hosts before you create the SR.
-
@dthenot said in XOSTOR hyperconvergence preview:
@JeffBerntsen That's why I meant, the way to install written in the first post still work in 8.3, the script still work as expected also, it basically only create the VG/LV needed on hosts before you create the SR.
Got it. Thanks!
-
Hello,
I plan to install my XOSTOR cluster on a pool of 7 nodes with 3 replicas, but not all nodes at once because disks are in use.
consider:- node1
- node2
- node ...
- node 5
- node 6
- node 7.
with 2 disks on each
- sda: 128GB for the OS
- sdb: 1TB for local sr ( for now
 )
)
I emptied node 6 & 7.
so, here is what i plan to do:
- On ALL NODES: setup linstor packages
Run the install script on node 6 & 7 to add their disks
so:node6# install.sh --disks /dev/sdb node7# install.sh --disks /dev/sdbThen, configure the SR and the linstor plugin manager as the following
xe sr-create \ type=linstor name-label=pool-01 \ host-uuid=XXXX \ device-config:group-name=linstor_group/thin_device device-config:redundancy=3 shared=true device-config:provisioning=thinNormally, i should have a linstor cluster running of 2 nodes ( 2 satellite and one controller randomly placed ) with only 2 disks and then, only 2/3 working replicas.
The cluster SHOULD be usable ( i'm right on this point ? )
The next step, would be to move VM from node 5 on it to evacuate node 5. and then add it to the cluster by the following
node5# install.sh --disks /dev/sdb node5# xe host-call-plugin \ host-uuid=node5-uuid \ plugin=linstor-manager \ fn=addHost args:groupName=linstor_group/thin_deviceThat should deploy satelite on node 5 and add the disk.
I normally should have 3/3 working replicas and can start to deploy others nodes progressively.
I'm right on the process ?
aS mentionned in the discord, i will post my feedbacks and results from my setup once i finalized it. ( maybe thought a blog post somewhere ).
Thanks to provide xostor in opensource, it's clearly the missing piece for this virtualization stack in opensource ( vs proxmox )
-
 H henri9813 referenced this topic on
H henri9813 referenced this topic on
-
I have amazing news!
After the upgrade to xcp-ng 8.3, I retested velero backup, and it all just works

Completed Backup
jonathon@jonathon-framework:~$ velero --kubeconfig k8s_configs/production.yaml backup describe grafana-test Name: grafana-test Namespace: velero Labels: objectset.rio.cattle.io/hash=c2b5f500ab5d9b8ffe14f2c70bf3742291df565c velero.io/storage-location=default Annotations: objectset.rio.cattle.io/applied=H4sIAAAAAAAA/4SSQW/bPgzFvwvPtv9OajeJj/8N22HdBqxFL0MPlEQlWmTRkOhgQ5HvPsixE2yH7iji8ffIJ74CDu6ZYnIcoIMTeYpcOf7vtIICji4Y6OB/1MdxgAJ6EjQoCN0rYAgsKI5Dyk9WP0hLIqmi40qjiKfMcRlAq7pBY+py26qmbEi15a5p78vtaqe0oqbVVsO5AI+K/Ju4A6YDdKDXqrVtXaNqzU5traVVY9d6Uyt7t2nW693K2Pa+naABe4IO9hEtBiyFksClmgbUdN06a9NAOtvr5B4DDunA8uR64lGgg7u6rxMUYMji6OWZ/dhTeuIPaQ6os+gTFUA/tR8NmXd+TELxUfNA5hslHqOmBN13OF16ZwvNQShIqpZClYQj7qk6blPlGF5uzC/L3P+kvok7MB9z0OcCXPiLPLHmuLLWCfVfB4rTZ9/iaA5zHovNZz7R++k6JI50q89BXcuXYR5YT0DolkChABEPHWzW9cK+rPQx8jgsH/KQj+QT/frzXCdduc/Ca9u1Y7aaFvMu5Ang5Xz+HQAA//8X7Fu+/QIAAA objectset.rio.cattle.io/id=e104add0-85b4-4eb5-9456-819bcbe45cfc velero.io/resource-timeout=10m0s velero.io/source-cluster-k8s-gitversion=v1.33.4+rke2r1 velero.io/source-cluster-k8s-major-version=1 velero.io/source-cluster-k8s-minor-version=33 Phase: Completed Namespaces: Included: grafana Excluded: <none> Resources: Included cluster-scoped: <none> Excluded cluster-scoped: volumesnapshotcontents.snapshot.storage.k8s.io Included namespace-scoped: * Excluded namespace-scoped: volumesnapshots.snapshot.storage.k8s.io Label selector: <none> Or label selector: <none> Storage Location: default Velero-Native Snapshot PVs: true Snapshot Move Data: true Data Mover: velero TTL: 720h0m0s CSISnapshotTimeout: 30m0s ItemOperationTimeout: 4h0m0s Hooks: <none> Backup Format Version: 1.1.0 Started: 2025-10-15 15:29:52 -0700 PDT Completed: 2025-10-15 15:31:25 -0700 PDT Expiration: 2025-11-14 14:29:52 -0800 PST Total items to be backed up: 35 Items backed up: 35 Backup Item Operations: 1 of 1 completed successfully, 0 failed (specify --details for more information) Backup Volumes: Velero-Native Snapshots: <none included> CSI Snapshots: grafana/central-grafana: Data Movement: included, specify --details for more information Pod Volume Backups: <none included> HooksAttempted: 0 HooksFailed: 0Completed Restore
jonathon@jonathon-framework:~$ velero --kubeconfig k8s_configs/production.yaml restore describe restore-grafana-test --details Name: restore-grafana-test Namespace: velero Labels: objectset.rio.cattle.io/hash=252addb3ed156c52d9fa9b8c045b47a55d66c0af Annotations: objectset.rio.cattle.io/applied=H4sIAAAAAAAA/3yRTW7zIBBA7zJrO5/j35gzfE2rtsomymIM45jGBgTjbKLcvaKJm6qL7kDwnt7ABdDpHfmgrQEBZxrJ25W2/85rSOCkjQIBrxTYeoIEJmJUyAjiAmiMZWRtTYhb232Q5EC88tquJDKPFEU6GlpUG5UVZdpUdZ6WZZ+niOtNWtR1SypvqC8buCYwYkfjn7oBwwAC8ipHpbqC1LqqZZWrtse228isrLqywapSdS0z7KPU4EQgwN+mSI8eezSYMgWG22lwKOl7/MgERzJmdChPs9veDL9IGfSbQRcGy+96IjszCCiyCRLQRo6zIrVd5AHEfuHhkIBmmp4d+a/3e9Dl8LPoCZ3T5hg7FvQRcR8nxt6XL7sAgv1MCZztOE+01P23cvmnPYzaxNtwuF4/AwAA//8k6OwC/QEAAA objectset.rio.cattle.io/id=9ad8d034-7562-44f2-aa18-3669ed27ef47 Phase: Completed Total items to be restored: 33 Items restored: 33 Started: 2025-10-15 15:35:26 -0700 PDT Completed: 2025-10-15 15:36:34 -0700 PDT Warnings: Velero: <none> Cluster: <none> Namespaces: grafana-restore: could not restore, ConfigMap:elasticsearch-es-transport-ca-internal already exists. Warning: the in-cluster version is different than the backed-up version could not restore, ConfigMap:kube-root-ca.crt already exists. Warning: the in-cluster version is different than the backed-up version Backup: grafana-test Namespaces: Included: grafana Excluded: <none> Resources: Included: * Excluded: nodes, events, events.events.k8s.io, backups.velero.io, restores.velero.io, resticrepositories.velero.io, csinodes.storage.k8s.io, volumeattachments.storage.k8s.io, backuprepositories.velero.io Cluster-scoped: auto Namespace mappings: grafana=grafana-restore Label selector: <none> Or label selector: <none> Restore PVs: true CSI Snapshot Restores: grafana-restore/central-grafana: Data Movement: Operation ID: dd-ffa56e1c-9fd0-44b4-a8bb-8163f40a49e9.330b82fc-ca6a-423217ee5 Data Mover: velero Uploader Type: kopia Existing Resource Policy: <none> ItemOperationTimeout: 4h0m0s Preserve Service NodePorts: auto Restore Item Operations: Operation for persistentvolumeclaims grafana-restore/central-grafana: Restore Item Action Plugin: velero.io/csi-pvc-restorer Operation ID: dd-ffa56e1c-9fd0-44b4-a8bb-8163f40a49e9.330b82fc-ca6a-423217ee5 Phase: Completed Progress: 856284762 of 856284762 complete (Bytes) Progress description: Completed Created: 2025-10-15 15:35:28 -0700 PDT Started: 2025-10-15 15:36:06 -0700 PDT Updated: 2025-10-15 15:36:26 -0700 PDT HooksAttempted: 0 HooksFailed: 0 Resource List: apps/v1/Deployment: - grafana-restore/central-grafana(created) - grafana-restore/grafana-debug(created) apps/v1/ReplicaSet: - grafana-restore/central-grafana-5448b9f65(created) - grafana-restore/central-grafana-56887c6cb6(created) - grafana-restore/central-grafana-56ddd4f497(created) - grafana-restore/central-grafana-5f4757844b(created) - grafana-restore/central-grafana-5f69f86c85(created) - grafana-restore/central-grafana-64545dcdc(created) - grafana-restore/central-grafana-69c66c54d9(created) - grafana-restore/central-grafana-6c8d6f65b8(created) - grafana-restore/central-grafana-7b479f79ff(created) - grafana-restore/central-grafana-bc7d96cdd(created) - grafana-restore/central-grafana-cb88bd49c(created) - grafana-restore/grafana-debug-556845ff7b(created) - grafana-restore/grafana-debug-6fb594cb5f(created) - grafana-restore/grafana-debug-8f66bfbf6(created) discovery.k8s.io/v1/EndpointSlice: - grafana-restore/central-grafana-hkgd5(created) networking.k8s.io/v1/Ingress: - grafana-restore/central-grafana(created) rbac.authorization.k8s.io/v1/Role: - grafana-restore/central-grafana(created) rbac.authorization.k8s.io/v1/RoleBinding: - grafana-restore/central-grafana(created) v1/ConfigMap: - grafana-restore/central-grafana(created) - grafana-restore/elasticsearch-es-transport-ca-internal(failed) - grafana-restore/kube-root-ca.crt(failed) v1/Endpoints: - grafana-restore/central-grafana(created) v1/PersistentVolume: - pvc-e3f6578f-08b2-4e79-85f0-76bbf8985b55(skipped) v1/PersistentVolumeClaim: - grafana-restore/central-grafana(created) v1/Pod: - grafana-restore/central-grafana-cb88bd49c-fc5br(created) v1/Secret: - grafana-restore/fpinfra-net-cf-cert(created) - grafana-restore/grafana(created) v1/Service: - grafana-restore/central-grafana(created) v1/ServiceAccount: - grafana-restore/central-grafana(created) - grafana-restore/default(skipped) velero.io/v2alpha1/DataUpload: - velero/grafana-test-nw7zj(skipped)Image of working restore pod, with correct data in PV
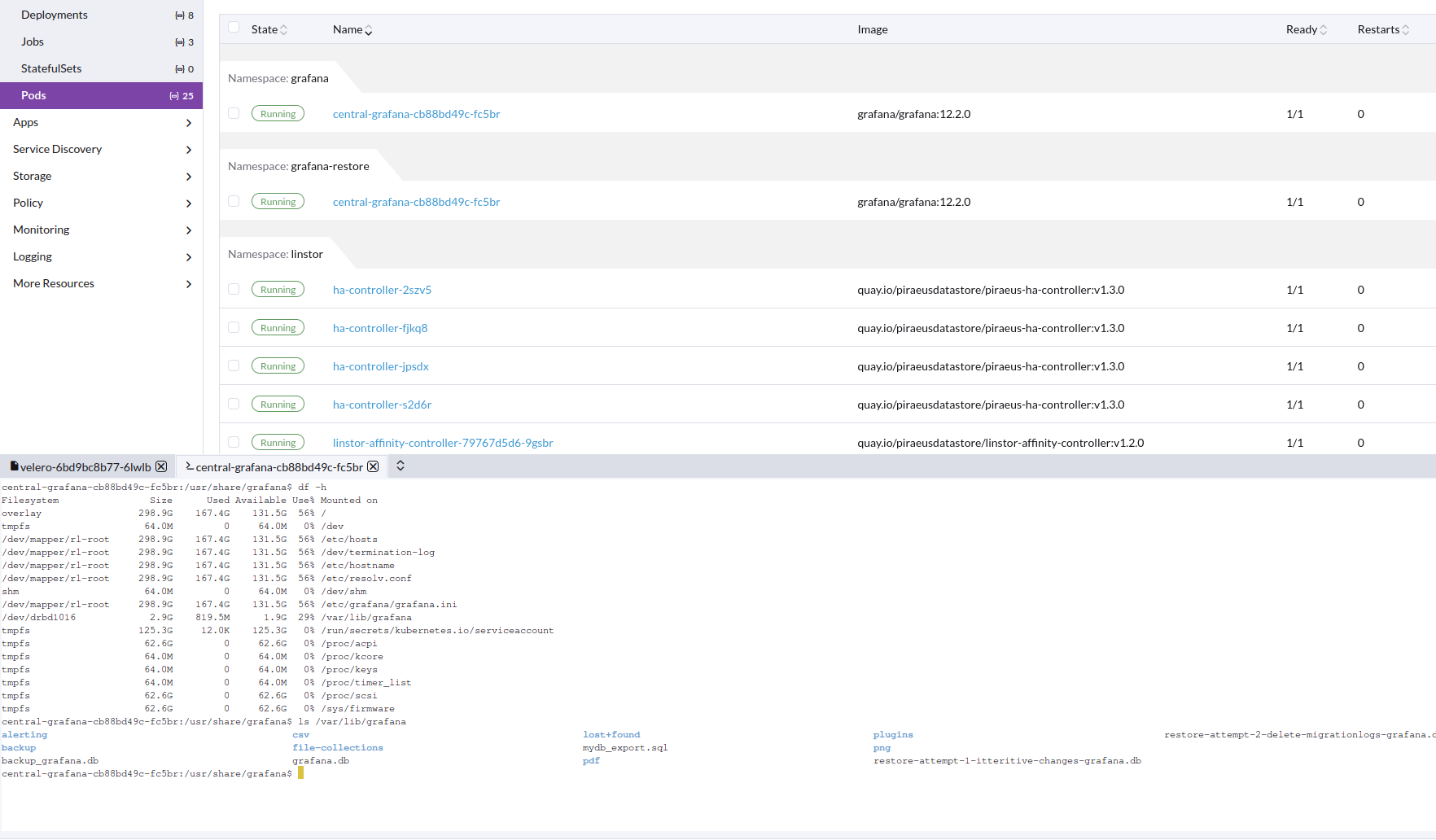
Velero installed from helm: https://vmware-tanzu.github.io/helm-charts
Version: velero:11.1.0
Values--- image: repository: velero/velero tag: v1.17.0 # Whether to deploy the restic daemonset. deployNodeAgent: true initContainers: - name: velero-plugin-for-aws image: velero/velero-plugin-for-aws:latest imagePullPolicy: IfNotPresent volumeMounts: - mountPath: /target name: plugins configuration: defaultItemOperationTimeout: 2h features: EnableCSI defaultSnapshotMoveData: true backupStorageLocation: - name: default provider: aws bucket: velero config: region: us-east-1 s3ForcePathStyle: true s3Url: https://s3.location # Destination VSL points to LINSTOR snapshot class volumeSnapshotLocation: - name: linstor provider: velero.io/csi config: snapshotClass: linstor-vsc credentials: useSecret: true existingSecret: velero-user metrics: enabled: true serviceMonitor: enabled: true prometheusRule: enabled: true # Additional labels to add to deployed PrometheusRule additionalLabels: {} # PrometheusRule namespace. Defaults to Velero namespace. # namespace: "" # Rules to be deployed spec: - alert: VeleroBackupPartialFailures annotations: message: Velero backup {{ $labels.schedule }} has {{ $value | humanizePercentage }} partialy failed backups. expr: |- velero_backup_partial_failure_total{schedule!=""} / velero_backup_attempt_total{schedule!=""} > 0.25 for: 15m labels: severity: warning - alert: VeleroBackupFailures annotations: message: Velero backup {{ $labels.schedule }} has {{ $value | humanizePercentage }} failed backups. expr: |- velero_backup_failure_total{schedule!=""} / velero_backup_attempt_total{schedule!=""} > 0.25 for: 15m labels: severity: warningAlso create the following.
apiVersion: snapshot.storage.k8s.io/v1 kind: VolumeSnapshotClass metadata: name: linstor-vsc labels: velero.io/csi-volumesnapshot-class: "true" driver: linstor.csi.linbit.com deletionPolicy: DeleteWe are using Piraeus operator to use xostor in k8s
https://github.com/piraeusdatastore/piraeus-operator.git
Version: v2.9.1
Values:--- operator: resources: requests: cpu: 250m memory: 500Mi limits: memory: 1Gi installCRDs: true imageConfigOverride: - base: quay.io/piraeusdatastore components: linstor-satellite: image: piraeus-server tag: v1.29.0 tls: certManagerIssuerRef: name: step-issuer kind: StepClusterIssuer group: certmanager.step.smThen we just connect to the xostor cluster like external linstor controller.
-
Hello,
I got my whole xostor destroyed, i don't know how precisely.
I found some errors in sattelite
Error context: An error occurred while processing resource 'Node: 'host', Rsc: 'xcp-volume-e011c043-8751-45e6-be06-4ce9f8807cad'' ErrorContext: Details: Command 'lvcreate --config 'devices { filter=['"'"'a|/dev/md127|'"'"','"'"'a|/dev/md126p3|'"'"','"'"'r|.*|'"'"'] }' --virtualsize 52543488k linstor_primary --thinpool thin_device --name xcp-volume-e011c043-8751-45e6-be06-4ce9f8807cad_00000' returned with exitcode 5. Standard out: Error message: WARNING: Remaining free space in metadata of thin pool linstor_primary/thin_device is too low (98.06% >= 96.30%). Resize is recommended. Cannot create new thin volume, free space in thin pool linstor_primary/thin_device reached threshold.of course, i checked, my SR was not full
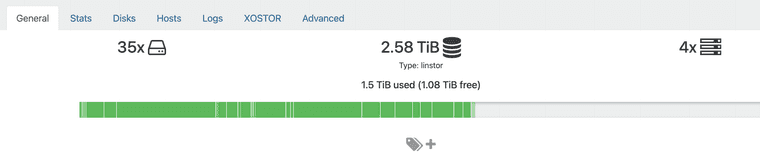
And the controller crashed, and i couldn't make it works.
Here is the error i got
========== Category: RuntimeException Class name: IllegalStateException Class canonical name: java.lang.IllegalStateException Generated at: Method 'newIllegalStateException', Source file 'DataUtils.java', Line #870 Error message: Reading from nio:/var/lib/linstor/linstordb.mv.db failed; file length 2293760 read length 384 at 2445540 [1.4.197/1]So i deduce the database was fucked-up, i tried to open the file as explained in the documentation, but the linstor schema was "not found" in the file, event if using
cati see data about it.for now, i leave xostor and i'm back to localstorage until we know what to do when this issue occured with a "solution path".
-
@henri9813 said in XOSTOR hyperconvergence preview:
of course, i checked, my SR was not full
The visual representation of used space is for informational purposes only; it's an approximation that takes into account replication, disks in use, etc. For more information: https://docs.xcp-ng.org/xostor/#how-a-linstor-sr-capacity-is-calculated
We plan to display a complete view of each physical disk space on each host someday to provide a more detailed overview. In any case, if you use "lvs"/"vgs" on each machine, you should indeed see the actual disk space used.

Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login