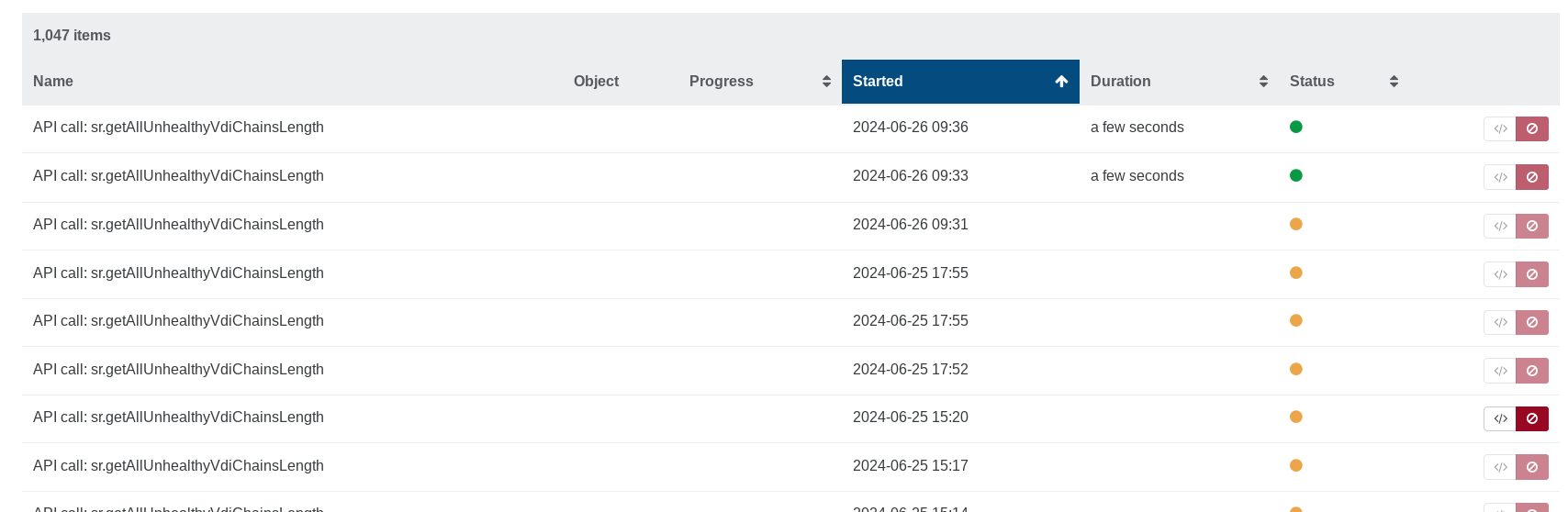
huge number of api call "sr.getAllUnhealthyVdiChainsLength" in tasks
-
@flakpyro said in huge number of api call "sr.getAllUnhealthyVdiChainsLength" in tasks:
removing all .cbtlog files from my SR got backups back up and running
What did you do exctly to remove the .cbtlog files? Where are they located?
I find that after backups with the "broken" versions (also the latest with the 2 fixes) I get my coalescing stopped. And checking the logs (cat /var/log/SMlog | grep -i coalesce) I have entries like
['/usr/sbin/cbt-util', 'coalesce', '-p', '/var/run/sr-mount/ea3c92b7-0e82-5726-502b-482b40a8b097/0cc54304-4961-482f-a1b7-a8222dd143a1.cbtlog', '-c', '/var/run/sr-mount/ea3c92b7-0e82-5726-502b-482b40a8b097/fe11c7f1-7331-427e-8fa9-76412a2cbb75.cbtlogAnd those correspond to the hanged coalesces...
When I reboot the host they disappear but on next delta backup I have the issue again.
-
@manilx the .cbt logs are located on your SR (/run/sr-mount/UUID) i don't totally know if removing them is what fixed things for me but once backups started failing my goal was to "revert" everything back to a known good working state. Doing this, reverting XOA and restarting the tool stack on the host got things back to how they were.
I'm very much looking forward to CBT backups though as i've been spoiled by Veeam / ESX CBT backups for a lot of years!
-
@olivierlambert I'm not sure that I am doing it correctly. XOA is up to date (Master, commit 6ee7a) and I went through and re scanned the storage repositories to get snapshots to coalesce. Backups work properly now.
I have 50 or so instances of the following in XO tasks
- API call: sr.getAllUnhealthyVdiChainsLength
- API call: sr.getVdiChainsInfo
- API call: sr.reclaimSpace
- API call: proxy.getAll
- API call: session.getUser
- API call: pool.listMissingPatches
I've rebooted the host and ran 'xe-toolstack-restart' but I'm getting the same results. I must be missing something.
Thanks for your help.
-
Hi,
XO tasks aren't related to XAPI tasks, it's normal to see those. They were hidden before, now it's helpful to see when we have so much calls
")
-
FYI, CBT was reverted, we'll continue to fix bugs on it in a dedicated branch for people to test (with a community and Vates joint test campaign).
-
@olivierlambert I applaud this decision. Running stable for many many months suddenly to have all these issues, without really knowing what caused it and how to resolve has been a nightmare for me

I'm all in for those new features (!) but if updating to new build to get fixes results in those issues is not good.
I've spent many hours lately, rebooted the hosts more times than the last 5 years to get backups/coalesce working again and still am not sure if everything is back to normal....
So, yes, this is a good decision.
-
This thread will be used to centralize all backup issues related to CBT: https://xcp-ng.org/forum/topic/9268/cbt-the-thread-to-centralize-your-feedback
-
After i seen the CBT stuff was reverted on github, i updated to the latest commit on my home server, (253aa) i can report my backups are now working as they should and coalesce runs without issues leaving a clean health check dashboard again. :). Glad to see this has been held back on XOA as well as i was planning to stay on 5.95.1 otherwise! Looking forward to CBT eventually all the same!
-
@flakpyro Just updated, run my delta backups and all is fine

-
-
Same problem here 300+ sessions and counting
XAPI restart did not solve the issue... -
Doesn't seem to be respecting [NOBAK] anymore for storage repos. Tried '[NOSNAP][NOBAK] StorageName' and it still grabs it.
-
On the VDI name, right?
-
@olivierlambert I believe so. It is the Disks tab of a VM. [NOBAK] was working but now the NAS is complaining about storage space. This VM has a disk on the NAS so it is backing it up twice. Added [NOSNAP] just as a test with the same result.

It is running a full backup if that makes any difference.
-
Ping @julien-f
-
@ryan-gravel I cannot reproduce, both Full Backup and Incremental Backup correctly ignore VDIs with
[NOBAK]in their name label. -
@julien-f It's happening to me too... my
[NOBAK]disk is being backed up now (commit 0e4a3) using the normal Backup (running a full). -
-
With today's update (feat: release 5.96.0, master 96b7673) things are working well again. I have not seen any Orphan VDI/snapshots or stuck Control Domain VDIs (but it may take time to test). Thanks to the Vates team!
-
Hello, can you please try the
buffered-task-eventsbranch and let me know if that solves the issue?