CBT: the thread to centralize your feedback
-
@manilx I have the the option "Purge snapshot data when using CBT" in the backup job enabled.
The VMs themselves are staying on the same NFS SR shared between the two hosts in the same pool. I simply migrated the VM from host 1 to host 2 leaving the storage location itself unchanged.
-
Is your XO able to reach both hosts directly?
-
@olivierlambert Yes, the two hosts and XO are all on the same subnet.
-
I've seen some changes/updates on GH by @florent , but I can't tell much more on my side
") We can try to test this very scenario though.
We can try to test this very scenario though. -
@olivierlambert Using current XO (07024). I'm having problems with one VM and hourly Continuous Replication (Delta, CBT/NBD). The VM has three VDIs attached. Sometimes it works just fine. But it does error out at least once a day and transferring hundreds of gigs of data for its retries.
stream has ended with not enough data (actual: 446, expected: 512) Couldn't deleted snapshot data Disk is still attached to DOM0 VMOn the next CR job it works (and deletes snapshots) but normally leaves a task running from before on the pool master for the export (that's doing nothing, stuck at 0%). A tool stack restart is required to free it.
It's odd that it complains about the disk attached to Dom0 on a run where it leaves a Dom0 export task but then on the next run it works without error (and the VDI task still attached to Dom0).
I can't force the problem to happen, but it keeps happening.
-
@olivierlambert last week @florent implemented some changed code at our end, but this did not seem to resolve the issue, we are using a proxy for backups, i am not shure is the changed code was deployed to our xoa or xoa proxy, as we are still encountering the issue i have now changed the settings to not use the proxy, so far no stream errors yet. I still see the data destory vdi in use but that could be a different problem. I will keep an eye on it to check if indeed florent did not deploy the upgrade to the proxy and we did therefore not see the changes.
Anyone using proxy in this situations where the stream error occurs?
-
@flakpyro did the same test with nfs based vm, but also can’t reproduce the problem here.
-
@olivierlambert unfortunatly it did not resolve the stream problem, just got another one.
-
@olivierlambert I just got this error to on our production pools!
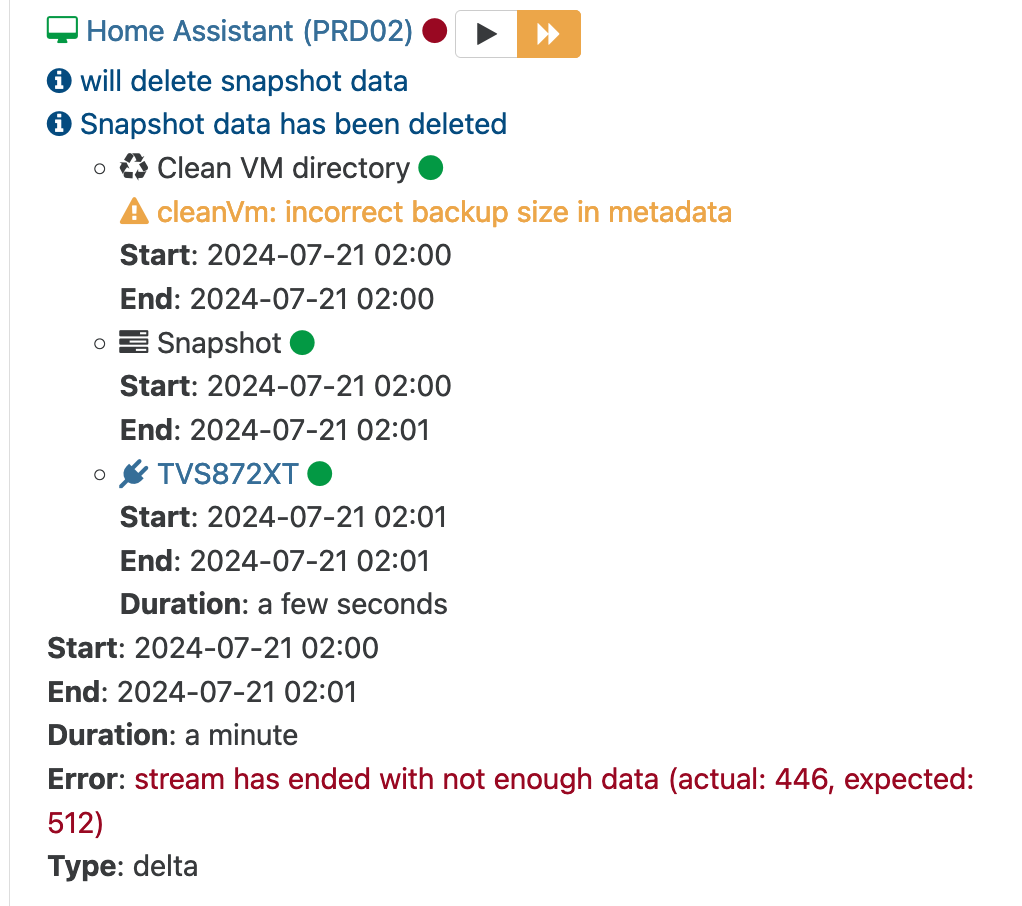
-
@manilx ticket opened.
-
@manilx The
incorrect backup sizewarning is a known issue that we will investigate soon -
@julien-f said in CBT: the thread to centralize your feedback:
@manilx The
incorrect backup sizewarning is a known issue that we will investigate soon
-
@julien-f and the stream error?
-
@rtjdamen We are investigating it as well
For the XO backend team, the next few months are focused on stabilization, bug fixes and maintenance
-
@julien-f @florent @olivierlambert I'm using XO source master (commit c5f6b). Running Continuous Replication with NBD+CBT and Purge Snapshot. With a single (one) NBD connection on the backup job, things work correctly. With two NBD connections I see some Orphan VDIs left almost every time after the backup job runs. They are different ones each time.
-
I noticed when migrating some VDIs with CBT enabled from one NFS SR another that the CBT only snapshots are left behind. Perhaps this is why a full backup seems to be required after a storage migration?
-
@flakpyro i know from our other backup software we use that migrating cbt enabled vdi’s is not supported on xen, when u migrate between sr it will disable cbt on that vdi. This is causing a new full. This is by design
-
@rtjdamen Makes sense, it would be nice is XOA cleaned up these small CBT snapshots though after a migration from one SR to another.
-
@flakpyro indeed, sounds like a bug. It should delete the snapshot, disable cbt and then migrate to the other sr.
-
I've been out of life for a while.
is it any known problem with CBT file restore?
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login