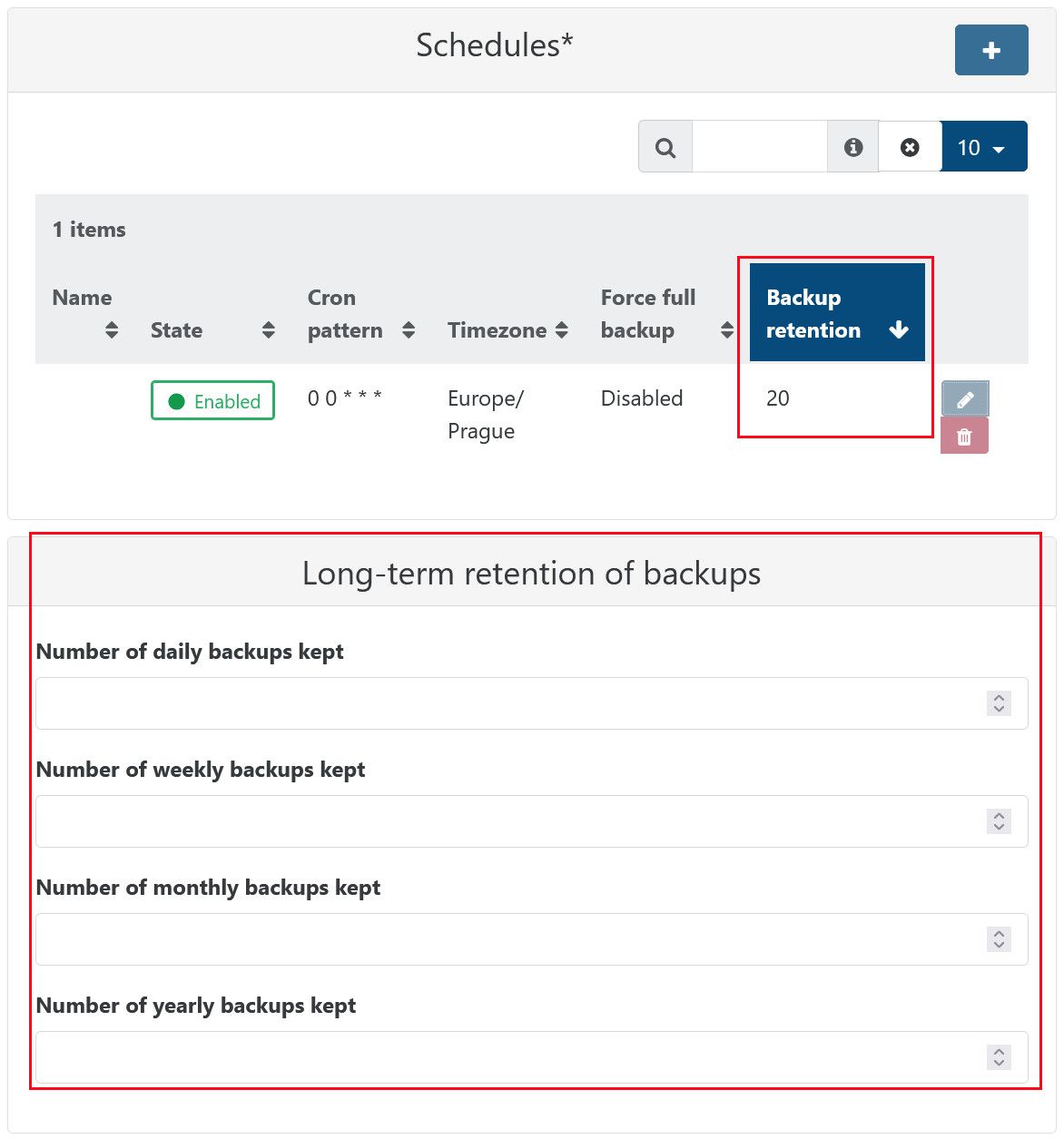
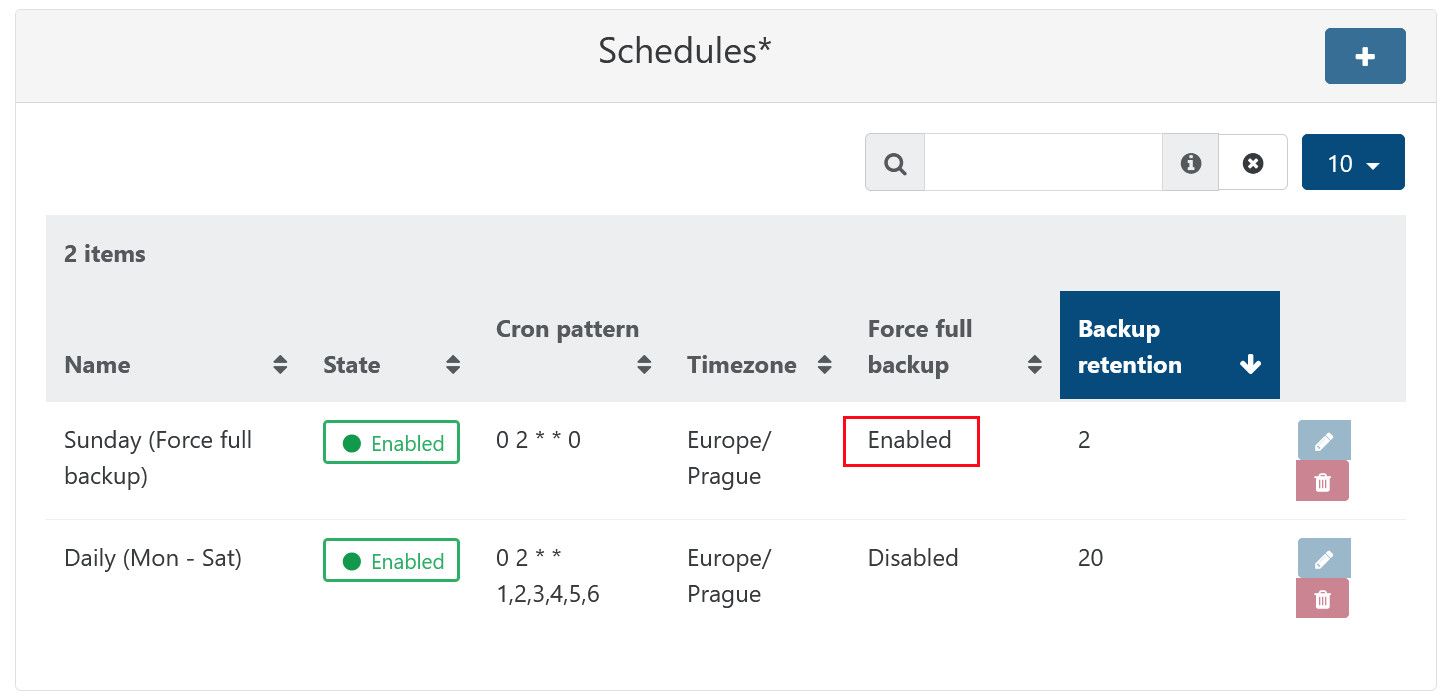
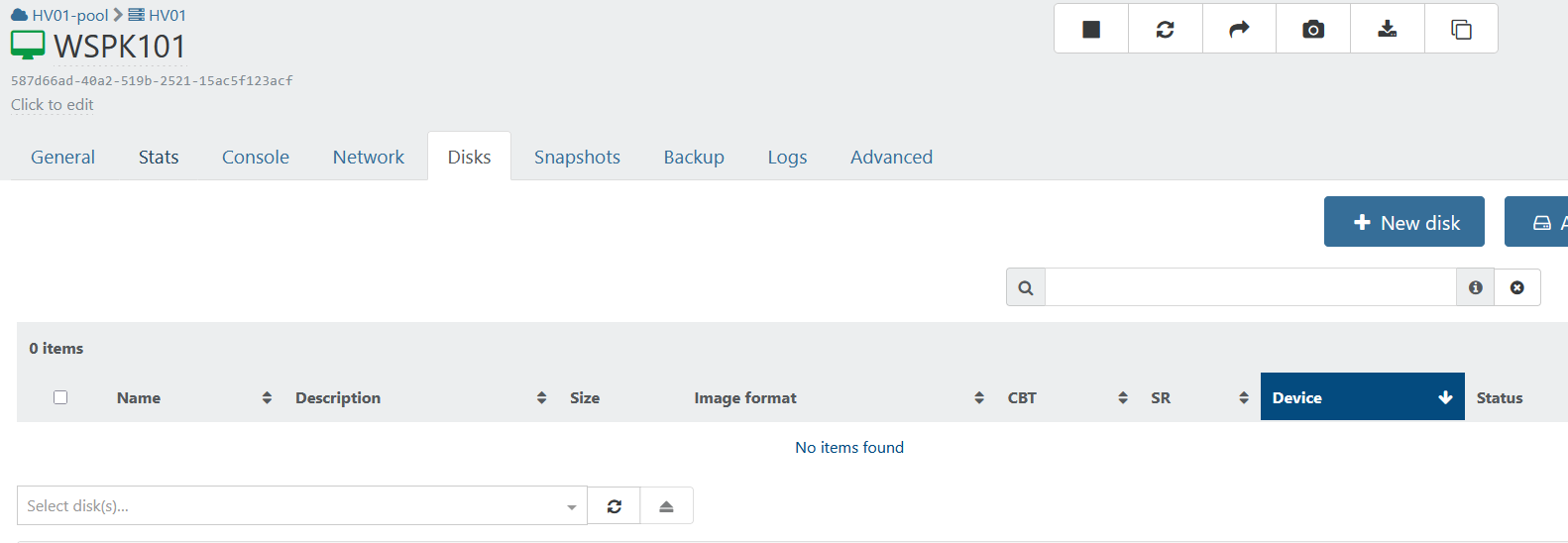
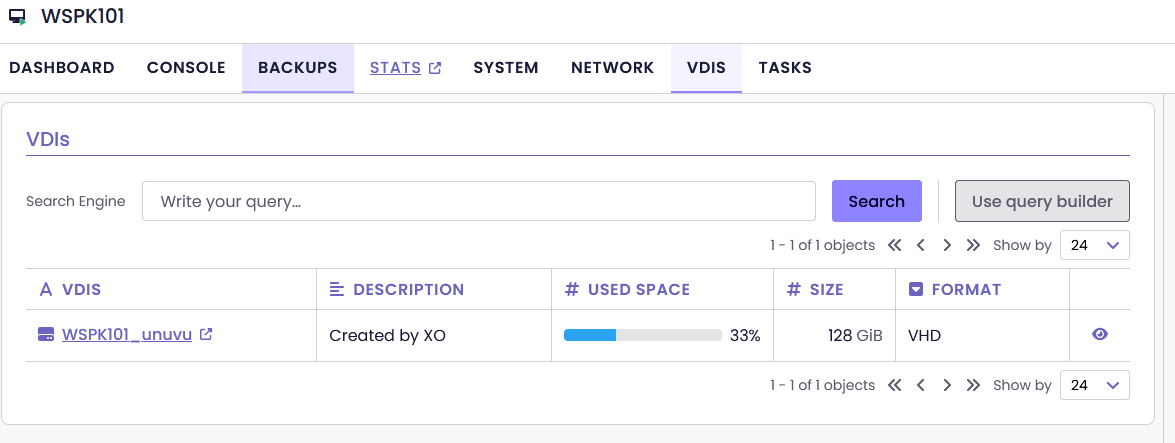
@kagbasi-ngc Hi, thanks for your thoughts.
I get on well with Linux myself - I’m using XO from source following the documentation, and actually, Ronivay’s script, as you mentioned, makes it all even handier. Still, I can’t help but think - your average home user, a total amateur, is just going to land on the XCP-ng host homepage and click "Deploy XOA". And then they’ve no backup, outside of the trial period. But sure, if XOA is aimed squarely at business and enterprise users with paid licences, fair enough that makes perfect sense.
I just feel like backup isn’t really a purely business or enterprise feature, unlike, say, proxy instances or hyper-converged storage. It's something even home users would genuinely benefit from.
But as it is mentioned above, that’s just how it’s set up - and like you said yourself, everyone’s got the chance to learn something new. And sure, in the age of AI chatbots, there’s really no excuse not to manage it ")