S3 / Wasabi Backup
-
@cdbessig Thanks.
I need to investigate the bug further.
About the folder: are you using AWS S3 or something else? Because S3 normally doesn't need to create a folder, you can just write straight wherever you want, and I was wondering if "S3-compatible" emulate this behavior.
-
I am using Wasabi
-
I want to report I was able to make a backup to Wasabi S3 like storage via native XO S3 beta option. This is amazing for homelabbers like me who don't have access to other resilient storage. Thank you!
-
Also running into the same "Interrupted" message, with VM's that are larger than 7+GB or so (this is not a hard limit, just what I've tested). I've tried with zstd compression and none, both are "interrupted."
-
Please upgrade to the latest version, this should be solved now
")
-
Updated today. Here's the snippet from syslog.
Oct 14 14:42:00 chaz xo-server[101910]: [load-balancer]Execute plans! Oct 14 14:43:00 chaz xo-server[101910]: [load-balancer]Execute plans! Oct 14 14:44:00 chaz xo-server[101910]: [load-balancer]Execute plans! Oct 14 14:44:16 chaz xo-server[101910]: 2020-10-14T21:44:16.127Z xo:main INFO + WebSocket connection (::ffff:10.0.0.15) Oct 14 14:44:59 chaz xo-server[101910]: 2020-10-14T21:44:59.644Z xo:xapi DEBUG Snapshotting VM Calculon as [XO Backup Calculon-Onetime] Calculon Oct 14 14:45:00 chaz xo-server[101910]: [load-balancer]Execute plans! Oct 14 14:45:02 chaz xo-server[101910]: 2020-10-14T21:45:02.694Z xo:xapi DEBUG Deleting VM [XO Backup Calculon-Onetime] Calculon Oct 14 14:45:02 chaz xo-server[101910]: 2020-10-14T21:45:02.916Z xo:xapi DEBUG Deleting VDI OpaqueRef:67b407aa-14a4-4452-9d7c-852b645bbd90 Oct 14 14:46:01 chaz xo-server[101910]: [load-balancer]Execute plans! Oct 14 14:46:59 chaz xo-server[101910]: _watchEvents TimeoutError: operation timed out Oct 14 14:46:59 chaz xo-server[101910]: at Promise.call (/opt/xen-orchestra/node_modules/promise-toolbox/timeout.js:13:16) Oct 14 14:46:59 chaz xo-server[101910]: at Xapi._call (/opt/xen-orchestra/packages/xen-api/src/index.js:666:37) Oct 14 14:46:59 chaz xo-server[101910]: at Xapi._watchEvents (/opt/xen-orchestra/packages/xen-api/src/index.js:1012:31) Oct 14 14:46:59 chaz xo-server[101910]: at runMicrotasks (<anonymous>) Oct 14 14:46:59 chaz xo-server[101910]: at processTicksAndRejections (internal/process/task_queues.js:97:5) { Oct 14 14:46:59 chaz xo-server[101910]: call: { Oct 14 14:46:59 chaz xo-server[101910]: method: 'event.from', Oct 14 14:46:59 chaz xo-server[101910]: params: [ [Array], '00000000000012051192,00000000000011907676', 60.1 ] Oct 14 14:46:59 chaz xo-server[101910]: } Oct 14 14:46:59 chaz xo-server[101910]: } Oct 14 14:47:00 chaz xo-server[101910]: [load-balancer]Execute plans! Oct 14 14:48:05 chaz xo-server[101910]: [load-balancer]Execute plans! Oct 14 14:48:06 chaz xo-server[101910]: terminate called after throwing an instance of 'std::bad_alloc' Oct 14 14:48:06 chaz xo-server[101910]: what(): std::bad_alloc Oct 14 14:48:06 chaz systemd[1]: xo-server.service: Main process exited, code=killed, status=6/ABRT Oct 14 14:48:06 chaz systemd[1]: xo-server.service: Failed with result 'signal'. Oct 14 14:48:07 chaz systemd[1]: xo-server.service: Service RestartSec=100ms expired, scheduling restart. Oct 14 14:48:07 chaz systemd[1]: xo-server.service: Scheduled restart job, restart counter is at 1. Oct 14 14:48:07 chaz systemd[1]: Stopped XO Server.Transfer (Interrupted) started at 14:45:03.
{ "data": { "mode": "full", "reportWhen": "always" }, "id": "1602711899558", "jobId": "c686003e-d71a-47f1-950d-ca57afe31923", "jobName": "Calculon-Onetime", "message": "backup", "scheduleId": "9d9c2499-b476-4e82-a9a5-505032da49a7", "start": 1602711899558, "status": "interrupted", "tasks": [ { "data": { "type": "VM", "id": "8e56876a-e4cf-6583-d8de-36dba6dfad9e" }, "id": "1602711899609", "message": "Starting backup of Calculon. (c686003e-d71a-47f1-950d-ca57afe31923)", "start": 1602711899609, "status": "interrupted", "tasks": [ { "id": "1602711899614", "message": "snapshot", "start": 1602711899614, "status": "success", "end": 1602711902288, "result": "ae8968f8-01bb-2316-4d45-9a78c42c4e95" }, { "id": "1602711902294", "message": "add metadata to snapshot", "start": 1602711902294, "status": "success", "end": 1602711902308 }, { "id": "1602711903334", "message": "waiting for uptodate snapshot record", "start": 1602711903334, "status": "success", "end": 1602711903545 }, { "id": "1602711903548", "message": "start VM export", "start": 1602711903548, "status": "success", "end": 1602711903571 }, { "data": { "id": "8f721d6a-0d67-4c67-a860-e648bed3a458", "type": "remote" }, "id": "1602711903573", "message": "export", "start": 1602711903573, "status": "interrupted", "tasks": [ { "id": "1602711905594", "message": "transfer", "start": 1602711905594, "status": "interrupted" } ] } ] } ] } -
Your
xo-serverprocess crashed, so it's expected that your backup is interrupted.Because you are using it from sources, I can't be sure about the issue origin, but here I have the feeling you got out of memory and Node process crashed.
-
Thanks for the hint. The upload still eventually times out now (after 12000ms of inactivity somewhere), and I still have sporadic TimeOutErrors (see above) during the transfer.
However, the
xo-serverprocess doesn't obviously crash anymore after I increased VM memory from 3GB to 4GB. I see that XOA defaults to 2GB -- what's recommended at this point (~30 VMs, 3 hosts)?With both 3GB or 4GB,
topshows thenodeprocess taking ~90% of memory during a transfer. I wonder if it's buffering the entire upload chunk in memory?With that in mind, I increased to 5.5GB, since the largest upload chunk should be 5GB. And it completed the upload successfully, though still using 90% memory throughout the process. This ended up being a 6GB upload, after zstd.
-
It shouldn't buffer anything. Also increasing VM memory won't change the Node process memory. The cache is used by the system because there's RAM, but what matters in the Node memory. See https://xen-orchestra.com/docs/troubleshooting.html#memory
-
Again, thanks for the help with this.
Whether or not the node process is actually using that much (I've been reading that by default, it maxes around 1.4 GB, but I just increased that with
--max-old-space-size=2560), larger S3 backups/transfers are still only successful if I increase XO VM memory to > 5 GB.A recent backup run showed overall usage ballooned to 5.5+ GB during the backup, and then went back to ~1.4GB afterwards.
I don't know if this is intended behavior or if you want to finetune it later, but leaving the VM at 6 GB works for me.
-
It shouldn't be the case. Are you using XOA or XO from the sources?
-
@olivierlambert From sources. Latest pull was last Friday, so 5.68.0/5.72.0.
Memory usage is relatively stable around 1.4 GB (most of this morning, with
--max-old-space-size=2560) , balloons during a S3 backup job, and then goes back down to 1.4 GB when transfer is complete.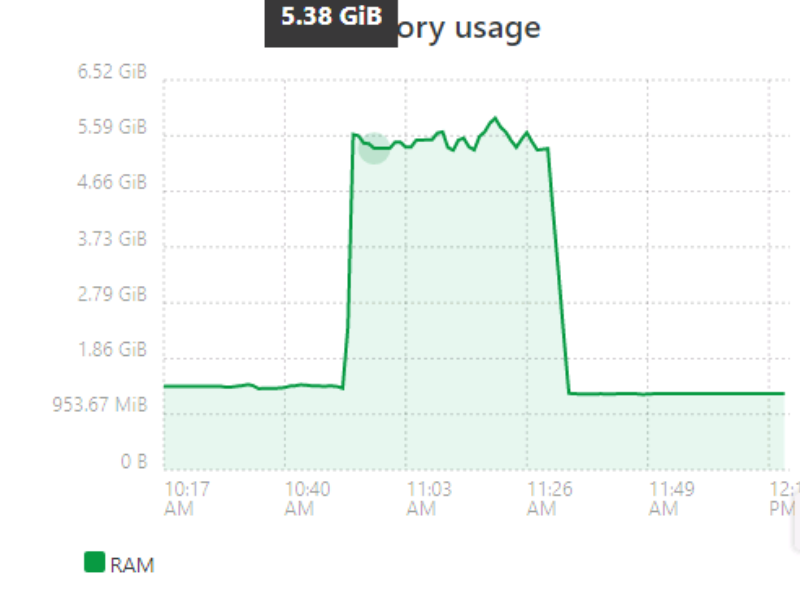
edit: The above was a backup without compression.
-
-
OK, DL'ed/Registered XOA, bumped it to 6 GB just in case (VM only, not the node process).
Updated to XOA latest channel, 5.51.1 (5.68.0/5.72.0). (p.s. thanks for the config backup/restore function. Needed to restart the VM or xo-server, but retained my S3 remote settings.)
First is a pfSense VM, ~600 MB after zstd. The initial 5+GB usage is VM bootup.
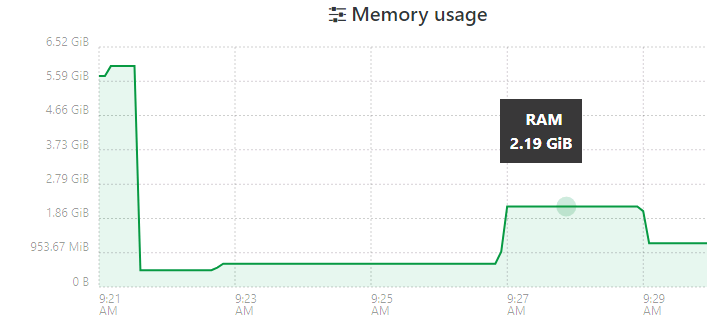
Next is the same VM that I used for the previous tests. ~7GB after ztsd. The job started around 9:30, where the initial ramp-up occurred (during snapshot and transfer start). Then it jumped further to 5+ GB.
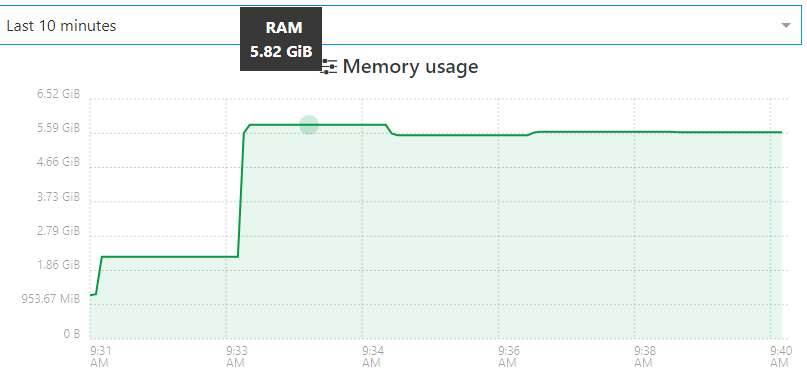
That's about as clear as I can get in the 10 minute window. It finished, dropped down to 3.5GB, and then eventually back to 1.4GB.
-
@klou Did you try it without increasing the memory in XOA?
-
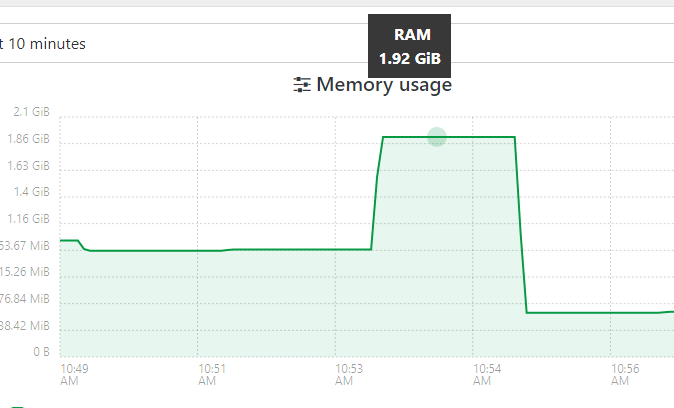
Just did, reduced to 2GB RAM. The pfSense Backup was about the same, except the post-backup idle state was around 900MB usage.
The 2nd VM bombed out with an "Interrupted" transfer status (similar to a few posts above).
-
@klou is it happening in a full backup? (this question will help me look at the right place in the code)
-
Yes, Full Backup, target is S3, both with or without compression.
(Side note: I didn't realize that Delta Backups were possible with S3. This could be significant in storage space. But I also assume that this is *nix VMs only?)
-
@klou
thanks.I assume all kinds of VMs can be backed up in delta. I don't have any connection between the VM type and the remote type.
-
If it helps, I'm reasonably certain that I was able to backup and upload similarly sized VMs previously without memory issues, before the 50GB+ chunking changes.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login