Our future backup code: test it!
-
@flakpyro Oh thank you. I try to go through every update post but I must have missed that one.
It worked

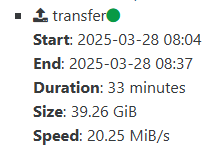
Makes a big difference for this VM if I back up a partially filled 250GB disk vs a largely full 8,250GB set of disks when 8TB of that doesn't need to be backed up.
-
@CodeMercenary that is exactly the use case of the [NOBAK]
the best way to speed up a transfer is to skip the transfer -
@john.c no, but this is high on our backlog, but there is no easy solution to autodetect the settings without booting the VM
Still, we have a cli to mount a VHD as a raw disk : https://github.com/vatesfr/xen-orchestra/tree/master/%40vates/fuse-vhd , this can allow you to then mount any complex setup . This hide the complexity of the vhd chain, then encryption at rest, vhd blocks, and storage difference.
-
@flakpyro today the backup code use binary stream in a the vhd format. This format is limited, by design , to 2TB disks
xcp-ng team introduce the qcow2 format to handle bigger disk
By using a independant format, we'll be able to handle both vhd and qcow2 on the backup side without multiplying complexity. We'll also be able to build the adapter to handle the various vmdk sub format (rax, cowd, sesparse and stream optimized) used by v2v and import bigger disks directly -
Could i test it on prod, along with real backups? or better to setup 2nd XO instance.
-
It's your call, but there's no guarantee it won't break for now, as the code is relatively young.
-
@olivierlambert but could it change old backup tasks\compability or something else? tests with real data obviously more helpful.
-
I will let @florent answering this one

-
I'm still getting "Cannot find module '@vates/generator-toolbox'" errors when I try to build it. I'm using the 'feat_generator_backups" branch.
-
Thanks for your feedback, @florent will take a look.
-
@Davidj-0 Are you using it from source or through a thrid party script ?
because this dependency is present in the branch, but still not published on npm
-
@Tristis-Oris said in Our future backup code: test it!:
@olivierlambert but could it change old backup tasks\compability or something else? tests with real data obviously more helpful.
It could gives us more informaitons, but in the other hand we are still in the validation phase.
-
 F florent referenced this topic on
F florent referenced this topic on
-
same error as above
@xen-orchestra/disk-transform:build: cache miss, executing 6b8daba7020cf148 @xen-orchestra/disk-transform:build: yarn run v1.22.22 @xen-orchestra/disk-transform:build: $ tsc @xen-orchestra/disk-transform:build: src/SynchronizedDisk.mts(2,30): error TS2307: Cannot find module '@vates/generator-toolbox' or its corresponding type declarations. @xen-orchestra/disk-transform:build: error Command failed with exit code 2. @xen-orchestra/disk-transform:build: info Visit https://yarnpkg.com/en/docs/cli/run for documentation about this command. @xen-orchestra/disk-transform:build: ERROR: command finished with error: command (/opt/xo/xo-builds/xen-orchestra-202504071027/@xen-orchestra/disk-transform) /tmp/yarn--1744010914016-0.7668824784043369/yarn run build exited (2) @xen-orchestra/disk-transform#build: command (/opt/xo/xo-builds/xen-orchestra-202504071027/@xen-orchestra/disk-transform) /tmp/yarn--1744010914016-0.7668824784043369/yarn run build exited (2) Tasks: 24 successful, 28 total Cached: 0 cached, 28 total Time: 11.251s Failed: @xen-orchestra/disk-transform#build ERROR run failed: command exited (2) error Command failed with exit code 2. info Visit https://yarnpkg.com/en/docs/cli/run for documentation about this command. + rm -rf /opt/xo/xo-builds/xen-orchestra-202504071027 -
@Tristis-Oris did you run yarn from the root of the project to install the new dependencies ?
-
yarn install v1.22.22 [1/5] Validating package.json... [2/5] Resolving packages... [3/5] Fetching packages... warning Pattern ["@intlify/shared@latest"] is trying to unpack in the same destination "/usr/local/share/.cache/yarn/v6/npm-@intlify-shared-11.1.2-d780bc8eb4e3c3ef8a3e45c421f0f5ecf59651f2-integrity/node_modules/@intlify/shared" as pattern ["@intlify/shared@11.1.2","@intlify/shared@11.1.2","@intlify/shared@11.1.2"]. This could result in non-deterministic behavior, skipping. warning Pattern ["@intlify/shared@next"] is trying to unpack in the same destination "/usr/local/share/.cache/yarn/v6/npm-@intlify-shared-11.0.0-rc.1-52a67aa12fccd9303027b48ebf017b75b7350283-integrity/node_modules/@intlify/shared" as pattern ["@intlify/shared@11.0.0-rc.1"]. This could result in non-deterministic behavior, skipping. warning bare-os@3.4.0: The engine "bare" appears to be invalid. [4/5] Linking dependencies... warning "@commitlint/cli > @commitlint/load > cosmiconfig-typescript-loader@6.1.0" has unmet peer dependency "@types/node@*". warning "@commitlint/cli > @commitlint/load > cosmiconfig-typescript-loader@6.1.0" has unmet peer dependency "typescript@>=5". warning "@typescript-eslint/eslint-plugin > ts-api-utils@1.4.3" has unmet peer dependency "typescript@>=4.2.0". warning " > @xen-orchestra/web-core@0.18.0" has unmet peer dependency "pinia@^3.0.1". warning " > @xen-orchestra/web-core@0.18.0" has unmet peer dependency "vue@~3.5.13". warning " > @xen-orchestra/web-core@0.18.0" has unmet peer dependency "vue-i18n@^11.1.2". warning " > @xen-orchestra/web-core@0.18.0" has unmet peer dependency "vue-router@^4.5.0". warning "workspace-aggregator-9e56f98d-aa3d-4c5b-aae2-45a491674f9d > @xen-orchestra/rest-api > inversify@6.2.2" has unmet peer dependency "reflect-metadata@~0.2.2". warning "workspace-aggregator-9e56f98d-aa3d-4c5b-aae2-45a491674f9d > @xen-orchestra/rest-api > swagger-ui-express@5.0.1" has unmet peer dependency "express@>=4.0.0 || >=5.0.0-beta". warning "workspace-aggregator-9e56f98d-aa3d-4c5b-aae2-45a491674f9d > @vates/event-listeners-manager > tap > @tapjs/test > @isaacs/ts-node-temp-fork-for-pr-2009@10.9.7" has unmet peer dependency "@types/node@*". warning "workspace-aggregator-9e56f98d-aa3d-4c5b-aae2-45a491674f9d > @xen-orchestra/rest-api > inversify > @inversifyjs/core > @inversifyjs/reflect-metadata-utils@0.2.4" has unmet peer dependency "reflect-metadata@0.2.2". warning "workspace-aggregator-9e56f98d-aa3d-4c5b-aae2-45a491674f9d > @vates/event-listeners-manager > tap > @tapjs/asserts > tcompare > react-element-to-jsx-string@15.0.0" has unmet peer dependency "react@^0.14.8 || ^15.0.1 || ^16.0.0 || ^17.0.1 || ^18.0.0". warning "workspace-aggregator-9e56f98d-aa3d-4c5b-aae2-45a491674f9d > @vates/event-listeners-manager > tap > @tapjs/asserts > tcompare > react-element-to-jsx-string@15.0.0" has unmet peer dependency "react-dom@^0.14.8 || ^15.0.1 || ^16.0.0 || ^17.0.1 || ^18.0.0". warning Workspaces can only be enabled in private projects. [5/5] Building fresh packages... $ husky install husky - Git hooks installed Done in 39.86s.but same error.
-
@Tristis-Oris it looks like the build from completly empty repo don't work as expected
can you try this :
cd @vates/generator-toolbox/ yarn build cd - yarn buildI am working on improving the build process in the meantimes
-
@florent yep it works now.
-
So is it this new backup code which the tape back up support will be plugging into?
If so I have been thinking may be have it when doing the tape backup support, get the XOA to install the packages when required after prompting the user. Also have xo-server instruct the creation of a new disk image for attaching to xoa. The new disk image would act as storage or cache for the extra data used by tape drive backups.
The tape drive related software wouldn't be installed by default, unless specified as such during deployment with the XOA deploy tool. But instead installed at user request, by selecting to use tape backup destination when setting up back up job, clicking on the shim widget about tape backups or restoring from an online Vates account backup of XOA settings.
-
@florent I'm doing this from source.
Runninggit pull --rebaseseems to have fixed the build problems. -
@john.c the backup on tape is still on the roadmap but won't be for this step
The main change is that we'll have to rework part of the code to ensure we write data sequentially + the management tools ( which backup is on which tape )
You can try the FS on tape , but the performance penalty is heavy
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login