@iams3le we have switched to the signed xcp-ng drivers. We also replaced our older 2022 servers.
Posts
-
RE: Citrix or XCP-ng drivers for Windows Server 2022
-
RE: Execute pre-freeze and post-thaw
@dinhngtu said in Execute pre-freeze and post-thaw:
There used to be quiescent snapshot capabilities in older versions (mainly for Windows VSS support), but it has since been removed. I'd say @Team-XAPI-Network knows more about the reason.
We have vmware with ppdm backups and the vss part is actually causing some annoying issues such as quite long io stalls. But I do understand the reason for vss, especially for applications that aren't crash safe.
-
RE: Remote syslog broken after update/reboot? - Changing it away, then back fixes.
I've been considering remote syslog too. Does enabling remote syslog remove local logging?
-
RE: restore metadata for pool -> incompatible version
@Danp said in restore metadata for pool -> incompatible version:
My understanding is that you can only restore metadata to the exact same version of xapi. Does your old pool still exist?
This is quite the limitation. Is it documented?
-
RE: 🛰️ XO 6: dedicated thread for all your feedback!
@cmoriarty said in
 ️ XO 6: dedicated thread for all your feedback!:
️ XO 6: dedicated thread for all your feedback!:I use the "VM notes" feature in XO 5 for lots of things, and I appreciate having the markdown capability. It seems now these VM Notes are stuffed into a small "Description" field inside the "Quick Info" panel for a VM.
Currently in XO 6, it looks like my notes are getting truncated in this new description field, are there plans to preserve the "VM Notes" functionality? Or should I be backing them up now before I lose them?
Me too. They serve as important info, documentation, and other bits of info that needs to be quickly on-hand.
What I would like to add is a way to upload images and include them in the Markdown.
-
RE: SR.Scan performance withing XOSTOR
What is the purpose of the SR scans, and why do they indeed have to run ao frequently?
-
RE: 🛰️ XO 6: dedicated thread for all your feedback!
@acebmxer said in
️ XO 6: dedicated thread for all your feedback!:So question what happens when i thinks the vm disk is full? When will it clear up? Only thing i can think of was coping 13gb veeam ISO over few times testing things and stuff. but that has been a while now.
No, it will not. You can create a new vdi and move the files over manually.
-
RE: Mirror backup: No new data to upload for this vm?
@Bastien-Nollet Thanks. I am on Stable channel as I use XOA Premium.
-
RE: suggestions for upgrade path XCP-ng 8.2.1 -> XCP-ng 8.3.0
@ditzy-olive I think 'warm migration' should have worked?
But perhaps if your old pool lost its pool master it doesn't work?
-
RE: suggestions for upgrade path XCP-ng 8.2.1 -> XCP-ng 8.3.0
This is what I did.
- Migrated VMs off one host
- Disconnected that host from the pool
- Made a clean install of version 8.3 on that host and made into a new pool.
- Live-migrated grated VMs back to the new pool
- Made clean installs on the remaining hosts
- Joined the remaining hosts to the new pool
-
RE: 🛰️ XO 6: dedicated thread for all your feedback!
@olivierlambert that's very good.
I like dark mode, but not with high contrast elements as it hurts my eyes. This
Nordtheme is much better than the other Purple dark mode for me. -
RE: Mirror backup: No new data to upload for this vm?
The delta backup job saves to srv04-incremental and srv12-incremental.
The incremental mirror job has srv04-incremental as source and srv12-incremental as destination.The VM that showed no data to copy message was a the "Incremental backup every 4 hours - 8 days retention" backup job.
Originally I only had one remote,
srv04. I createdsrv04-incrementaland renamedsrv04tosrv04-fulland used the mirror backup feature to copy all delta backups tosrv04-incremental(as I did not want to attempt to move the data on the NFS backend side). Then, I set upsrv12-incrementalandsrv12-fulland created mirror jobs to copy fromsrv04-fullandsrv04-incremental. Once the mirror backups were completed I switched the normal backup jobs to store backups on both backup servers.I can set up a support connection if you want to remotely check this.
-
RE: Mirror backup: No new data to upload for this vm?
Here is the incremental backup config. Originally we only had the remote called srv04-incremental. I have now added srv12-incremental and wanted to copy over all existing backups to the new remote. I did the same with full backups too. Now I have each backup job using both remotes.
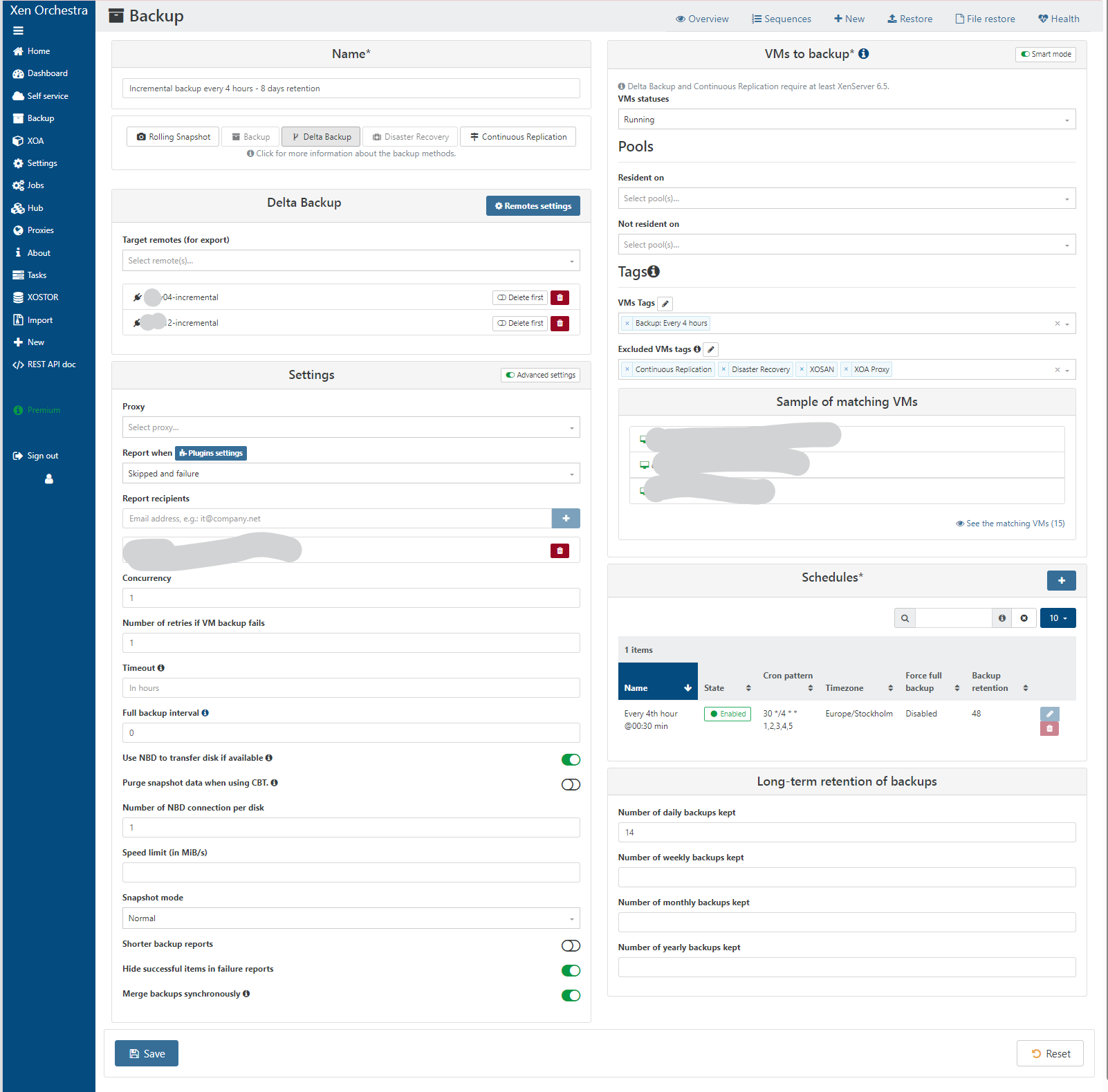
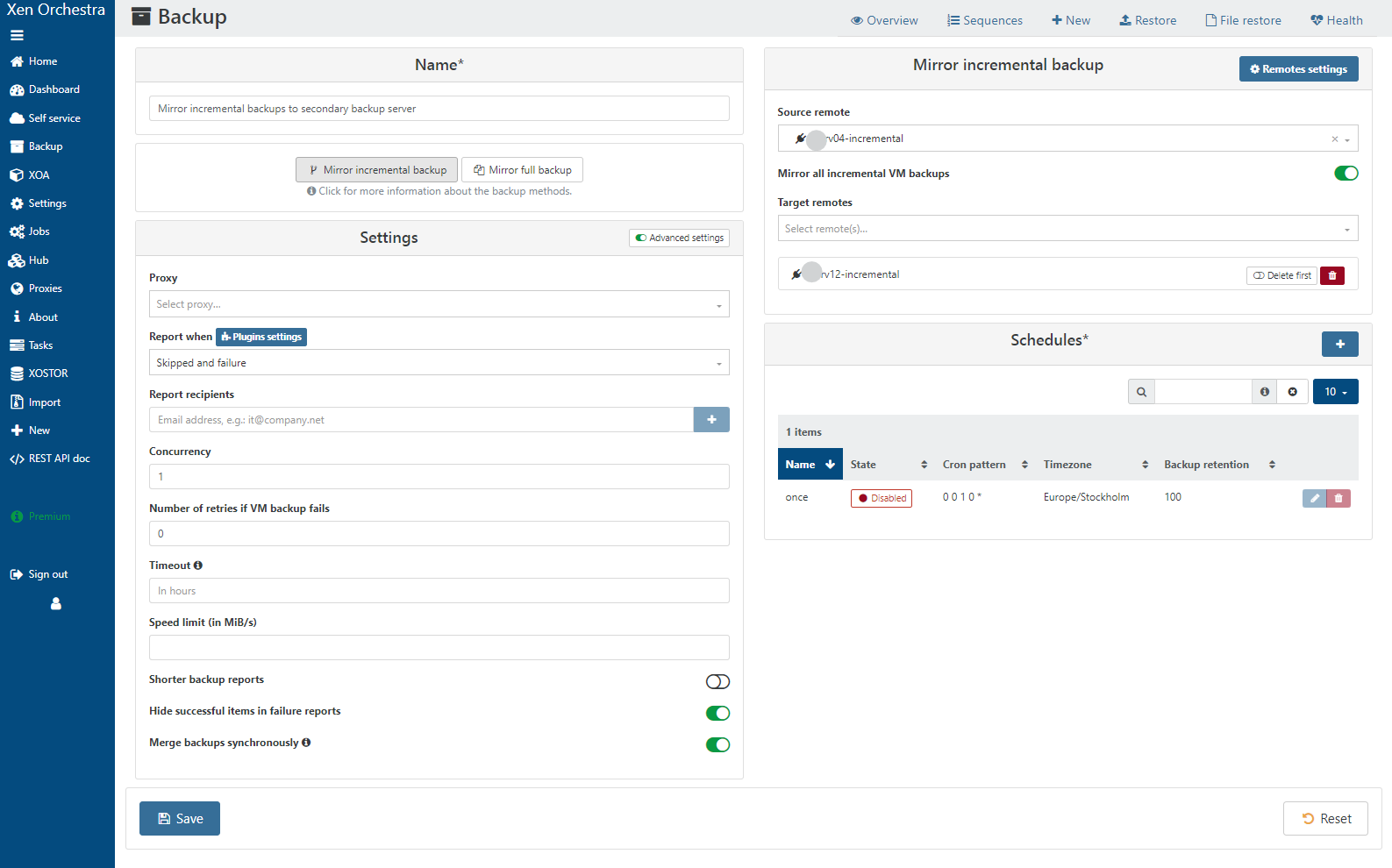
-
RE: Mirror backup: No new data to upload for this vm?
I noticed too that both
mirror backupandfull backupdo not actually copy all backups.This shows the source Remote on the left and destination remote on the right. I made sure the retention setting in the mirror backup is high enough to not exclude anything, yet we are not getting everything transferred:
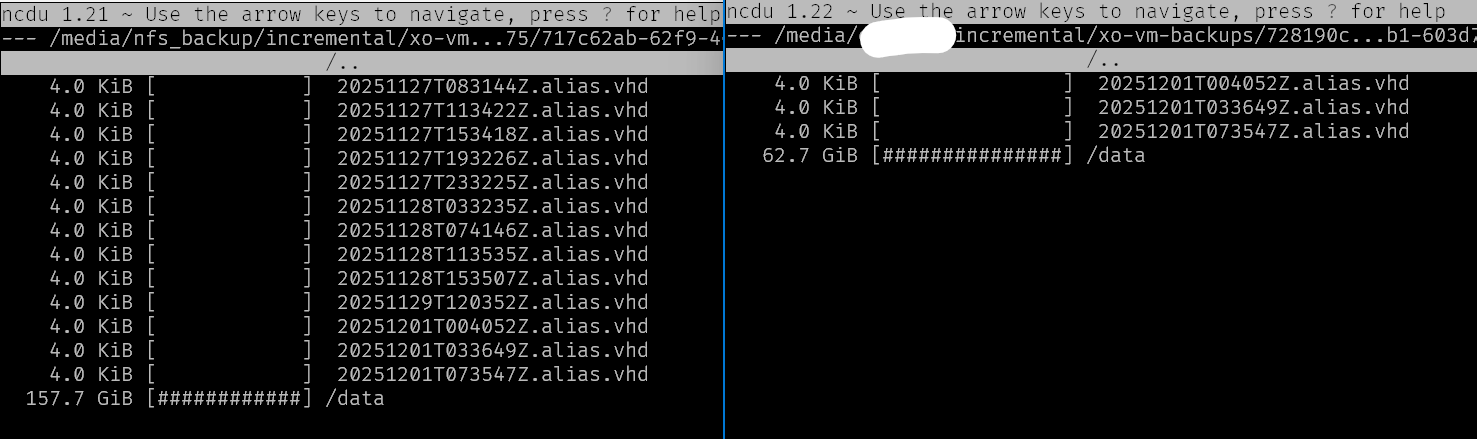
Se also the same for full mirror backups: https://xcp-ng.org/forum/topic/11624/mirror-of-full-backups-with-low-retention-copies-all-vms-and-then-deletes-them/
-
RE: Mirror of full backups with low retention - copies all vms and then deletes them
It looks like it transfers one backup, deletes it, starts the next backup, deletes it, starts the next one... and so on. This seems rather inefficient for
fullbackups. I can understand it has to transfer the full chain when dealing withincrementalbackups, even if it has to prune and merge them afterwards.I also notice that even though I set the retention to 1000 in the full mirror job, not all backups are copied:

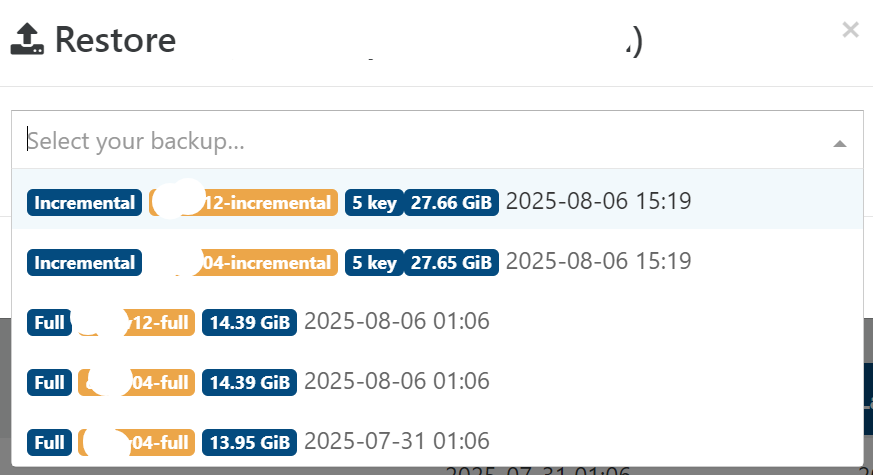
{ "data": { "type": "VM", "id": "0ecd9bc3-b4e8-8f0e-e50d-6b94420ea742" }, "id": "1764584306124", "message": "backup VM", "start": 1764584306124, "status": "success", "infos": [ { "message": "No new data to upload for this VM" }, { "message": "No healthCheck needed because no data was transferred." } ], "tasks": [ { "id": "1764584306137:1", "message": "clean-vm", "start": 1764584306137, "status": "success", "end": 1764584306150, "result": { "merge": false } } ], "end": 1764584306151 }, -
Mirror of full backups with low retention - copies all vms and then deletes them
I noticed that for "Mirror full backup", the process copies every backup, and then immediately removes backups older than retention. This seems unnecesary for full backups as there is no relationship between each backup for a VM.

-
Mirror backup: No new data to upload for this vm?
I am testing the mirror backup feature. I see a message "New new data to upload for this VM" although it is clearly transfering data.
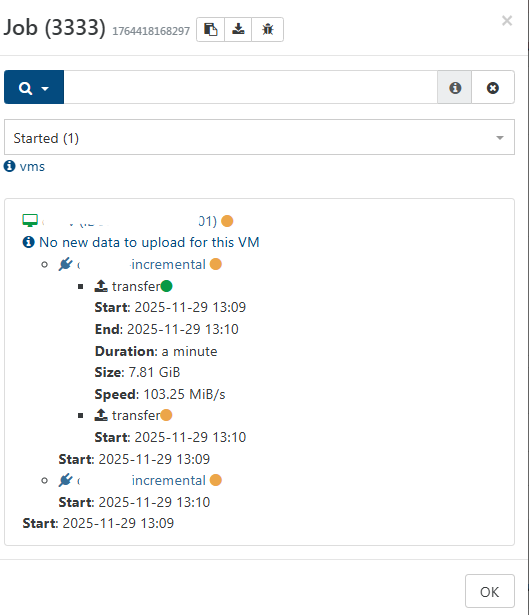
I am using XOA on stable channel.
-
RE: Long backup times via NFS to Data Domain from Xen Orchestra
@MajorP93 aha, yea. Per disk concurrency is important too.
-
RE: Long backup times via NFS to Data Domain from Xen Orchestra
@MajorP93 You need to set concurrency so it only exports one VM at the time.

-
Mirror backup: Progress status and ETA
Hi,
I would like to have more progress information for the "Mirror backup" feature. Currently there is no progress other than how many VMs that have been copied so far.
What I would like is:
The total data size to be transferred plus how many VMs/backups that are left in the queue plus an approximate ETA. All this information should be available for XOA since it already knows what already exists in the source Remote.
Additionally I would like the option to cancel a running Mirror backup. The Cancel button is disabled when I try:

There is also no Task for the Mirror job listed the XOA Tasks screen.
I found an earlier question like this, but there was no answer there.
https://xcp-ng.org/forum/topic/11108/incremental-mirror-backup-progress-information-in-xoa