tl;dr - empty line(s) in /etc/xensource/usb-policy.conf crashes /opt/xensource/libexec/usb_scan.py
I did a bit of scanning through the xapi source, in particular https://github.com/xapi-project/xen-api/blob/master/python3/libexec/usb_scan.py
I'm not a python expert, so I could generally follow the flow of things, but I wasn't totally sure what was happening at a detailed level. Then I did some googling and found this xenserver help doc regarding troubleshooting usb passthrough: https://support.citrix.com/external/article/235040/how-to-troubleshoot-xenserver-usb-passth.html
This article suggested running /opt/xensource/libexec/usb_scan.py with the -d parameter for additional details and that lead me to discover that the script fails when it encounters an empty line in usb-policy.conf
[23:46 xcp-ng-4 ~]# /opt/xensource/libexec/usb_scan.py -d
Traceback (most recent call last):
File "/opt/xensource/libexec/usb_scan.py", line 681, in <module>
pusbs = make_pusbs_list(devices, interfaces)
File "/opt/xensource/libexec/usb_scan.py", line 660, in make_pusbs_list
policy = Policy()
File "/opt/xensource/libexec/usb_scan.py", line 384, in __init__
self.parse_line(line)
File "/opt/xensource/libexec/usb_scan.py", line 444, in parse_line
if action.lower() == "allow":
UnboundLocalError: local variable 'action' referenced before assignment
After removing all empty lines, usb_scan.py scanned output properly, but it was giving me an empty array
[23:53 xcp-ng-4 ~]# /opt/xensource/libexec/usb_scan.py -d
[]
Since it as no longer crashing, I decided to go back to the default usb-policy.conf then try only adding my single allow rule without any extra lines and then test.
cp /etc/xensource/usb-policy.conf.default /etc/xensource/usb-policy.conf
I inserted a new line at line 10 just above the first rule and added my allow rule:
ALLOW:vid=1050 pid=0407
and that was all that was needed! Now I can see the device after running usb_scan.py
[23:53 xcp-ng-4 ~]# /opt/xensource/libexec/usb_scan.py -d
[{"path": "2-1.1", "version": "2.00", "vendor-id": "1050", "product-id": "0407", "vendor-desc": "Yubico.com", "product-desc": "Yubikey 4 OTP+U2F+CCID", "speed": "12", "serial": "", "description": "Yubico.com_Yubikey 4 OTP+U2F+CCID"}]
I also learned that the last good output of xe usb-scan seems to be cached somewhere and is quietly returned without hesitation when usb_policy.py fails. Maybe it's logged somewhere, but I don't know.
In any case, it was as simple as an empty line -- don't take anything for granted!
Lastly, I did a bit of testing to confirm that for my Yubikey to be detected and allowed, the allow rule must be BEFORE the rule that denies HID Boot Keyboards.
This results in detection:
# When you change this file, run 'xe pusb-scan' to confirm
# the file can be parsed correctly.
#
# Syntax is an ordered list of case insensitive rules where # is line comment
# and each rule is (ALLOW | DENY) : ( match )*
# and each match is (class|subclass|prot|vid|pid|rel) = hex-number
# Maximum hex value for class/subclass/prot is FF, and for vid/pid/rel is FFFF
#
# USB Hubs (class 09) are always denied, independently of the rules in this file
DENY: vid=17e9 # All DisplayLink USB displays
DENY: class=02 # Communications and CDC-Control
ALLOW:vid=056a pid=0315 class=03 # Wacom Intuos tablet
ALLOW:vid=056a pid=0314 class=03 # Wacom Intuos tablet
ALLOW:vid=056a pid=00fb class=03 # Wacom DTU tablet
# @jeff - allow passthrough of Yubikey 5 FIPS, "Yubikey 4 OTP+U2F+CCID"
ALLOW:vid=1050 pid=0407
DENY: class=03 subclass=01 prot=01 # HID Boot keyboards
DENY: class=03 subclass=01 prot=02 # HID Boot mice
DENY: class=0a # CDC-Data
DENY: class=0b # Smartcard
DENY: class=e0 # Wireless controller
DENY: class=ef subclass=04 # Miscellaneous network devices
ALLOW: # Otherwise allow everything else
This does not:
# When you change this file, run 'xe pusb-scan' to confirm
# the file can be parsed correctly.
#
# Syntax is an ordered list of case insensitive rules where # is line comment
# and each rule is (ALLOW | DENY) : ( match )*
# and each match is (class|subclass|prot|vid|pid|rel) = hex-number
# Maximum hex value for class/subclass/prot is FF, and for vid/pid/rel is FFFF
#
# USB Hubs (class 09) are always denied, independently of the rules in this file
DENY: vid=17e9 # All DisplayLink USB displays
DENY: class=02 # Communications and CDC-Control
ALLOW:vid=056a pid=0315 class=03 # Wacom Intuos tablet
ALLOW:vid=056a pid=0314 class=03 # Wacom Intuos tablet
ALLOW:vid=056a pid=00fb class=03 # Wacom DTU tablet
DENY: class=03 subclass=01 prot=01 # HID Boot keyboards
# @jeff - allow passthrough of Yubikey 5 FIPS, "Yubikey 4 OTP+U2F+CCID"
ALLOW:vid=1050 pid=0407
DENY: class=03 subclass=01 prot=02 # HID Boot mice
DENY: class=0a # CDC-Data
DENY: class=0b # Smartcard
DENY: class=e0 # Wireless controller
DENY: class=ef subclass=04 # Miscellaneous network devices
ALLOW: # Otherwise allow everything else
Thanks to everyone who took a look. Hopefully you don't get caught by this same gotcha!
")
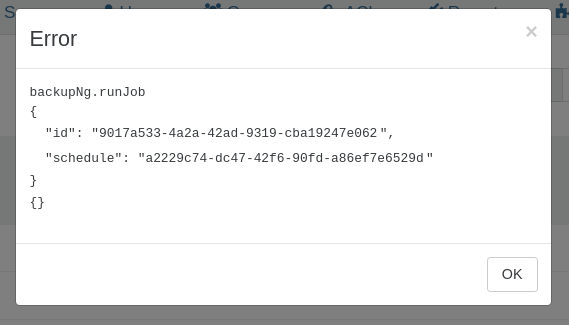
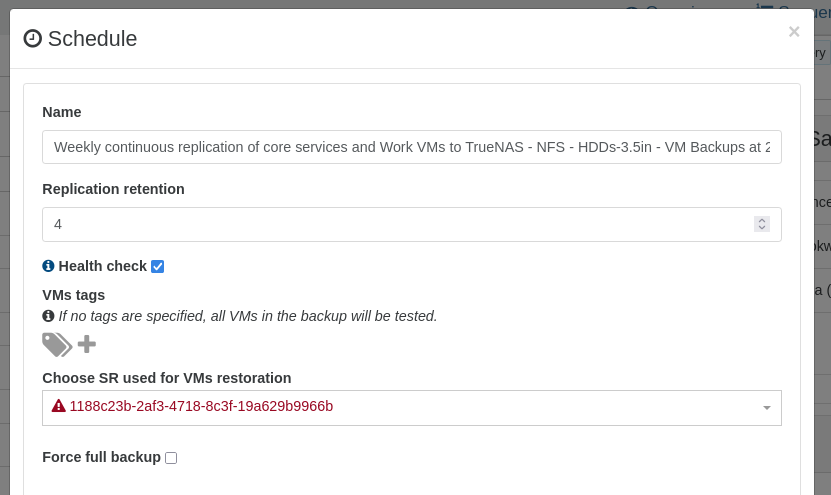
 I do think that it would be nice if Xen Orchestra could improve the error handling/messaging for situations where a task fails due to an invalid object UUID. It seems like the UI is already making a simple XAPI call to lookup the name-label of the SR, which, upon failure results in the schedule where an invalid/unknown UUID is configured displaying the invalid/unknown UUID in Red text with a red triangle.
I do think that it would be nice if Xen Orchestra could improve the error handling/messaging for situations where a task fails due to an invalid object UUID. It seems like the UI is already making a simple XAPI call to lookup the name-label of the SR, which, upon failure results in the schedule where an invalid/unknown UUID is configured displaying the invalid/unknown UUID in Red text with a red triangle.

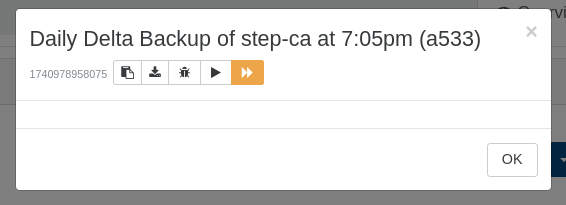
 I overlooked that the SR I had removed was being utilized for restoring Health Check vms in that Backup job...and a few others too--yay homelab fun! lol
I overlooked that the SR I had removed was being utilized for restoring Health Check vms in that Backup job...and a few others too--yay homelab fun! lol

 -- the joys of being an American millennial that graduated high school with little familial wealth just before the great recession that has never managed to get a degree
-- the joys of being an American millennial that graduated high school with little familial wealth just before the great recession that has never managed to get a degree 

 ) so I don't have logs beyond the backup report which doesn't give much more information than the UUID of a VM that doesn't exist anymore..
) so I don't have logs beyond the backup report which doesn't give much more information than the UUID of a VM that doesn't exist anymore..