I noticed you merged https://github.com/vatesfr/xen-orchestra/pull/9787
I just tried it. And it does seem to fix my original issue!
Thank you! I am always impressed by you guys. Making testing and reporting upstream (to you guys) a good experience!
I noticed you merged https://github.com/vatesfr/xen-orchestra/pull/9787
I just tried it. And it does seem to fix my original issue!
Thank you! I am always impressed by you guys. Making testing and reporting upstream (to you guys) a good experience!
I submitted this as a GitHub issue last week.
TL;DR: Backblaze aparently doesn't support those flags that are enabled by default
"Backblaze does not yet accept these headers, so we recommend downgrading to AWS Javascript 3.x SDK version 3.728.0."
Thanks again for your input and recomendations! I'll verify that this is solved by having the LUN expanded to 8GB instead. Afterwards I'll mark your answer as the solution!
@olivierlambert
I've finally had time to sit down and do some more troubleshooting.
It seems that the issue is somehow tied to the backup-jobs themselves.
Deploying XOA and subsequently importing XO-config from my XOCE instance. I continued to see several issues between both instances.
These issues pretty much went away, when I re-did the backup-jobs from scratch. And are now much more in-line with what I'm excepting to see. This was done on both XOA Stable, Latest and XOCE
I am no longer able to repoduce this at all.
So my guess is that a bug of some sort got introduced with this being a constantly updated from source instance.
Marking as solved. As I don't believe there is much more to do at this time.
@McHenry
Differences could be things such as:
Same with overprovisioning dynamic RAM
I have done some more testing.
Windows Server 2022 is also affected. 9.1.145-77
I also tried the latest WindowsPV drivers from Vates, on Windows Server 2025. 9.1.200-0. And the "problem" still persists.
It is a very low impact and low importance "problem". Since it is afaik purely costmetical.
@MathieuRA
The sdn-plugin is back. I am amazed by that quick resonse and fix. THANKS!
However, the issue with @xen-orchestra/web/typed-router.d.ts being locally modified during compilation, is still present. Leading to have to git restore @xen-orchestra/web/typed-router.d.ts before being able to pull from github.
The build-script that I use is based on (then) official docs
#!/bin/bash
set -ex
set -o pipefail
git checkout .
git pull --ff-only
yarn
yarn build
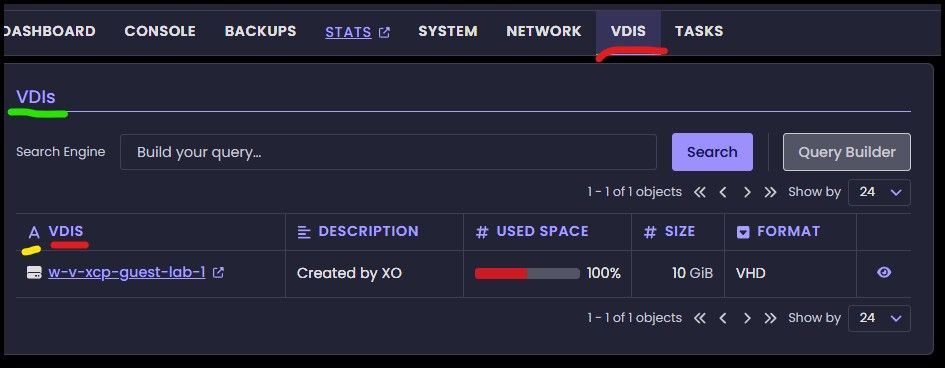
Small discrepancy: VDIS or VDIs? Which one is it? ")
Red points out where it's called VDIS.
Green where it is called VDIs.
And as a bonus feedback/question. Why is it called "A VDIS" ?(marked with yellow)
Clicking through the different parts in the leftmost pane has (what feels like) inconsistent landing pages. When in reality, it lands on the previous tab visited for that item.
Example.
If I click on Xen Orchestra Appliance I would expect to land on the Dashboard tab. But if I had previously looked inside the Pools tab, then that is where I would land.
This behaviour is the same regardless of which item I click through. Be it Pool/Host/Guest..
I'll admit that it kind of makes a little bit of sense in thought. But it feel far more jarring and confusing when navigating. Since you never really know which tab you'll be met with when browsing. As each and every level/item is handled individually, separate from all others.
I've taken a quick look, looks like it'll be solved as part of the Windows guest agent overhaul, so please look forward to that.
Thanks for the info. I will be looking forward to that, indeed.
Unfortunately the Rust-based agent is effectively not progressing. Last commit was months ago, and the 0.4.0-release was over 2 years ago, Issues aren't tagged for many months. Simple and easy MR's are left hanging in limbo.
I'm hoping they will show this project some more love and attention soon. Since I really like the idea of an open source Rust-based agent. As it is clear other things are taking precedent over it.
Thanks again for your input and recomendations! I'll verify that this is solved by having the LUN expanded to 8GB instead. Afterwards I'll mark your answer as the solution!
Thank you for your reply.
The reasoning here is that we are experimenting quite heavily at this moment.
And the thinking here is to have three LUNs each for their intended purpose.
LUNs
1 for VHD-based VDIs
1 for qcow2 based VDIs
The ones above will be used and modified quite a bit
1 for the Heartbeat. Being left alone to be as standard out-of-the-box as possible.
All of the LUNs reside on the same storage systems (Dell PowerStore at the moment). So my resoning here is that they're all on the same storage cluster, and therefore will be affected similarily regardless. Exotic corner-cases may of course show up.
But I will absolutely take your recommendations into account! And when we've stopped messing with the storage for the VMs. I will have the Heartbeat there on that as well!
Update:
We just expanded the SR to 2GB. And I'm still getting the same error.
Write permissions were verified by creating a vdi on the SR. And that was successfull with no problem.
Next step in our lab testing was going to be to enable HA. For this we chose to go with a 500MB Fibre Channel LUN.
However, when I try to enable HA I will find an error in the logs saying SR_SOURCE_SPACE_INSUFFICIENT. (Full log down below).
So my question then becomes. Are the docs out of date, or could this possibly be something else under the hood?
Note: I'm currently waiting on the storage guy to expand the SR to 1GB.
XO CE: 5811d
Node: 24
Pool: Fully updated with latest patches as of may 26, 2026
pool.enableHa
{
"pool": "37e7a3b9-8c45-c7f2-7d09-249a935dd33d",
"heartbeatSrs": [
"3efef95a-4594-5a36-a182-f2b039d51ffa"
],
"configuration": {}
}
{
"code": "SR_SOURCE_SPACE_INSUFFICIENT",
"params": [
"OpaqueRef:601b3d23-c211-b853-0a9a-2c12e16a6567"
],
"call": {
"duration": 21,
"method": "pool.enable_ha",
"params": [
"* session id *",
[
"OpaqueRef:601b3d23-c211-b853-0a9a-2c12e16a6567"
],
{}
]
},
"message": "SR_SOURCE_SPACE_INSUFFICIENT(OpaqueRef:601b3d23-c211-b853-0a9a-2c12e16a6567)",
"name": "XapiError",
"stack": "XapiError: SR_SOURCE_SPACE_INSUFFICIENT(OpaqueRef:601b3d23-c211-b853-0a9a-2c12e16a6567)
at XapiError.wrap (file:///opt/xen-orchestra/packages/xen-api/_XapiError.mjs:16:12)
at file:///opt/xen-orchestra/packages/xen-api/transports/json-rpc.mjs:38:21
at runNextTicks (node:internal/process/task_queues:65:5)
at processImmediate (node:internal/timers:472:9)"
}
Update: Changed title to better describe problem
I have done some more testing.
Windows Server 2022 is also affected. 9.1.145-77
I also tried the latest WindowsPV drivers from Vates, on Windows Server 2025. 9.1.200-0. And the "problem" still persists.
It is a very low impact and low importance "problem". Since it is afaik purely costmetical.
ping @poddingue for visibility as I believe I've found the trigger for IPv6 expanding... Live Migrations
Ah sorry I read it too quickly. This panel is only there in some occasions, but I see the point of only displaying it when we click on a relevant element. Feedback for you @julienxovates
While on the topic of the tree-view panel.
Have you noticed that the indentation changes if there is a chevron indicating that there are VMs on a host? Making it so that the hosts no longer are alinged vertically