Running it now shows no error! And no output so looks like i have no issues!
F
Offline
Posts
-
RE: XCP-ng 8.3 updates announcements and testing
-
RE: XCP-ng 8.3 updates announcements and testing
Thanks
I ran that second script on the master and it did indeed find entries:
./snapshot-fixer.py rewrite INFO:root:Check HA... INFO:root:Shutting down xapi... INFO:root:Regenerating database... INFO:root:The VM d6befe36-fea7-04f3-25f1-feada684702b has Ref:9 as its "snapshot_of" value, changing to null. INFO:root:The VM e013d9ed-63b1-9c9f-a228-d48a6047688c has Ref:89 as its "snapshot_of" value, changing to null. INFO:root:The VM 060df7ee-8af4-4c93-8265-bfa3024ccacd has Ref:1 as its "snapshot_of" value, changing to null. INFO:root:The VM da7b6ff6-d722-2120-7cc4-a1e0038a216e has Ref:307 as its "snapshot_of" value, changing to null. INFO:root:The VM 4178b057-efee-427e-bcad-67323419ac7a has Ref:9 as its "snapshot_of" value, changing to null. INFO:root:The VM 8d624e49-ca99-4af6-b17c-38cad0646194 has Ref:1 as its "snapshot_of" value, changing to null. INFO:root:The VM dc72da43-f144-3343-5ee5-a0dbffd209f6 has Ref:251 as its "snapshot_of" value, changing to null. INFO:root:The VM e8c6376b-49e1-422b-551a-35420f70af2a has Ref:8 as its "snapshot_of" value, changing to null. INFO:root:The VM 25eb14ab-e943-0d18-2137-c681e1191346 has Ref:11 as its "snapshot_of" value, changing to null. INFO:root:The VM 6f819166-b008-4a03-a692-fcbd75018be9 has Ref:1 as its "snapshot_of" value, changing to null. INFO:root:The VM 9d1a57e8-3531-4b55-9682-f775215866df has Ref:1 as its "snapshot_of" value, changing to null. INFO:root:The VM 0ac88f7c-d79b-281e-cf1f-a2392ba594ed has Ref:29 as its "snapshot_of" value, changing to null. INFO:root:The VM 1f3541c4-8c81-4959-9cbe-edbec9481220 has Ref:1 as its "snapshot_of" value, changing to null. INFO:root:Writing database to /var/lib/xcp/state.db INFO:root:Starting up xapi...after which it shows clean now:
./snapshot-fixer.py dry-run INFO:root:Regenerating database...However i am still getting the same error when trying to run leaked_vbs:
./leaked_vbds Traceback (most recent call last): File "./leaked_vbds", line 23, in <module> snap = xapi.VM.get_parent(snap) File "/usr/lib/python3.6/site-packages/XenAPI.py", line 317, in __call__ return self.__send(self.__name, args) File "/usr/lib/python3.6/site-packages/XenAPI.py", line 198, in xenapi_request result = _parse_result(getattr(self, methodname)(*full_params)) File "/usr/lib/python3.6/site-packages/XenAPI.py", line 292, in _parse_result raise Failure(result['ErrorDescription']) XenAPI.Failure: ['HANDLE_INVALID', 'VM', 'Ref:29'] -
RE: XCP-ng 8.3 updates announcements and testing
Is there something specific needed for the leaked_vbds script?
When i run it i get:
[09:37 xcpng-prd-01 ~]# ./leaked_vbds Traceback (most recent call last): File "./leaked_vbds", line 23, in <module> snap = xapi.VM.get_parent(snap) File "/usr/lib/python3.6/site-packages/XenAPI.py", line 317, in __call__ return self.__send(self.__name, args) File "/usr/lib/python3.6/site-packages/XenAPI.py", line 198, in xenapi_request result = _parse_result(getattr(self, methodname)(*full_params)) File "/usr/lib/python3.6/site-packages/XenAPI.py", line 292, in _parse_result raise Failure(result['ErrorDescription']) XenAPI.Failure: ['HANDLE_INVALID', 'VM', 'Ref:29'] -
RE: XCP-ng 8.3 updates announcements and testing
No issues on the same test hosts i used for the last 2 batches of updates.
-
RE: XCP-ng 8.3 updates announcements and testing
Installed on my usual test hosts. No issues so far.
-
RE: XCP-ng 8.3 updates announcements and testing
Installed on my usual hosts, one of which has an E810 and used the ICE driver, no issues so far however i am not using LACP bonding on that host.
-
RE: XCP-ng 8.3 updates announcements and testing
Installed on my usual batch of test hosts, no issues so far.
-
RE: XCP-ng 8.3 updates announcements and testing
Installed on my usual batch of test hosts, so far so good.
-
RE: XCP-ng 8.3 updates announcements and testing
@Andrew I have experienced this twice so far as well.
-
RE: XCP-ng 8.3 updates announcements and testing
@stormi Updates deployed, no issues so far.
-
RE: XCP-ng 8.3 updates announcements and testing
Updates deployed, no issues so far.
-
RE: XCP-ng 8.3 updates announcements and testing
Installed on my usual test hosts without issues. However i am not using the qcow2 disk format anywhere yet
-
RE: Xen Orchestra 6.3.2 Random Replication Failure
@florent I am using NBD for all backups yes but am not purging snapshots/usnig CBT.
Its so rare in fact that i haven't had it happen since since i made this post last week. (When i had it happen twice in 2 days). This is our production XOA it has occurred on so i wont be able to test a branch and i have never seen it happen on my sources install at home.
-
RE: XCP-ng 8.3 updates announcements and testing
Installed on a handful of test machines. Not as many as usual as im being very cautious with this one for now. Everything rebooted and VMs started ok after. Using VHD for everything currently.
-
RE: Xen Orchestra 6.3.2 Random Replication Failure
@pierrebrunet Thanks for the update. Glad to know its not something unique to our environment and you were able to track down the cause!
-
Xen Orchestra 6.3.2 Random Replication Failure
Since the XOA 6.3 release i have had a few random backup errors in an environment that has otherwise had fairly flawless backup performance for the last year. I cannot make out what exactly the error means but retrying the job allows it to succeed without issue. It is also very intermittent.
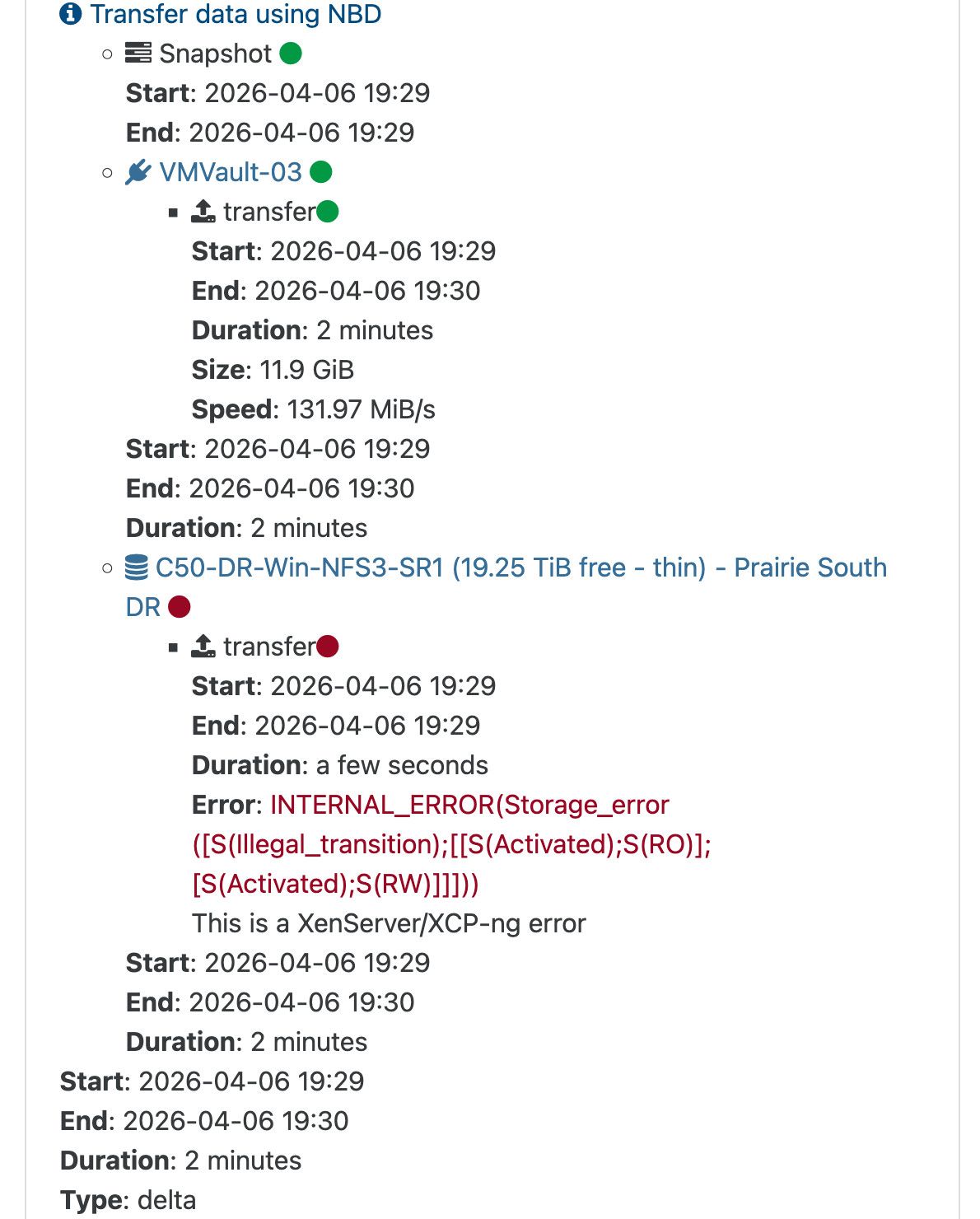
Log attached. 2026-04-07T01_00_03.075Z - backup NG.txt
If the issue persists i will submit a ticket to dive into it further but i have only had it happen 3 times since the release ofthe 6.3.x update so its hard to reproduce.
Replication target storage is a Pure C50R4 with NFS3 exports.
-
RE: XOA 6.1.3 Replication fails with "VTPM_MAX_AMOUNT_REACHED(1)"
@florent I can confirm that this fixes the issue!
-
RE: XOA 6.1.3 Replication fails with "VTPM_MAX_AMOUNT_REACHED(1)"
I created a brand new Windows 11 VM with a VTPM and Secure boot enabled and am able to reproduce this on a freshly created VM.
- Initial replication will work.
- Any follow up replications will fail with Error: VTPM_MAX_AMOUNT_REACHED(1)
- Retrying the job after the failure will succeed.
-
RE: XOA 6.1.3 Replication fails with "VTPM_MAX_AMOUNT_REACHED(1)"
I tried removing the replica chain and let it start from scratch. The initial full replica was a success but unfortunately running a follow up incremental replication job results in the same error.
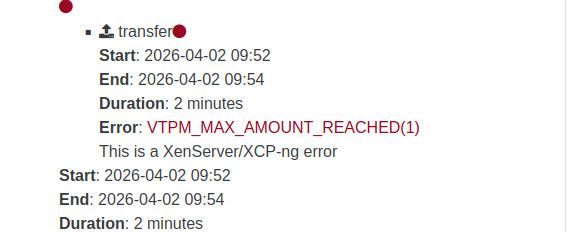
The entire transfer succeeds, it only seems to fail at the very end.
I have other VMs (Server 2022) with VTPMs that do not have this issue. The VM that is failing is Windows 11, and is the only Windows 11 VM we have running.