both fixes are now on master AND released as a patch
thank you @pedro_udifar
both fixes are now on master AND released as a patch
thank you @pedro_udifar
@pedro_udifar that is strange that we have exactly the same error, even though we should have added 28 bytes
I pushed a little debug that will log additional lines in journalctl
'will output stream ', 'stream is encrypted' and 'stream is updated '
Can you update your branch, rebuild, rerun the transfer and post the log ( with the attached values ) ?
regards
@pedro_udifar object lock works quite well with xo
it is automatically detected if the s3 user has enough privilege to see if object lock is enabled
the main point is that it won't create "cache.json.gz" files since theses files must be updated, so the backup listing is a little slower
note that XO retention should be at least 1 more than object lock . At worst you will have error , saying that XO coudn't delete an old backup
The fix is on a separated branch : fix_s3_nonencrypted_to_encrypted_xva ( PR : https://github.com/vatesfr/xen-orchestra/pull/10061 )
@pedro_udifar we have found a clue , if the destination is encrypted and the source is not
can you test this branch ? https://github.com/vatesfr/xen-orchestra/pull/10061
if you are using a xoa, we can deploy the fix if you open a support tunnel
now that I am in front of the source code , it is already getting the real size, so it should compute the right size
are the source or destination encrypted ?
Thanks for the detailed write-up, Pedro.
I'm not a backup expert, far from it. but you might be right that https://github.com/vatesfr/xen-orchestra/pull/9396 only fixed the size estimation for direct full backups, not the mirror path.
Your error is the same as the maximum size allowed one, just twelve bytes over 209715200000. Before this turns into a GitHub issue, it would help to know whether it reproduces on a fresh mirror job and whether bumping minPartSize actually cleared it, so we can be sure it's the mirror code and not the B2 remote settings.
The object storage docs list Backblaze B2 as supported (https://docs.xen-orchestra.com/xo5/object-storage-support#supported-storage-providers) but don't say much about part-size tuning.
If it's awkward to test in isolation, a mention to @Team-XO-Backend is probably the quickest route, since they own the backup job code.
The XVA checksum warnings in your second screenshot look like a separate non-blocking clean VM directory step rather than the cause.
I hope that points somewhere useful!
nice catch
and the mirror path is easier to fix . Thaks @pedro_udifar and @poddingue we will fix it asap
will it be possible to test a potential fix @pedro_udifar , since it's often specific to a provider ( and need huge VM to work )?
the new code is now in master
@Andrew working on it with @julienxovates
at least including them by default , without following them, in the archive seems doable . The change on the XO5 UI may be trickier, and we are not far to rewrite it for XO6
@Andrew good news : the lvm id/name collision is the root cause of a lot of issues of the the file restore.
I think restoring the symbolic links will be hard to secure ( a symbolic link can point anywhere in the os and the disk are mounted in the xoa as root) and quite tricky to ensure we are not bombing ourself
I think we can add them to the zip/tar as (brokenà symbolic link, but we need to look into the impact on the client side file browser
@Andrew thank
I pushed some fixes , can you retry the VM . With this config in the toml ? if it fails if will gives us more logs in journalctl
[logs]
# Display all logs matching this filter, regardless of their level
filter = 'xo:backups:RemoteAdapter'
@ravenet not directly, it's not mountable into linux
But if ( and this is a big if) we are able to make FLR more resilent, I have some next step that would expose the disks so you can mount it directly in your preferred OS or XCP , probably through webdav
we did a lot of ground work on the file restore front , and have plan to continue working on it.
What is testable and should work :
Note that, by design, the file restore is slow : each time the xoa want to read 4KB of data or even 1B we have to load a full backup block (2MB) decrypt, and inflate it ,extract the 4KB , ... . Expect 1/10 to 1/30 of your remote performance
But at least it should not crash anymore, with zip or tar restore. The worse we tested is a windows folder ( 26GB , 10 of thousands of files)
For now the fixes are in https://github.com/vatesfr/xen-orchestra/pull/9776 ( branch fix_flr ) and are expected to reach master during next week
@tsukraw multiple NBD connection will open multiple reading connection, but the writing one is always one stream per disk in incremental replication
with full replication, it's one stream for read and one for write
@acebmxer back to work
thank you for yor patience and help on this. I feel that it's not the same issue , with abrupt increase
W will try our best to also fix this one
@laszlobortel since we are generating the stream sequentially, we though that there wasn't any real world gain. Also, if my understanding is correct using one thread means we will have only one process( + xo + nbdkit-vddk) processes , and we were trying to limit the risk of zombie process locking the disks , which was far too common with the previous code
we'll do a quick test to ensure it does not beak anything and propose either a better default of a configuration option
note that this will be a concurrency per disk, so VM with a lot of disk will put more pressure on the source
also do you have a reverse proxy/ http proxy in front of xo ? it can block the bigger upload by default
@nasheayahu qcow2 disk import has been merged recently ( https://github.com/vatesfr/xen-orchestra/pull/9817 ) , but there is a caveat
the clusters in the disk must be in order to work . This is generally the case for a disk exported by any system, but not the case for a disk used in production that you want to import
where does this disk comes from ? if you have access to your SR from the outside, you can also put the qcow2 file directly , by renaming it as a valid uuid ( I think uuidgen can do this ) and putting it directly in the SR/uuid repository
@poddingue this is something that was hidden with the previous system ( same disk chains, but not shown as snapshot )
@julienxovates are you ok to not check the vm tagged as replication from this chech ?
the last rewrite of the stream processing ( spring 2025 ) focused on stability and memory footprint, and , on a standard cpu, it tops at around 300MB/s per backup job. Your benchmarks are very interesting, and they confirm most of it.
this limit was not really an issue since, in most case the xapi was limiting around 100MB/s per disk , but it will be more a more visible limit
Note that master have some fixes on the memory usage (not related to backups)
That's why we have started an internal workforce focused on performance, with all the teams from the kernel to the backups, including storage, network and xapi.
If I can brag a little :
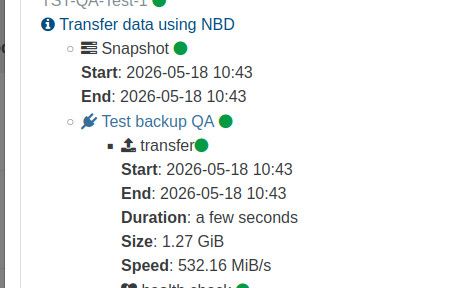
i9 , nvme disk , backup to a nvme disk in passthrough, xoa and vm are on the same host, so it's quite far from real world data, but it shows where the limit is

