Hello @poddingue , you right.
Yes i saw this article, but it was unrelated to my issue.
I agree your guess.
How can i mark the topic as Solved ?
Hello @poddingue , you right.
Yes i saw this article, but it was unrelated to my issue.
I agree your guess.
How can i mark the topic as Solved ?
Hello.
Problem Solved.
My case:
Yesterday, i removed two hosts ( host 3 & host 4 ) whith local storages SR attached ( LVM ).
In XCP-NG, i "forgot" Host 3 & host 4, the hosts from the pool, but it doesn't forge the associated SR !
But Live migrating a VM from host 1 to host 2 ( of the same pool ) bot with local SR, FAIL because there is no SR plugin attached of Local Storage 4 ( hosts 4 ) neither Local storage 3 ( host 3 ).
So, i also forget theses 2 SRs and now it's ok.
i don't understand why SR not connected to anyone can prevent migration about vm from other to other sr.
Hello.
I have this error while trying to migrate VM from a host to another host. ( same versions ).
Jul 10 10:58:06 server xapi: [debug||3148384 ||storage_utils] Got failure: checking for redirect, call was: -> SR.scan({sr:S(a2e6300f-10f2-ec61-bcfb-6a1d62a00bff);dbg:S(Async.VM.migrate_send R:afa4f5b49fd9)}), results.contents: ["No_storage_plugin_for_sr","a2e6300f-10f2-ec61-bcfb-6a1d62a00bff"]
Jul 10 10:58:06 server xapi: [debug||3148384 ||storage_utils] Not a redirect: -> SR.scan({sr:S(a2e6300f-10f2-ec61-bcfb-6a1d62a00bff);dbg:S(Async.VM.migrate_send R:afa4f5b49fd9)})
Jul 10 10:58:06 server xapi: [error||3148384 ||storage_interface] Storage_error ([S(No_storage_plugin_for_sr);S(a2e6300f-10f2-ec61-bcfb-6a1d62a00bff)]) (File "ocaml/xapi-idl/storage/storage_interface.ml", line 451, characters 49-56)
Jul 10 10:58:06 server xapi: [error||3148384 ||storage_migrate] Storage_migrate.MigrateLocal.prepare Caught error Storage_error ([S(No_storage_plugin_for_sr);S(a2e6300f-10f2-ec61-bcfb-6a1d62a00bff)]) while preparing for SXM
Jul 10 10:58:06 server xapi: [error||3148384 ||storage_migrate] Caught Storage_error ([S(Migration_preparation_failure);S(Storage_error ([S(No_storage_plugin_for_sr);S(a2e6300f-10f2-ec61-bcfb-6a1d62a00bff)]))]) during SXM:
Jul 10 10:58:06 server xapi: [error||3148384 ||task_server] Task 3 failed; Storage_error ([S(Internal_error);S(Storage_error ([S(Migration_preparation_failure);S(Storage_error ([S(No_storage_plugin_for_sr);S(a2e6300f-10f2-ec61-bcfb-6a1d62a00bff)]))]))])
Jul 10 10:58:06 server xapi: [debug||3148384 ||storage] TASK.signal 3 = ["Failed",["Internal_error","Storage_error ([S(Migration_preparation_failure);S(Storage_error ([S(No_storage_plugin_for_sr);S(a2e6300f-10f2-ec61-bcfb-6a1d62a00bff)]))])"]]
Do you know what No_storage_plugin_for_sr mean ?
It's a simple local storage
Hello there ")
I start to use slowly XO6 since many features was added.
But i observe this:
I have a VM with 3 backups jobs associated:
But in the UI, i see this:
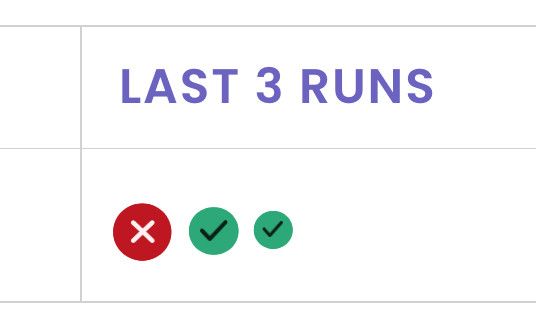
The jobs should be order from the "most recent" to "older one" ( or vice versa, i don"t have opinion on it ).
But showing the fail as the first make us thinks that the last jobs fail, that's not the case.
I should have:

Thank you
Hello,
All is in the title

Is this normal ?
Thanks !
Hello,
To gave more details abouit my case:
AMD EPYC 4464P 12-Core Processor6.12.0-211.18.1.el10_2.x86_64Hello,
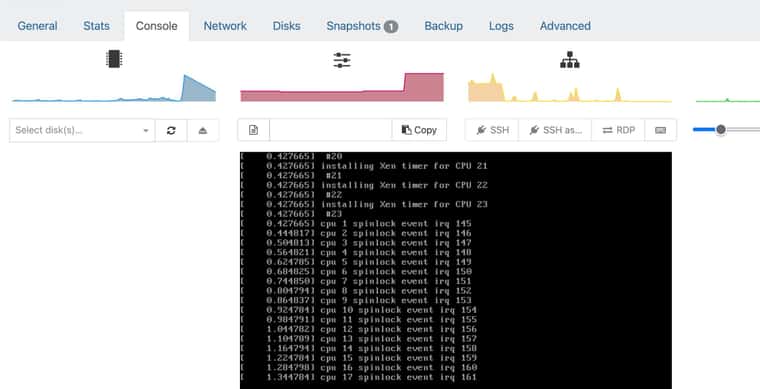
When i boot a Rocky Linux 10 with the latest kernel, it's very slow on cpu XXX spinlock event irq.
Someone have the same issue ?
Thanks !
@olivierlambert I added this feature request in the backlog regarding RPU improvements.
Hello,
Thanks all !
Totally agree with @poddingue , be able to exclude VM which has:
Could be a great option !
Hello @McHenry .
Yes but no, once the snapshot is exported, the previous one must be cleaned on local.
Best regards,
Hello,
I see also this behavior which is "new" since few weeks.
Previously, when a backup start:
Now, the old snapshots are not deleted anymore which can lead easily to some disk full.
Even with a retention of 1, the problem is present.
I observe this only in Backup job, not DR/CR job.
I just updated my XO to latest version, i will see if the issue is fixed.
Hello,
In the post about XCP-NG 9.0, there was a discussion about Storage Domain Virtual machines, as i understood, the project was abandonned, but the concept is still doable without this implementation.
https://xcp-ng.org/forum/post/102311
On each of my hosts, i have a VM dedicated for ceph which mount the PCI devices ( NVME disks ).
Everything works like a charm !
But the RPU is not available due to the VMS which have PCI attached resources.
Is it possible to exclude VMS from RPU and make it shutdown before the upgrade ?
something like you done to exclude Security warning about old windows guest tools.
This would be very great
Hello @nikade.
I agree but this is my case.
Try to migrate a running VM: error 500
Try to migrate an halted VM: error 500.
Warm migrate: It's okay.
I don't understand myself the difference except it doesn't transfer the "VM" but recreate the VM and import the VDI, ( so , the same things ), but there may be a light difference. I don't know how the "warm migration" works under the hood
Hello,
I was able to perform "Warm" migrate from either the slave or the master.
Yes the master was rebooted.
@henri9813 Did you reboot the master after it was updated? If yes, I think you should be able to migrate back the VM's to the master, and then continue patcting the rest of the hosts.
No, i would migrate back vm from MASTER (updated ) to slave ( not updated ), but wasn't working.
Only warm migrations works.
Hello, @Danp
My pool is in upgrade, not all nodes are updated.
I tried both:
Thanks !
I have an updated pool.
I'm evacuating an host for update to another pool.
But the operation fail, and remains in the XO tasks
VM metadata import (on new-hypervisor) 0%
and in the VM.migrate api call detail.
vm.migrate
{
"vm": "30bb4942-c7fd-a3b3-2690-ae6152d272c5",
"mapVifsNetworks": {
"7e1ad49f-d4df-d9d7-2a74-0d00486ae5ff": "b3204067-a3fd-bd19-7214-7856e637d076"
},
"migrationNetwork": "e31e7aea-37de-2819-83fe-01bd33509855",
"sr": "3070cc36-b869-a51f-38ee-bd5de5e4cb6c",
"targetHost": "36a07da2-7493-454d-836d-df8ada5b958f"
}
{
"code": "INTERNAL_ERROR",
"params": [
"Http_client.Http_error(\"500\", \"{ frame = false; method = GET; uri = /export_metadata?export_snapshots=true&ref=OpaqueRef:75e166f7-5056-a662-f7ff-25c09aee5bec; query = [ ]; content_length = [ ]; transfer encoding = ; version = 1.0; cookie = [ (value filtered) ]; task = ; subtask_of = OpaqueRef:9976b5f2-3381-e79e-a6dd-0c7a20621501; content-type = ; host = ; user_agent = xapi/25.33; }\")"
],
"task": {
"uuid": "9c87e615-5dca-c714-0c55-5da571ad8fa5",
"name_label": "Async.VM.assert_can_migrate",
"name_description": "",
"allowed_operations": [],
"current_operations": {},
"created": "20260131T08:16:14Z",
"finished": "20260131T08:16:14Z",
"status": "failure",
"resident_on": "OpaqueRef:37858c1b-fa8c-5733-ed66-dcd4fc7ae88c",
"progress": 1,
"type": "<none/>",
"result": "",
"error_info": [
"INTERNAL_ERROR",
"Http_client.Http_error(\"500\", \"{ frame = false; method = GET; uri = /export_metadata?export_snapshots=true&ref=OpaqueRef:75e166f7-5056-a662-f7ff-25c09aee5bec; query = [ ]; content_length = [ ]; transfer encoding = ; version = 1.0; cookie = [ (value filtered) ]; task = ; subtask_of = OpaqueRef:9976b5f2-3381-e79e-a6dd-0c7a20621501; content-type = ; host = ; user_agent = xapi/25.33; }\")"
],
"other_config": {},
"subtask_of": "OpaqueRef:NULL",
"subtasks": [],
"backtrace": "(((process xapi)(filename ocaml/libs/http-lib/http_client.ml)(line 215))((process xapi)(filename ocaml/libs/http-lib/http_client.ml)(line 228))((process xapi)(filename ocaml/libs/http-lib/xmlrpc_client.ml)(line 375))((process xapi)(filename ocaml/libs/xapi-stdext/lib/xapi-stdext-pervasives/pervasiveext.ml)(line 24))((process xapi)(filename ocaml/libs/xapi-stdext/lib/xapi-stdext-pervasives/pervasiveext.ml)(line 39))((process xapi)(filename ocaml/xapi/importexport.ml)(line 313))((process xapi)(filename ocaml/libs/xapi-stdext/lib/xapi-stdext-pervasives/pervasiveext.ml)(line 24))((process xapi)(filename ocaml/libs/xapi-stdext/lib/xapi-stdext-pervasives/pervasiveext.ml)(line 39))((process xapi)(filename ocaml/libs/xapi-stdext/lib/xapi-stdext-pervasives/pervasiveext.ml)(line 24))((process xapi)(filename ocaml/libs/xapi-stdext/lib/xapi-stdext-pervasives/pervasiveext.ml)(line 39))((process xapi)(filename ocaml/xapi/xapi_vm_migrate.ml)(line 1920))((process xapi)(filename ocaml/xapi/message_forwarding.ml)(line 2551))((process xapi)(filename ocaml/xapi/rbac.ml)(line 229))((process xapi)(filename ocaml/xapi/rbac.ml)(line 239))((process xapi)(filename ocaml/xapi/server_helpers.ml)(line 78)))"
},
"message": "INTERNAL_ERROR(Http_client.Http_error(\"500\", \"{ frame = false; method = GET; uri = /export_metadata?export_snapshots=true&ref=OpaqueRef:75e166f7-5056-a662-f7ff-25c09aee5bec; query = [ ]; content_length = [ ]; transfer encoding = ; version = 1.0; cookie = [ (value filtered) ]; task = ; subtask_of = OpaqueRef:9976b5f2-3381-e79e-a6dd-0c7a20621501; content-type = ; host = ; user_agent = xapi/25.33; }\"))",
"name": "XapiError",
"stack": "XapiError: INTERNAL_ERROR(Http_client.Http_error(\"500\", \"{ frame = false; method = GET; uri = /export_metadata?export_snapshots=true&ref=OpaqueRef:75e166f7-5056-a662-f7ff-25c09aee5bec; query = [ ]; content_length = [ ]; transfer encoding = ; version = 1.0; cookie = [ (value filtered) ]; task = ; subtask_of = OpaqueRef:9976b5f2-3381-e79e-a6dd-0c7a20621501; content-type = ; host = ; user_agent = xapi/25.33; }\"))
at XapiError.wrap (file:///etc/xen-orchestra/packages/xen-api/_XapiError.mjs:16:12)
at default (file:///etc/xen-orchestra/packages/xen-api/_getTaskResult.mjs:13:29)
at Xapi._addRecordToCache (file:///etc/xen-orchestra/packages/xen-api/index.mjs:1078:24)
at file:///etc/xen-orchestra/packages/xen-api/index.mjs:1112:14
at Array.forEach (<anonymous>)
at Xapi._processEvents (file:///etc/xen-orchestra/packages/xen-api/index.mjs:1102:12)
at Xapi._watchEvents (file:///etc/xen-orchestra/packages/xen-api/index.mjs:1275:14)"
}
My XO is up to date.
I already update the master, i'm processing the slave.
But neither the master ( updated ) nor the slave ( not updated ) can migrate VM to an updated pool.
Do you have an idea ?
Hello @florent ,
You mean, "check" right ? because if it's doesn't check, the job is finished before the merge and the merge run in background in xen orchestra.
Best regards,
Hello, @Pilow
Thanks for the tips !
But it would be great to see it in the Task UI to find more easily the trick.
Hello,
Sometimes, i have on some jobs ( which run every 4 hours ).
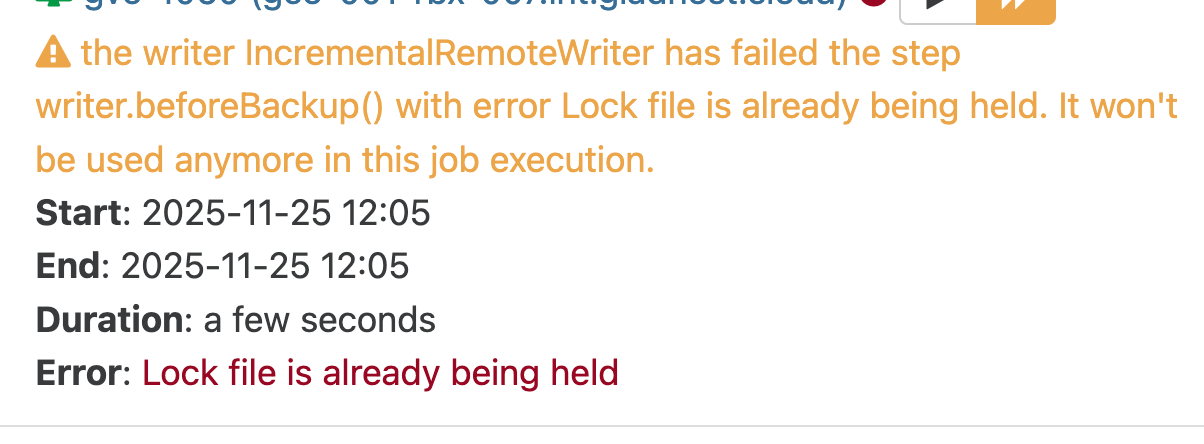
Howerver, the previous job is finished in success

Is it possible that has a relation with the mergeWorker of backups which could be running ? if it doesn't finished his operations ?
Example of logs:
xen-orchestra | 2025-11-27T00:44:43.487Z xo:backups:mergeWorker INFO merge in progress {
xen-orchestra | done: 2057,
xen-orchestra | parent: '/xo-vm-backups/f37e259d-beaa-7617-e6f1-be814f21e056/vdis/29e0185e-2f67-44d4-bb9e-ee2a772e2543/b09c0230-219f-4ddf-8e19-bfed1464014f/20251126T070610Z.vhd',
xen-orchestra | progress: 25,
xen-orchestra | total: 8128
xen-orchestra | }
Is it possible to have this in the XO Tasks sections ? it's interessant to see this.
Best regards