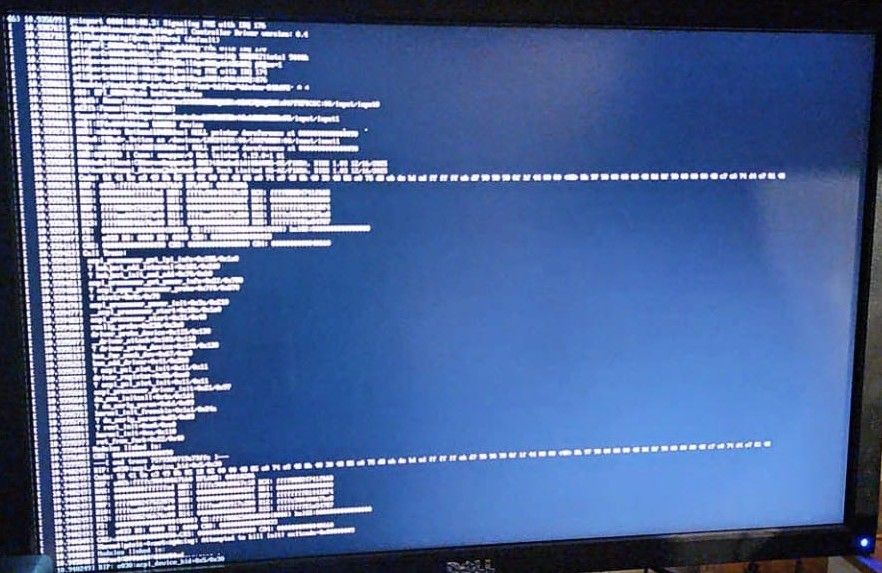
The PoD crash half is known: https://xcp-ng.org/forum/topic/10179/rockylinux-vm-s-random-reboots hit the same p2m_pod_demand_populate line, and the answer there was closing the gap between static-max and dynamic-max, with the background at https://xenproject.org/blog/ballooning-rebooting-and-the-feature-youve-never-heard-of/ .
The guest tools angle I have not seen reported before, and the 13-second repro makes it hard to wave off. What gives me pause is https://xcp-ng.org/forum/topic/11955/memory-ballooning-dmc-broken-since-xcp-ng-8.3-january-2026-patches, where the Vates Rust guest agent stopped re-arming ballooning after live migration and the Citrix utilities were the ones behaving.
Different guest OS and probably a different mechanism, so it may well be unrelated, but it makes me wary of reading your result as "Citrix tools do not reclaim" rather than the narrower "on Windows under PoD pressure".
I could not find an existing issue for either of your XO asks, so both look worth filing at vatesfr/xen-orchestra, and they stand on their own regardless of where the tools question lands.
Whether the XO 6 creation form already treats the memory side differently, I do not know, and I would rather say that than guess.