Biggen At the moment, xcp-ng center provides some better views and overviews not yet available in XO.. Hoping next major version fixes this ")
Best posts made by Forza
-
RE: [WARNING] XCP-ng Center shows wrong CITRIX updates for XCP-ng Servers - DO NOT APPLY - Fix released
-
RE: Best CPU performance settings for HP DL325/AMD EPYC servers?
Sorry for spamming the thread.
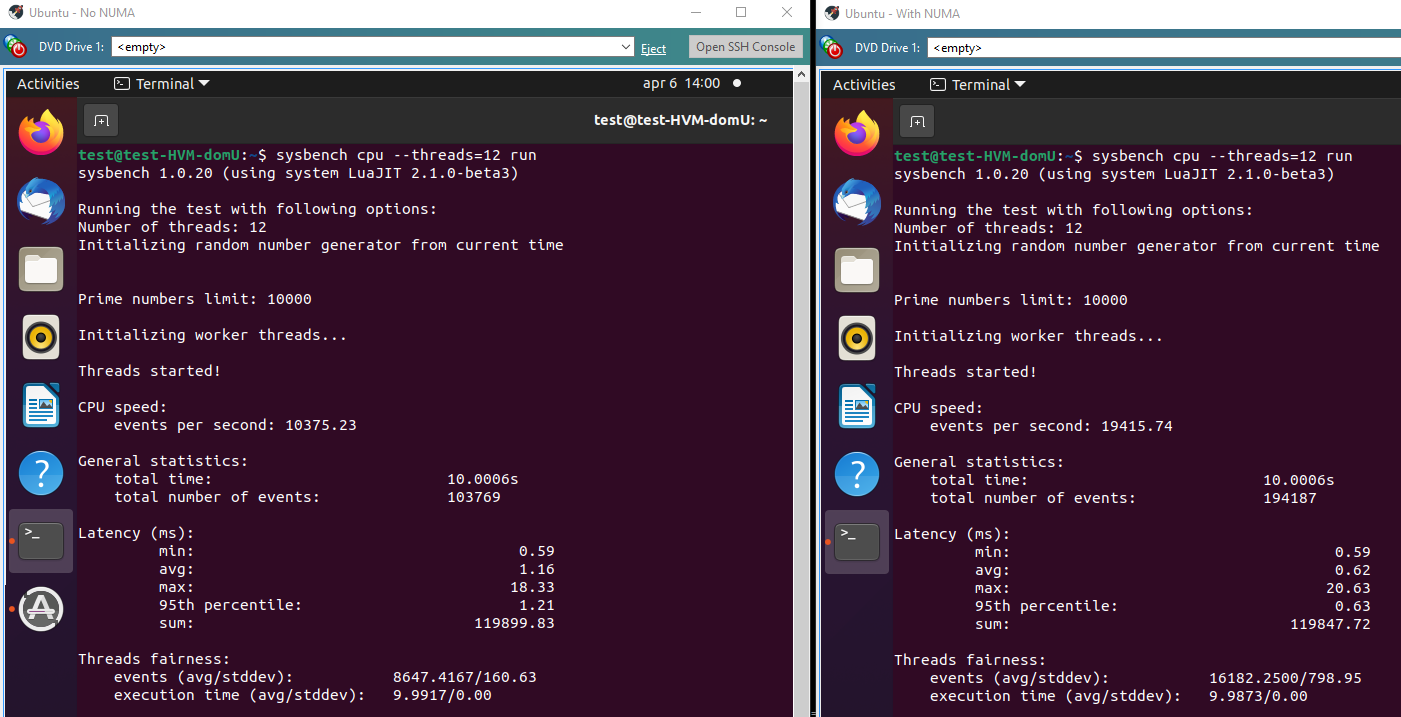
I have two identical servers (srv01 and srv02) with AMD EPYC 7402P 24 Core CPUs. On srv02 I enabled the
LLC as NUMA Node.I've done some quick benchmarks with
Sysbenchon Ubuntu 20.10 with 12 assigned cores. Command line:sysbench cpu run --threads=12It would seem that in this test the NUMA option is much faster, 194187 events vs 103769 events. Perhaps I am misunderstanding how sysbench works?
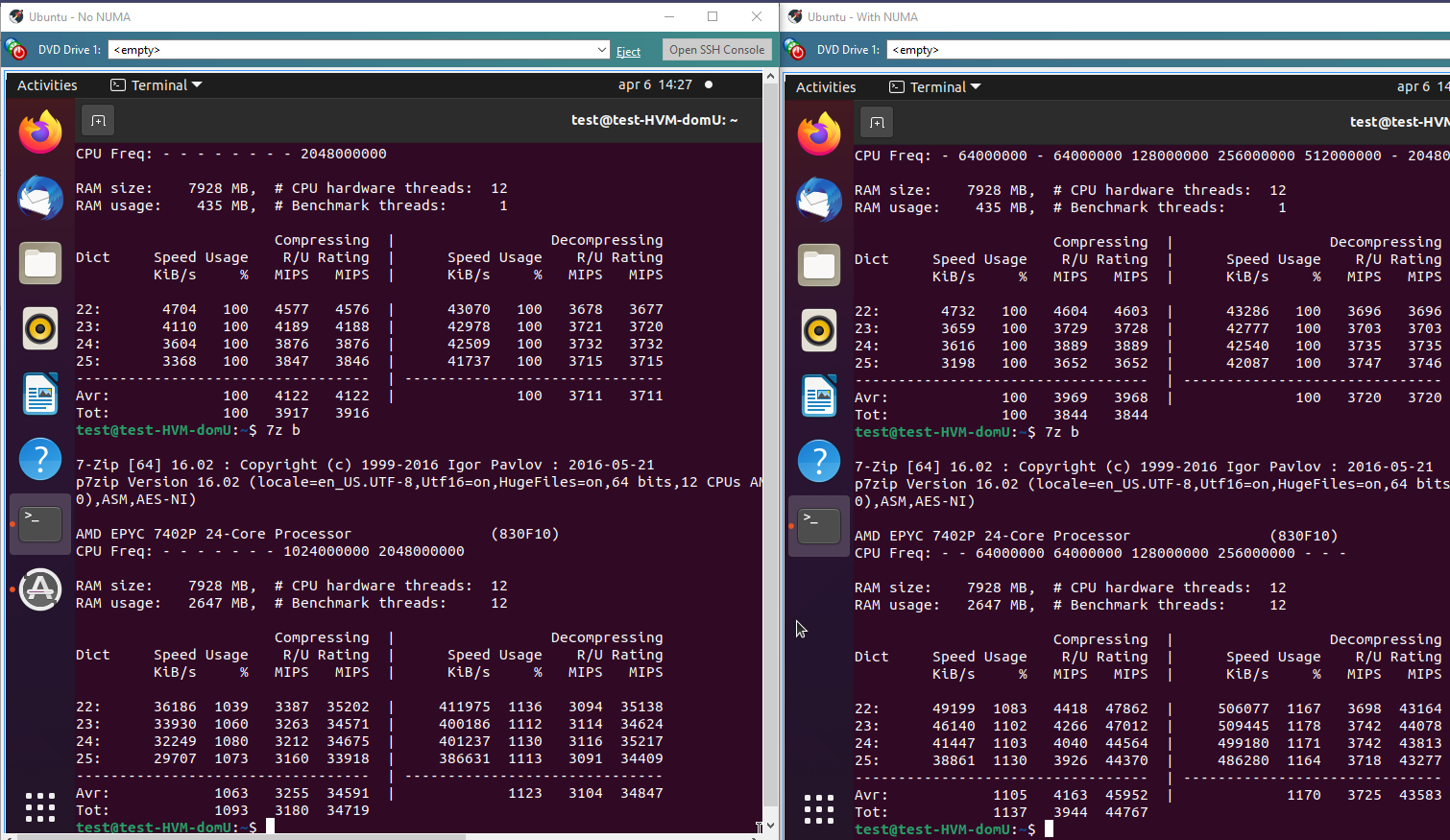
With 7-zip the gain is much less, but still meaningful. A little slower in single-threaded performance but quite a bit faster in multi-threaded mode.
-
RE: Host stuck in booting state.
Problem was a stale connection with the NFS server. A reboot of the NFS server fixed the issue.
-
RE: Restoring a downed host ISNT easy
XCPRocks said in Restoring a downed host ISNT easy:
So, we had a host go down (OS drive failure). No big deal right? According to instructions, just reinstall XCP on a new drive, jump over into XOA and do a metadata restore.
Well, not quite.
First during installation, you really really must not select any of the disks to create an SR as you could potentially wipe out an SR.
Second, you have to do the sr-probe and sr-introduce and pbd-create and pbd-plug to get the SRs back.
Third, you then have to use XOA to restore the metadata which according to the directions is pretty simple looking. According to: https://xen-orchestra.com/docs/metadata_backup.html#performing-a-restore
"To restore one, simply click the blue restore arrow, choose a backup date to restore, and click OK:"
But this isn't quite true. When we did it, the restore threw an error:
"message": "no such object d7b6f090-cd68-9dec-2e00-803fc90c3593",
"name": "XoError",Panic mode sets in... It can't find the metadata? We try an earlier backup. Same error. We check the backup NFS share--no its there alright.
After a couple of hours scouring the internet and not finding anything, it dawns on us... The object XOA is looking for is the OLD server not a backup directory. It is looking for the server that died and no longer exists. The problem is, when you install the new server, it gets a new ID. But the restore program is looking for the ID of the dead server.
But how do you tell XOA, to copy the metadata over to the new server? It assumes that you want to restore it over an existing server. It does not provide a drop down list to pick where to deploy it.
In an act of desperation, we copied the backup directory to a new location and named it with the ID number of the newly recreated server. Now XOA could restore the metadata and we were able to recover the VMs in the SRs without issue.
This long story is really just a way to highlight the need for better host backup in three ways:
A) The first idea would be to create better instructions. It ain't nowhere as easy as the documentation says it is and it's easy to mess up the first step so bad that you can wipe out the contents of an SR. The documentation should spell this out.
B) The second idea is to add to the metadata backup something that reads the states of SR to PBD mappings and provides/saves a script to restore them. This would ease a lot of the difficulty in the actual restoring of a failed OS after a new OS can be installed.
C) The third idea is provide a dropdown during the restoration of the metadata that allows the user to target a particular machine for the restore operation instead of blindly assuming you want to restore it over a machine that is dead and gone.
I hope this helps out the next person trying to bring a host back from the dead, and I hope it also helps make XOA a better product.
Thanks for a good description of the restore process.
I was wary of the metadata-backup option. It sounds simple and good to have, but as you said it is in no way a comprehensive restore of a pool.
I'd like to add my own oppinion here. A full pool restore, including network, re-attaching SRs and everything else that is needed to quickly get back up and running. Also a restore pool backup should be available on the boot media. It could look for a NFS/CIFS mount or a USB disk with the backup files on. This would avoid things like issues with bonded networks not working.
-
RE: Remove VUSB as part of job
Might a different solution be to use a USB network bridge instead of direct attached USB? Something like this https://www.seh-technology.com/products/usb-deviceserver/utnserver-pro.html (There are different options available)... We use my-utn-50a with hardware USB keys and it has shown to be very reliable over the years.
-
RE: Citrix or XCP-ng drivers for Windows Server 2022
dinhngtu Thank you. I think it is clear for me now.
The docs at https://xcp-ng.org/docs/guests.html#windows could be improved to cover all three options but also to be a little more concise to make it easier to read.
-
RE: I/O errors on file restore
I re-checked again but the issue is unfortunately not resolved. It does not happen on all VMs and files, so maybe there is something wrong somehow in the VDI?
-
RE: ZFS for a backup server
Looks like you want disaster recovery option. It creates a ready-to-use VM on a separate XCP-ng server. If your main server fails you can start the vm directly off the second server.
In any case, backups can be restored with XO to any server and storage available in XCP-ng.
-
RE: Need some advice on retention
rtjdamen you could simply make two backup jobs, one for daily backups and one for monthly backups.
-
RE: All NFS remotes started to timeout during backup but worked fine a few days ago
Since the nfs shares can be mounted on other hosts, I'd guess a fsid/clientid mismatch.
In the share, always specify fsid export option. If you do not use it, the nfs server tries to determine a suitable id from the underlying mounts. It may not always be reliable, for example after an upgrade or other changes. Now, if you combine this with a client that uses
hardmount option and the fsid changes, it will not be possible to recover the mount as the client keeps asking for the old id.Nfs3 uses rpcbind and nfs4 doesn't, though this shouldn't matter if your nfs server supports both protocols. With nfs4 you should not export the same directory twice. That is do not export the root directory /mnt/datavol if /mnt/datavol/dir1 and /mnt/datavol/dir2 are exported.
So to fix this, you can adjust your exports (fsid, nesting) and the nfs mount option (to soft) , reboot the nfs server and client and see if it works.
Latest posts made by Forza
-
RE: Xen ERMS Patch - Call for performance testing
Would be very interesting to see the performance on EPYC systems.
-
RE: Live Migration Very Slow
olivierlambert aha, I misinderstood. Should I open another topic or perhaps a support ticket?
-
RE: ACPI Error: SMBus/IPMI/GenericSerialBus
dinhngtu Yes, looks like it. I stopped Netdata and the problem went away. But it is strange it started after the latest set of updates.
-
RE: Live Migration Very Slow
Hi, sorry for revisiting an older topic, but we have the same issue with slow VM migration. We changed from 2x1G to 2x10G network, but the migration performance from one host's local SR to another host local SR is not much improved.
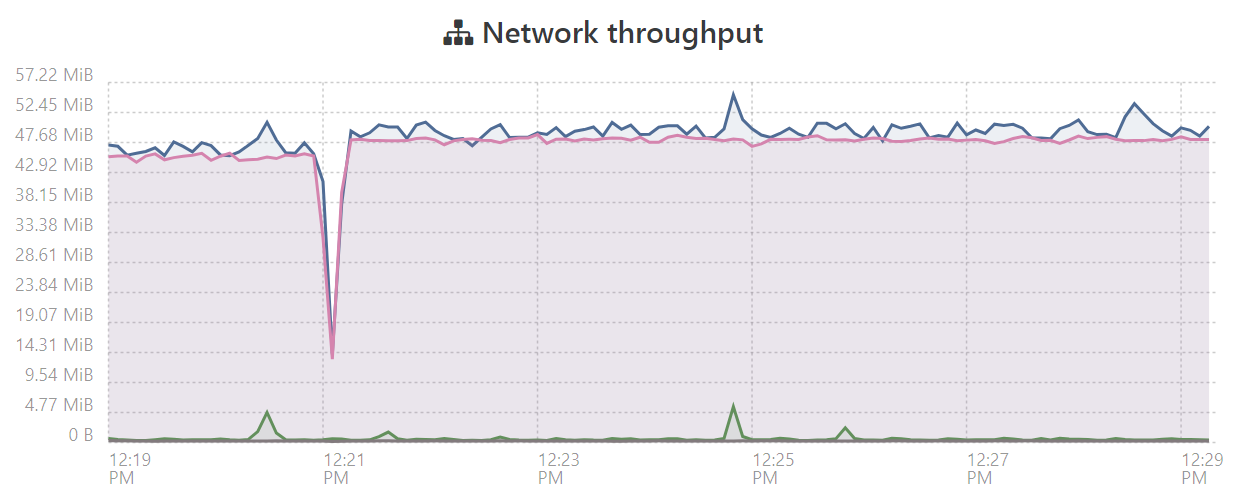
Using XCP-ng 8.2.1 with up-to-date patches. Local storage on both hosts is SSD RAID1, ext4.
It would be very good if we could improve this situation. Currently we are seeing only 5% network utilisation.
-
RE: ACPI Error: SMBus/IPMI/GenericSerialBus
Found a link with similar issue and a fix by disabling ACPI power monitoring. Would that have any impact in XCP-ng - i.e. is this feature used by anything?
https://www.suse.com/support/kb/doc/?id=000017865
EDIT: Perhaps it is netdata. I will disable netdata and check again.
-
ACPI Error: SMBus/IPMI/GenericSerialBus
With the latest XCP-ng updates, I am getting dmesg errors. They appeared immediately after
yum updatefinished, and remain after reboot. Anyone seen this before and knows what to do?[Mar19 10:20] ACPI Error: SMBus/IPMI/GenericSerialBus write requires Buffer of length 66, found length 32 (20180810/exfield-393) [ +0.000009] ACPI Error: Method parse/execution failed \_SB.PMI0._PMM, AE_AML_BUFFER_LIMIT (20180810/psparse-516) [ +0.000008] ACPI Error: AE_AML_BUFFER_LIMIT, Evaluating _PMM (20180810/power_meter-338) [ +0.999960] ACPI Error: SMBus/IPMI/GenericSerialBus write requires Buffer of length 66, found length 32 (20180810/exfield-393) [ +0.000008] ACPI Error: Method parse/execution failed \_SB.PMI0._PMM, AE_AML_BUFFER_LIMIT (20180810/psparse-516) [ +0.000008] ACPI Error: AE_AML_BUFFER_LIMIT, Evaluating _PMM (20180810/power_meter-338) [ +0.999961] ACPI Error: SMBus/IPMI/GenericSerialBus write requires Buffer of length 66, found length 32 (20180810/exfield-393) [ +0.000009] ACPI Error: Method parse/execution failed \_SB.PMI0._PMM, AE_AML_BUFFER_LIMIT (20180810/psparse-516) [ +0.000008] ACPI Error: AE_AML_BUFFER_LIMIT, Evaluating _PMM (20180810/power_meter-338)This is a HPE DL325 Gen10 EPYC system with XCP-ng 8.2.1.
-
RE: Epyc VM to VM networking slow
olivierlambert said in Epyc VM to VM networking slow:
No obvious solution yet, it's likely due to an architecture problem on AMD, because of CCDs and how CPUs are made. So the solution (if there's any) will be likely a sum of various small improvements to make it bearable.
I'm going to Santa Clara to discuss that with AMD directly (among other things).
Do we have other data to back this? The issue is not really common outside of Xen. I do hope some solution comes out from the meeting with AMD.
-
RE: Misleading status in VM->Backup screen
olivierlambert Nice
Thanks for the feedback. -
RE: Misleading status in VM->Backup screen
DustinB Yes, I remember it being like this. However, it would be nice if it wasn't
So I'd see this as a feature request. -
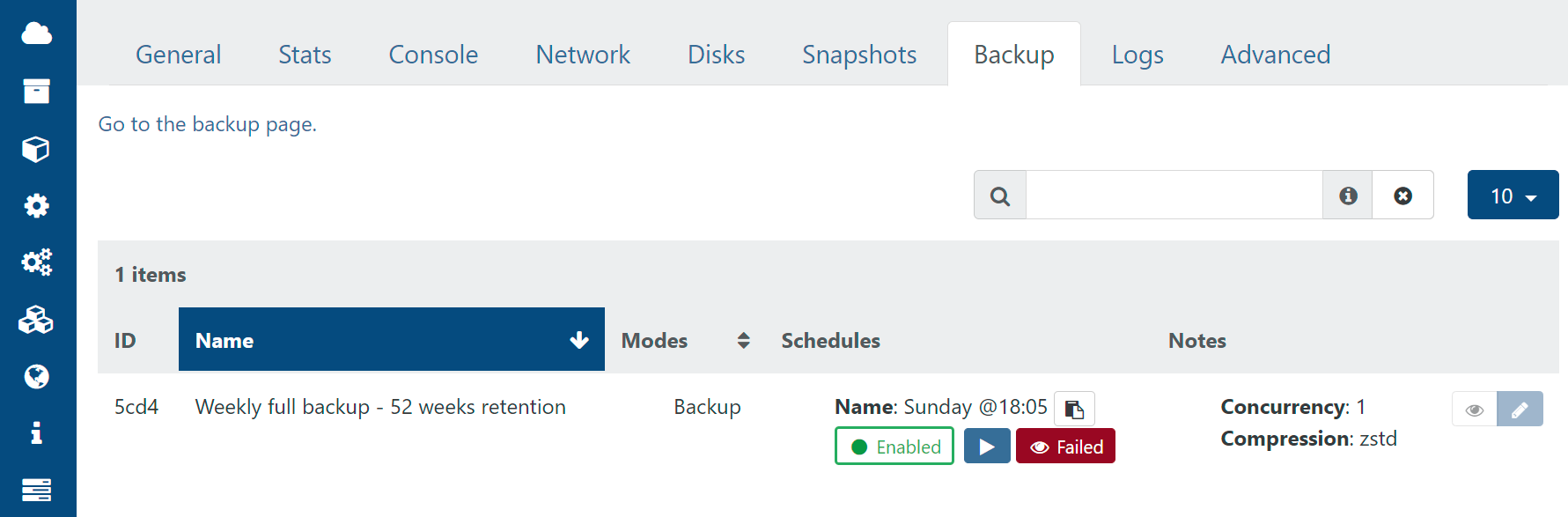
Misleading status in VM->Backup screen
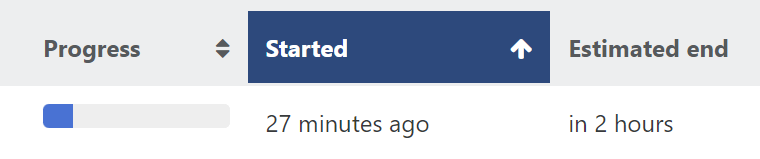
When looking at the VM->Backup screen, the status (FAILED/OK) is for the Backup as a whole, and not specifically the VM itself, which is a little misleading.
In this screenshot we see Failed, but this specific VM was in fact backed up properly.
Using XOA Premium, Stable channel.