Best posts made by JamfoFL
-
RE: No more options for export
-
RE: Xen Orchestra from Sources unreachable after applying XCPng Patch updates
@CodeMercenary Sorry I have not replied to you sooner. Unfortunately, the timing of this issue was bad! I was in the process of moving and had to tear down my demo equipment for the move and have just now reassembled everything and got back up-and-running.
I cannot say what the issue was. However, when I got everything up and running today, just for giggles I started the Orchestra server back up and ran through the usual update process to see if maybe, just maybe, one of the Commits between when I took the servers down three weeks ago and today would fix the issue. Lo and behold, it did. After applying the latest Commits (currently fb0e1) I was finally able to get back into Orchestra normally. Everything appears to be running exactly as it should be now.
I have no explanation; other than maybe something went sideways when I last applied Commits that somehow went "sideways" and was corrected by this latest application.
The really weird thing is nothing has changed when I check services, like @knightjoel mentioned. Even though EVERYTHING is now working properly in Orchestra, I still see the same messages when I check the Orchestra service status:
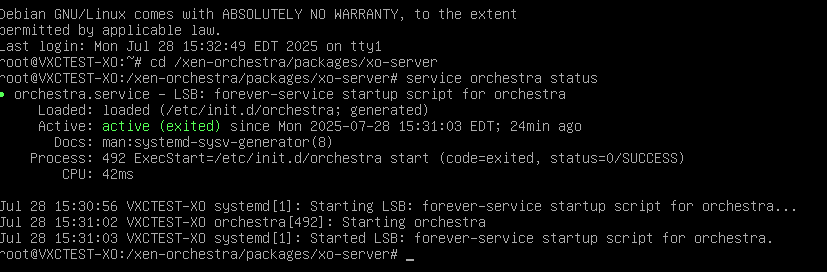
So... I don't know what is happening, exactly... other than everything is working again beautifully!
-
RE: Lots of performance alerts after upgrading XO to commit aa490
@ph7 I'm seeing the same thing as you, where I'm getting a mismatch between the server that is sending out the alert and then ending the alert. Just like you, it is actually the XO server that is truly the one that should be alerting. The second server (and it's always the same second server) is NOT having any issues with CPU or memory usage but is being drug into the alerts for some strange reason.
I'm currently on Commit 2e8d3 running Xen from sources. Yes, I know I'm 5 commits behind right now, and will update as soon as I finish this message. However, this issue has been going on for me for some time now and when I saw others with the same issue, I figured I'd add to the chain.
One other thing that happed around the same time this issue started... it seems the Average Length value for alerts are being ignored, or are at least being handled differently than they had previously. For example, I have my CPU alert set to trip if it exceeds 90% for over 600 seconds. Before the issue started, if I had a long running backup, my CPU would go over 90% and could sometimes stay there for an hour or more. During that period, I would get a single alert after the CPU was over 90% for that period of time and then Xen was "smart" enough that it would keep an eye on the average, so a brief couple second dip below 90% would NOT send out an "end of alert" and then a second "alert" message when the CPU went over 90% once again. This is not happening anymore... if the CPU spikes over my 90% threshold, I get an almost immediate alert message. The instant the CPU goes below the 90% threshold, I get an immediate end of alert message. If threshold goes back over 90%, even a few seconds later, I get yet another alert message.
This has had the effect where instead of getting a single message that spans the duration of the time the threshold is exceeded, where brief dips below were ignored if they were only a few seconds long, I am now getting an alert/end of alert/alert sequence for every seconds-long dip in CPU usage. Last night, for example, I received over 360 alert e-mails because of this, with many happening within seconds:
So... just confirming what @ph7 has been seeing... alerts are sending out from one server and a second sends the end-of-alerts, and for some reason the ability of Xen to average the alerts over the selected period of time so messages aren't sent out with every single seconds-long dip below the threshold is no longer working, as well.
Thanks!
-
RE: FYI - Applying 11/3/2022 and 11/4/2022 Commits in XO from Sources
@julien-f I just ran a "yard build" this morning, and other than still seeing the chunk error message:
(!) Some chunks are larger than 500 KiB after minification. Consider: - Using dynamic import() to code-split the application - Use build.rollupOptions.output.manualChunks to improve chunking: https://rollupjs.org/guide/en/#outputmanualchunks - Adjust chunk size limit for this warning via build.chunkSizeWarningLimit.Everything else ran fine... no errors or OOM issues.
-
RE: Error: couldn't instantiate any remote
@alcaraz73 @screame1 @AtaxyaNetwork @florent @Danp @olivierlambert I know I'm late back to the party, but just got back into our office after Hurricane Ian. Thanks to all for your well wishes... I was very fortunate to come out with no damage, and was only without power for about 12 hours.
Now that I'm back, I also applied the fixes here (and updated to the latest commit) and can confirm continuous replication is working like a champ.
Thanks to everyone involved for the help!
-
RE: Error: couldn't instantiate any remote
@Danp Current commit is 3d3b6.
xo-server: 5.103.0
xo-web: 5.104.0Yes... as I had mentioned, everything worked until I updated yesterday at around 3:50 PM. I noticed there were five different commits that were released yesterday, and the one you linked to is one of those. So, as I figured, one of the commits from yesterday "broke" the ability to run continuous replications.
Now that it looks like you've focused on a cause, I'm sure it's only a matter of time until a new commit is published to fix the issue. Once it's released, I'll get it installed and, hopefully, we can put this behind us.
Thanks!!
-
RE: All drop-down options are empty
I just wanted to post an update as of Monday, February 24, 2025...
I updated to Commit f18b0 and that seems to have fixed the issue. All of the dropdown options that were missing in the above screen shots, as well as many others, are all back and responding normally once again. So, it looks like the issue has been addressed and operations have returned to normal.
The only oddity I now see after all of that is when I run yarn after pulling the updates, I receive an error message that the expected version of Node is now v20. I upgraded to v20, but it seems that the backup portion of Xen still needs v18... so be sure to keep both on the system or things will break. I have both v18 and v20 installed and running, with v20 set as default.
Other than that little oddity, it seems everything else is doing everything it should be doing!
Thanks to the excellent Vates teams for getting everything back on track.
-
RE: All drop-down options are empty
@probain Thanks for the update... I will monitor that ticket, as well.
-
RE: Orchestra logon screen is messed up after update
@olivierlambert I would agree... one of those odd glitches that occurred during the build process that corrected itself on a second run.
Thanks for everyone's help... please go ahead and close this out!
-
RE: continuous replication problems
I just wanted to chime in that I was having the same issue after updating to the latest commit earlier today, 1b5157e9a7a7ba9a49ebc9484737c34ef3da95ed.
I rolled back to my previous commit (granted, it's a bit of an older one as I hadn't updated since last week) and the CR backups started working again perfectly.
In my case, both XCP-ng hosts are on the same subnet.
So, something seems to have broken CR backups between last week and today. Fortunately, rolling-back got everything working again.
If there's anything I can do on my end that might help, just let me know!
Latest posts made by JamfoFL
-
RE: Xen Orchestra from Sources unreachable after applying XCPng Patch updates
@CodeMercenary Glad it worked!
I just noticed that in the couple weeks since this happened, a new set of Pool Patches was available, so I ran through the usual process to update those and had no issues at all. This time, everything went smoothly, just as it has for the entire time I've had this lab up and running.
So, chalk this up to one of those weird glitches you're bound to see when you use any technology long enough.
As far as I'm concerned, the issue has been resolved. Please feel free to close out the issue.
-
RE: Xen Orchestra from Sources unreachable after applying XCPng Patch updates
@CodeMercenary Sorry I have not replied to you sooner. Unfortunately, the timing of this issue was bad! I was in the process of moving and had to tear down my demo equipment for the move and have just now reassembled everything and got back up-and-running.
I cannot say what the issue was. However, when I got everything up and running today, just for giggles I started the Orchestra server back up and ran through the usual update process to see if maybe, just maybe, one of the Commits between when I took the servers down three weeks ago and today would fix the issue. Lo and behold, it did. After applying the latest Commits (currently fb0e1) I was finally able to get back into Orchestra normally. Everything appears to be running exactly as it should be now.
I have no explanation; other than maybe something went sideways when I last applied Commits that somehow went "sideways" and was corrected by this latest application.
The really weird thing is nothing has changed when I check services, like @knightjoel mentioned. Even though EVERYTHING is now working properly in Orchestra, I still see the same messages when I check the Orchestra service status:
So... I don't know what is happening, exactly... other than everything is working again beautifully!
-
RE: Xen Orchestra from Sources unreachable after applying XCPng Patch updates
@john.c I am able to PING the VM hosting Orchestra with no issues.
-
RE: Xen Orchestra from Sources unreachable after applying XCPng Patch updates
@john.c Yeah, I'll probably have to suck it up and build a new one. However, it should be noted that I've in no way done any kind of odd customizations to Orchestra. When I installed it way back when I followed the explicit instructions right from the https://docs.xen-orchestra.com/installation#from-the-sources site and that was it. I think the instructions were slightly different back then, but I've never done anything other than what is in the instructions... I'm not "sophisticated" enough with Linux flavors to do any kind of tinkering on my own.
It may be a while till I get a chance to do a complete rebuild... but I'll update here once I've completed!
-
RE: Xen Orchestra from Sources unreachable after applying XCPng Patch updates
@john.c Yes, the xo-server.service is on the exact, same VM where Xen Orchestra is running. It's actually in the same folder: /xen-orchestra/packages/xo-server.
When I run systemctl for the sshd.service as you recommended, I get the following:
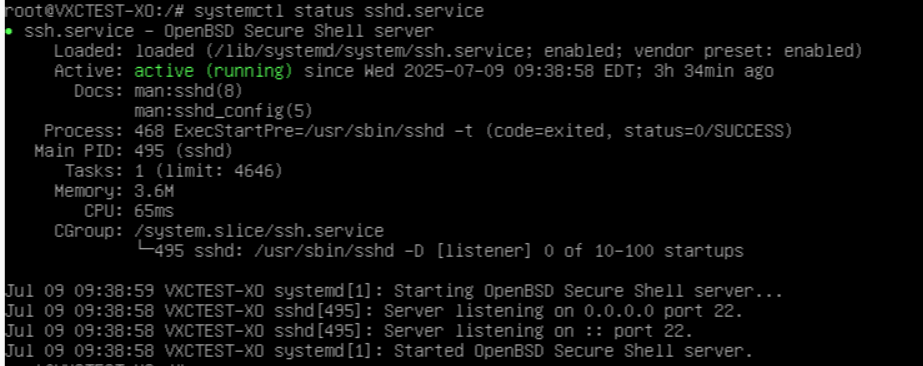
Here's what's really, really weird, however. I have a second demo system: completely separate hardware, installations, the works... this second demo system is almost identical to the demo system on which I am having the issue and this system is working just fine. When I go to the host VM for Orchestra on that server it has the same message that it can't find the xo-server.service! And yet, just to reiterate, that version of Orchestra is working just fine.
I'm almost wondering if the updated XCPng patches broke something, as the only difference between the two setups is I haven't updated the XCPng patches on the second set of hardware, yet.
-
RE: Xen Orchestra from Sources unreachable after applying XCPng Patch updates
@john.c How do I locate that specific path? And, this instance of Orchestra has been running flawlessly for almost two years now and nothing was changed other than applying the patches for XCPng.
Where do I look to make sure that the proper path is specified?
-
RE: Xen Orchestra from Sources unreachable after applying XCPng Patch updates
@Danp Thanks for getting back to me.
This is very odd. When I check to see if the Orchestra status is running, everything looks OK:
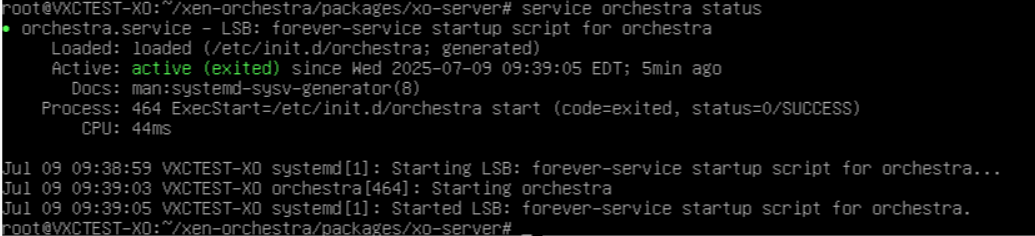
But when I try to run the command you sent over, I get an error message stating "Unit xo-server.service" could not be found". However, when I check in the very same folder from which I am running the command, I can see xo-server.service right there.

Not sure why it would do that. Any suggestions?
Thanks!
-
RE: Xen Orchestra from Sources unreachable after applying XCPng Patch updates
@Perplexed9828 It's installed on one of my two hosts, but I've tried moving it to the other host with no love.
It was installed following the specific directions on the https://docs.xen-orchestra.com/installation#from-the-sources site.
-
Xen Orchestra from Sources unreachable after applying XCPng Patch updates
Good afternoon!
It is currently July 8, 2025. I received the usual notification this morning that new patch updates were available for XCPng. I am currently running XCPng version 8.3.
Prior to updating the XCPng patches, I also made sure to update Xen Orchestra to the latest available commit; this would be the latest available commit as of 12:00 PM EST on July 8th. I would love to tell you the specific number, but the issue is after applying the latest XCPng patches and rebooting the physical hosts, I can no longer connect to Orchestra.
The Linux host for Xen Orchestra boots just fine, I can log on and everything seems OK. However, I don't think Xen Orchestra is running, as none of the automated tasks appear to be working, either.
Is there something in the new XCPng patches that prevents Xen from working? Do I need to make some changes to the Xen Orchestra configurations?
Thanks!
-
RE: All drop-down options are empty
@Andrew Interesting... up until this time we've never needed to completely rebuild XO every time a new Commit was released or a Node update was required. The existing installation just kept working. I hope this isn't something that is going to become standard as having to completely rebuild XO every time a new Commit is available would be a bit of a pain...