@bogikornel We had a very old XO built from sources, which worked fine. One day we decided to deploy a new VM and migrate to a new XO built from sources, and immediately ran into problems.
All tho it was resolved, after switching machines from HP to Cisco, which makes us believe it has something to do with the NIC, driver or firmware.
Posts
-
RE: Backup fails with "Body Timeout Error", "all targets have failed, step: writer.run()"
-
RE: Potential bug with Windows VM backup: "Body Timeout Error"
@poddingue My colleage managed to workaround the issue by re-installing the lab on other hardware, I think it is now Cisco UCS-servers. It was HP ProLiant-servers before.
Maybe it was an issue with some of the NIC or firmware, im not really sure, but it works now.
-
RE: Backups Fail with ENOENT: no such file or directory
Had major issues with backups a while ago, it was due to the firmware of the NIC in the physical server. We found out by moving our XO vm to another physical host and then error went away, moving it back made it come back.
-
RE: active volcano eruption going on here =)
@Pilow damn thats super scary! I hope everyone is OK.
-
RE: Potential bug with Windows VM backup: "Body Timeout Error"
@Pilow We tried that as well, same problem

Also tried with a VM on the same newtork, just another VLAN, and we're seeing the same thing. At first we figured it was because one of the xcp-ng's was on a remote site which is connected through an IPSEC VPN, but that wasn't the case.
-
RE: Potential bug with Windows VM backup: "Body Timeout Error"
@CodeMercenary alright, thanks for replying. I tried some more, but still getting the same error, on linux as well as windows vm's so im at lost here.
-
RE: Potential bug with Windows VM backup: "Body Timeout Error"
Did anyone try to patch xo and xcp-ng to the latest and did you have any luck with backups since then?
Im on XO (Xen Orchestra, commit 449e7 and Master, commit 2aff8) and the latest xcp-ng 8.3 with all patches installed and im still seeing the "Body timeout error" on 4/8 vm's: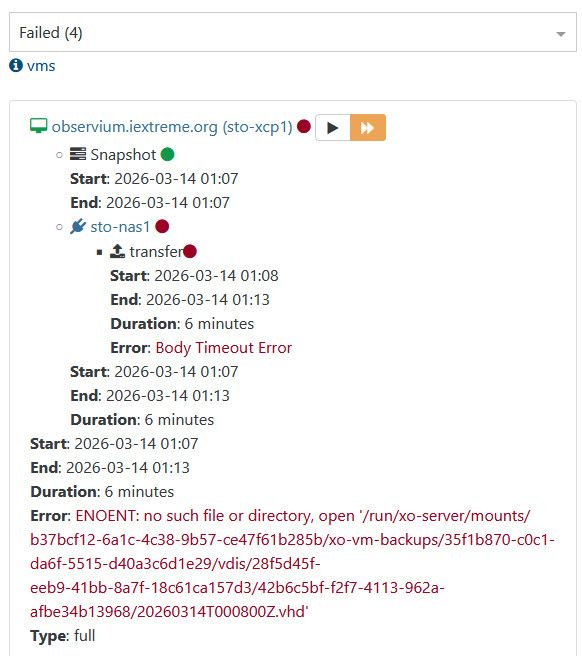
Some works tho:
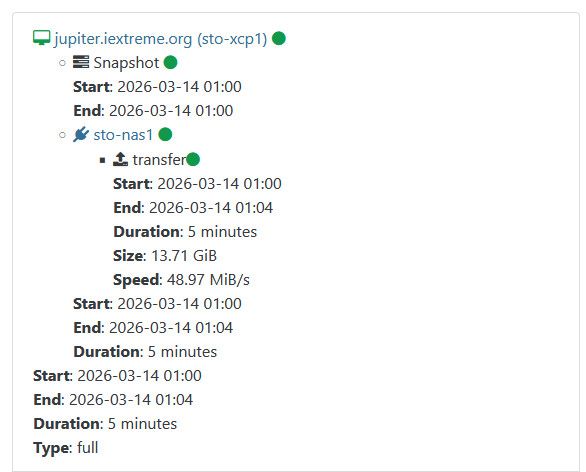
Observium has a 20Gb VDI with 15Gb used, jupiter has a 20Gb VDI with 12Gb used.
Let me know if you want any logs from my XO or XCP and I'll happily provide them. -
RE: Every virtual machine I restart doesn't boot.
@DustinB yeah im guessing the VDI isn't attached to the VM for some reason, based on the screenshot.
Im also wondering if he ever rebooted the VM's after installing them with PXE

-
RE: Every virtual machine I restart doesn't boot.
@ohthisis Go to the Disks tab of the VM, what does it look like?
-
Hosts fenced, new master, rebooted slaves not reconnecting to pool
I'm doing a bit of labbing this friday evening and I ran into a scenario I haven't encountered before and I just wanted to see if this is a bug or if im just being unlucky.
7st virtual xcp-ng 8.3 vm's running on a physical xcp-ng 8.3, all vm's have nested virtualization enabled.
I fired up some VM's in the pool to try the load balancer out, by running some "benchmark"-scripts within the vm's to create some load.
After a while 3/7 hosts failed, because of not enough ram (only 4gb per VM) which isn't really that strange, but after they failed they're not able to "connect" to the pool again: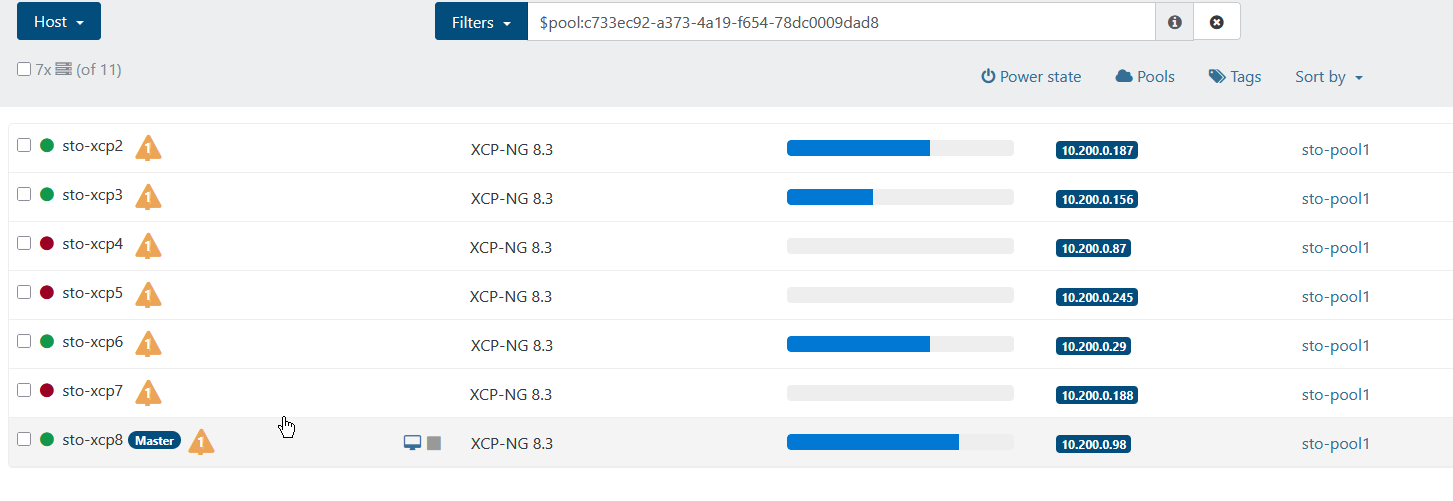
I then went to the sto-xcp7 vm and checked the pool.conf, only to see that it actually listed sto-xcp8 (which is the master after the fencing):
[17:48 sto-xcp7 ~]# cat /etc/xensource/pool.conf
slave:10.200.0.98[17:49 sto-xcp7 ~]#I can also go the host in XO and see that it's "halted" but yet, it displays the console:
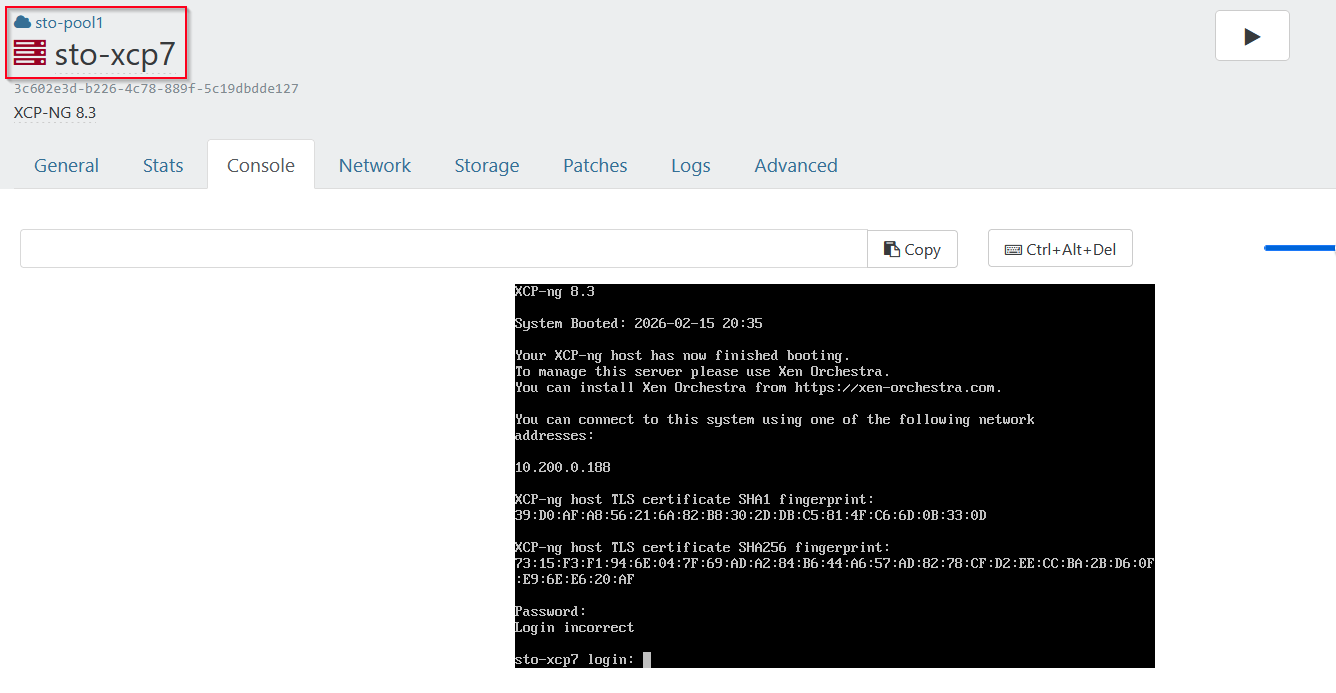
Just for a sanity check, I checked xcp-ng center as well, and it agrees with XO, that the hosts are offline:
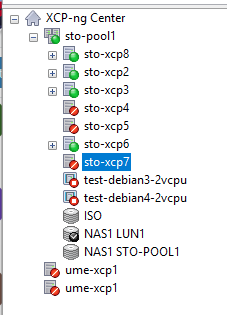
Is this a bug or what's actually going on? I tried rebooting the failed hosts, without any luck. Any pointers on where to look?
-
RE: Network Management lost, No Nic display Consol
@DustyArmstrong thats super-strange, i actually have the same setup at home, 2 hp z240 machines running xcp-ng in a small pool.
xcp1 is always up and running, xcp2 is powered down when I dont need it, everything important is running on xcp1, maybe that's the reason I don't run into these issues. -
RE: Network Management lost, No Nic display Consol
@DustyArmstrong said in Network Management lost, No Nic display Consol:
@nikade sorry to drag this up but, is there a particular process or methodology to avoid this in the first place? Just had it happen on two brand new hosts, I had to re-install XCP from scratch. Bit worried if I reboot one of them now for any reason this will happen again. It happened on both the pool master and the slave, network completely wiped out on both.
Genuinely one of the most bizarre series of events I've ever experienced with server infrastructure, I could not understand what was going on until I found this thread.
What exactly happend? Could you try and explain in 1-2-3 steps?
-
RE: Recommended DELL Hardware ?
I second all of @pilow points. We have been running a lot of Dell R630's with Intel CPU, Intel NIC, PERC H730i raid-cards and it has been flawless. Now we're using Dell R660's, but with newer spec's.
Tried Broadcom NIC's once, it worked, but had some weird performance issues from time to time.
Go with shared storage, NFS if possible (thin provisioning) and avoid XOSAN/XOSTOR, I don't think its battle-tested quite yet. -
RE: An error occurred while fetching the patches
@olivierlambert great news, I had a feeling this was in the works! Thanks for the info.
-
RE: An error occurred while fetching the patches
@Pilow Well yeah, it was indeed shown under TASK but man, there's a lot of tasks:
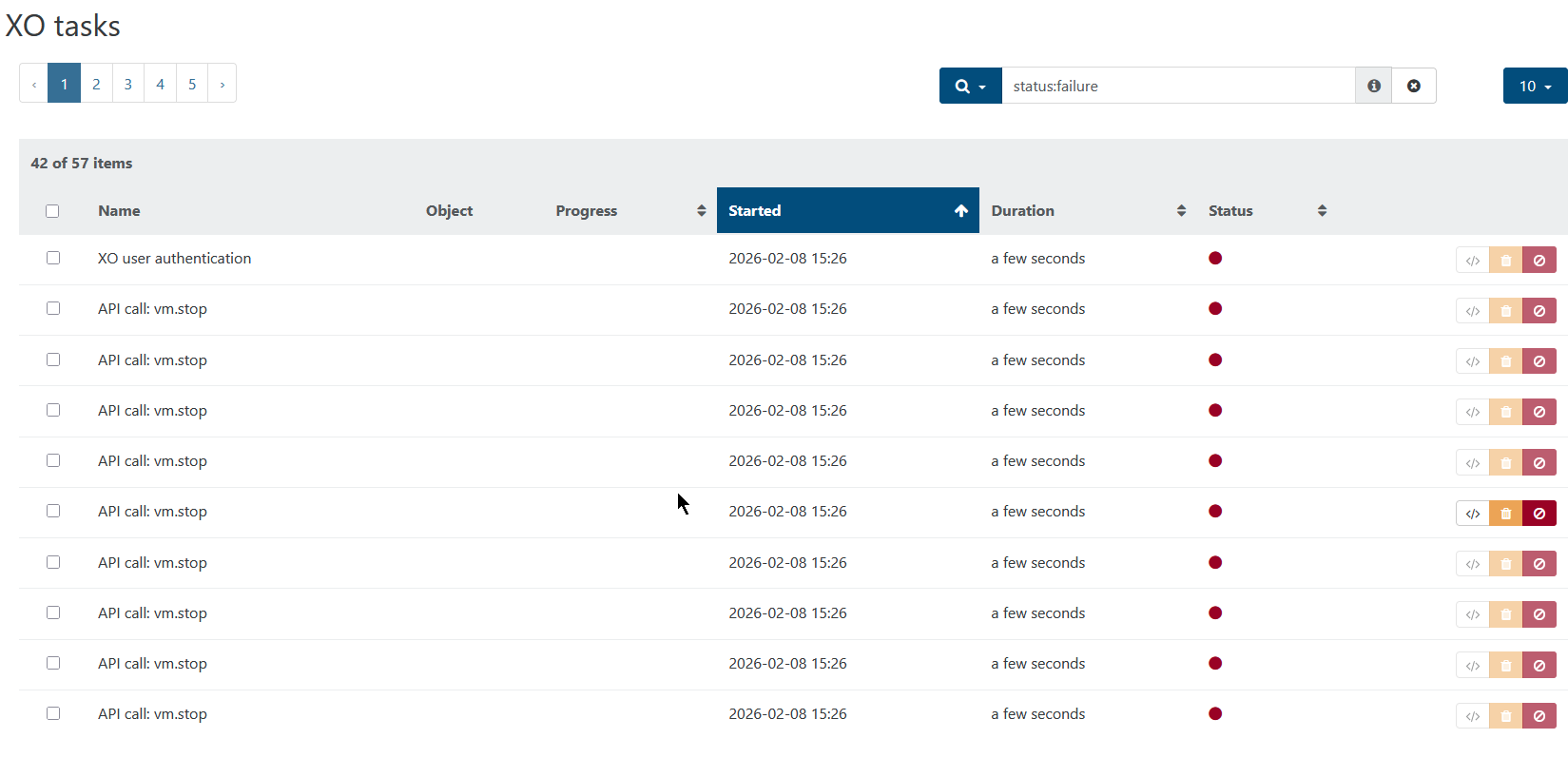
Some kind of status would be nice on the "update" tab of the vm, as well on the pool "update" tab.
-
An error occurred while fetching the patches
So im playing around with a test-pool i've recently setup to try and get my skillset up to date with xcp-ng and xo due to the latest Broadcom VMware changes to their partnerprogram.
I haven't been using xcp-ng a lot lately, pretty much only in my homelab as well as a colo machine that has basically been running on its own for quite some time.
I went to do what I always do when setting up a new xcp-ng machine, to the update tab and noticed there are 70+ updates in line. Nothing strange with that, this is a brand new installation, so I press the update button and after a while im seeing this:
An error occurred while fetching the patches. Please make sure the updater plugin is installed by running `yum install xcp-ng-updater` on the host.I didn't bother too much, maybe something just went wrong? I then went on to install the 2nd machine (Im setting up a POC of 8 xcp-ng hosts in total) and I did the same thing, just to see the exact same thing.
This time I went to the stats tab, just to notice that there is indeed some load on the machine, this lead me to ssh in to the host where I noticed that it is actually running yum to update: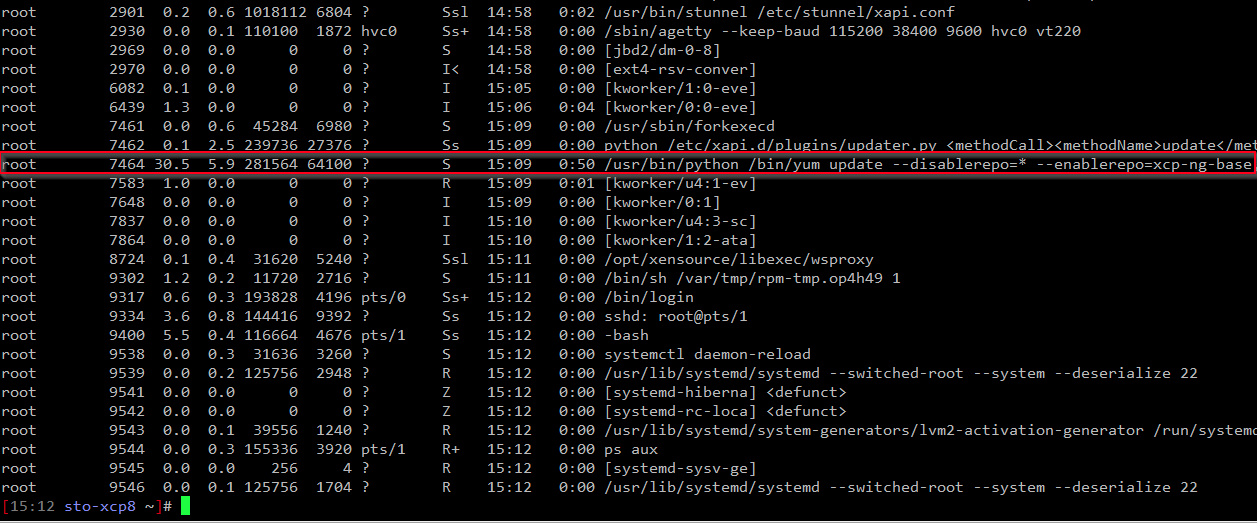
Is this per design? Why didn't it just tell me something like "Update in progress % done" or something like that? This makes it very hard to know whats actually going on, unless you ssh to the box and check ps.
-
RE: VM metadata import fail & stuck
@henri9813 Ahh alright, I understand now! Thanks for clarifying.
-
RE: VM metadata import fail & stuck
@henri9813 Maybe im now understaind the problem here? But a warm migration is a online migration, in other words a live migration without shutting the vm down and that is exactly how it should work.
-
RE: VM metadata import fail & stuck
@henri9813 Did you reboot the master after it was updated? If yes, I think you should be able to migrate back the VM's to the master, and then continue patcting the rest of the hosts.
")